Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 14.773 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878289
Direito Civil
Lucas, 15 anos, vive sob a guarda de sua avó Marta, pois seus pais foram declarados ausentes. Em um desentendimento na rua, Lucas arremessou uma pedra que quebrou a vitrine de uma loja e causou escoriações leves no atendente. O lojista ajuizou ação de indenização contra a avó e contra Lucas. Marta comprovou que possui renda mínima, suficiente apenas para custear a própria subsistência e a de Lucas.
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que Lucas:
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que Lucas:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878288
Direito Civil
A empresa Nexa celebrou com a startup Gama um contrato oneroso de prestação de serviços com cláusula de confidencialidade e cláusula de não divulgação do código-fonte, inclusive para membros da equipe. Paralelamente, a Nexa firmou com o engenheiro Rafael um comodato gratuito de um notebook para testes do produto da Gama. Um mês depois, a Gama publicou parte do código-fonte no repositório público da equipe, alegando que a cláusula era excessiva. Na mesma semana, Rafael, por descuido, deixou o notebook exposto em evento aberto e o equipamento foi danificado por terceiro. A Nexa ajuizou ações contra Gama e Rafael por inadimplemento de ambos os contratos.
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que o inadimplemento da Gama:
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que o inadimplemento da Gama:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878287
Direito Civil
Em 12/03/2025, Marcos firmou com Clara um contrato de cessão de direitos expectativos de herança, pelo qual Clara pagaria R$ 300.000,00 para adquirir, desde já, a futura participação hereditária de Marcos na herança ainda não aberta de seu tio vivo. O instrumento foi assinado por duas testemunhas e o pagamento foi iniciado no ato. Ao conversar com uma amiga sobre o contrato, Clara foi informada de que a lei civil dispõe que “não pode ser objeto de contrato a herança de pessoa viva”, sem determinar nenhuma sanção, surgindo a dúvida sobre a validade e os efeitos do contrato celebrado.
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que o contrato é:
Após a análise da situação hipotética e com base nas normas do Código Civil, é correto afirmar que o contrato é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878286
Direito Administrativo
O prefeito do Município Alfa, no Estado do Rio de Janeiro, pretende publicar edital de licitação visando à celebração de contrato administrativo com a entidade vencedora. Registre-se que o referido agente político demonstrou interesse na utilização, como modalidade de licitação, de regras combinadas do pregão e da concorrência.
Nesse cenário, considerando as disposições da Lei nº 14.133/2021, é correto afirmar que:
Nesse cenário, considerando as disposições da Lei nº 14.133/2021, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878284
Direito Administrativo
João, servidor público no âmbito do Tribunal de Justiça do Estado do Rio de Janeiro, está analisando determinado processo em que a autarquia estadual Alfa e a sociedade de economia mista Beta são partes.
Nesse cenário, considerando o entendimento doutrinário dominante, é correto afirmar que:
Nesse cenário, considerando o entendimento doutrinário dominante, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878283
Direito Administrativo
O prefeito do Município Sigma almeja contratar pessoa com expertise na área de gestão e governança digital, para dirigir um setor especificamente direcionado ao aprimoramento das atividades que demandam suporte tecnológico, de modo a aprimorar os serviços oferecidos à população. A exigência de um profissional qualificado para a direção do setor refletia uma necessidade permanente da Administração Pública.
Ao consultar sua assessoria jurídica em relação ao formato da referida contratação, o chefe do Poder Executivo municipal foi corretamente esclarecido de que:
Ao consultar sua assessoria jurídica em relação ao formato da referida contratação, o chefe do Poder Executivo municipal foi corretamente esclarecido de que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878282
Direito Constitucional
O secretário de Infraestrutura do Estado Beta, logo após ser empossado, solicitou que sua assessoria elaborasse edital de licitação com o objetivo de realizar a concessão do serviço local de gás canalizado, de modo a viabilizar a sua exploração por uma sociedade empresária. Essa forma de exploração, ao ver do secretário, tenderia a alcançar maiores níveis de eficiência, considerando a maior mobilidade do setor privado.
Considerando os balizamentos oferecidos pela narrativa e a sistemática constitucional, é correto afirmar que o referido serviço local:
Considerando os balizamentos oferecidos pela narrativa e a sistemática constitucional, é correto afirmar que o referido serviço local:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878280
Modelagem de Processos de Negócio (BPM)
Uma empresa de e-commerce está automatizando seu processo de liberação de pedidos de forma que se integre com os dados de estoque, pagamento e logística.
Após um estudo sobre o assunto, a equipe de automação identificou, como solução mais adequada para modelar fluxos, a necessidade de aplicar as regras de negócios e executar o monitoramento de indicadores em tempo real por meio de:
Após um estudo sobre o assunto, a equipe de automação identificou, como solução mais adequada para modelar fluxos, a necessidade de aplicar as regras de negócios e executar o monitoramento de indicadores em tempo real por meio de:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878279
Engenharia de Software
Uma empresa de logística está desenvolvendo um sistema de rastreamento de entregas e contratou uma consultoria para identificar possíveis melhorias. Para alinhar os requisitos entre os setores de TI, operações e atendimento ao cliente, a consultoria organizou uma reunião com representantes de cada área, atuando como facilitadora para esclarecer dúvidas e consolidar as necessidades do projeto.
Em seu relatório final, a consultoria descreveu a técnica utilizada como:
Em seu relatório final, a consultoria descreveu a técnica utilizada como:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878278
Administração Pública
Uma organização pública está atuando na sua transformação digital com relação à gestão de processos. De forma a melhorar a eficiência de seus fluxos de trabalho, decidiu-se implantar um Escritório de Processos.
Uma das responsabilidades consideradas pela organização pública foi:
Uma das responsabilidades consideradas pela organização pública foi:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878277
Administração de Recursos Materiais
Em uma empresa de desenvolvimento de aplicativos para celulares, a equipe de desenvolvimento está trabalhando em um novo aplicativo e faz uso de um quadro Kanban para visualizar o fluxo de trabalho. O responsável pela equipe de desenvolvimento notou que um dos cartões permanecia na coluna "em andamento" por vários dias sem nenhum progresso.
Em relação a essa situação, é correto afirmar que:
Em relação a essa situação, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878276
Governança de TI
A divisão de suporte do Tribunal de Justiça do Estado do Rio de Janeiro (TJRJ) identificou um aumento na quantidade de chamados relacionados com problemas com as impressoras. Após investigação do problema, a equipe identificou que os drivers estavam desatualizados. A equipe atualizou os drivers de todas as impressoras e monitorou os resultados.
Segundo o ITIL 4, tal ação está relacionada à prática de:
Segundo o ITIL 4, tal ação está relacionada à prática de:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878275
Modelagem de Processos de Negócio (BPM)
De acordo com o BPM CBOK 4.0, o desenho de processos é a criação de especificações para processos de negócio novos e modificados.
Os princípios do desenho de processos representam os principais conceitos envolvidos na maioria dos projetos de redesenho de processos.
O princípio do desenho de processo que orienta que se estude o fluxograma AS-IS do processo, para determinar exatamente onde as atividades de agregação de valor são executadas, é o seguinte:
Os princípios do desenho de processos representam os principais conceitos envolvidos na maioria dos projetos de redesenho de processos.
O princípio do desenho de processo que orienta que se estude o fluxograma AS-IS do processo, para determinar exatamente onde as atividades de agregação de valor são executadas, é o seguinte:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878274
Modelagem de Processos de Negócio (BPM)
O BPM CBOK descreve um conjunto de funções fundamentais para garantir a governança, arquitetura, análise, desenho, implementação e melhoria dos processos.
Quem estabelece uma direção estratégica e desenvolve a visão, missão e os valores essenciais da organização é o:
Quem estabelece uma direção estratégica e desenvolve a visão, missão e os valores essenciais da organização é o:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878273
Modelagem de Processos de Negócio (BPM)
O Gerenciamento de Processos de Negócio requer medidas, métricas e indicadores de desempenho que permitam monitorar os processos de forma que atendam às suas metas.
De acordo com o BPM CBOK 4.0, é correto afirmar que a métrica do:
De acordo com o BPM CBOK 4.0, é correto afirmar que a métrica do:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878272
Modelagem de Processos de Negócio (BPM)
O Gerenciamento de Processos de Negócio (BPM) propicia a implantação de melhorias em processos e seu gerenciamento, a fim de se obterem benefícios relacionados, dentre os quais a elevação da qualidade dos serviços prestados pelo Poder Judiciário.
De acordo com o CBOK 4.0, o ciclo de Gerenciamento de Processos de Negócio é composto por etapas que, a depender da demanda, podem ser suprimidas ou executadas individualmente. A avaliação de como os processos de negócio estão operando para, a partir do entendimento comum de seu estado atual, identificar possíveis melhorias para atender aos objetivos do negócio com efetividade ocorre no(a):
De acordo com o CBOK 4.0, o ciclo de Gerenciamento de Processos de Negócio é composto por etapas que, a depender da demanda, podem ser suprimidas ou executadas individualmente. A avaliação de como os processos de negócio estão operando para, a partir do entendimento comum de seu estado atual, identificar possíveis melhorias para atender aos objetivos do negócio com efetividade ocorre no(a):
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878271
Noções de Informática
Observe o seguinte conjunto de dados.
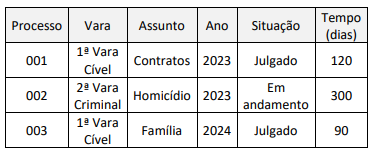
Para analisar a situação dos processos por vara, utilizando o Excel, as configurações de linhas, colunas e valores da tabela dinâmica devem, respectivamente, ser:
Para analisar a situação dos processos por vara, utilizando o Excel, as configurações de linhas, colunas e valores da tabela dinâmica devem, respectivamente, ser:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878270
Banco de Dados
Luiz está analisando dados em uma ferramanta de BI que permite visualizar e editar o SQL utilizado na consulta ao banco de dados. Uma das análises usa o seguinte SQL:
SELECT v.nome_vara, COUNT(*) AS total_processos FROM FatoProcessos f JOIN DimVara v ON f.id_vara = v.id_vara GROUP BY v.nome_vara;
Para listar o resultado da consulta, começando pelas varas com mais processos, Luiz deve editar o SQL incluindo a cláusula:
SELECT v.nome_vara, COUNT(*) AS total_processos FROM FatoProcessos f JOIN DimVara v ON f.id_vara = v.id_vara GROUP BY v.nome_vara;
Para listar o resultado da consulta, começando pelas varas com mais processos, Luiz deve editar o SQL incluindo a cláusula:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878269
Banco de Dados
O TJRJ adquiriu uma ferramenta de BI que executa operações OLAP para apoiar as análises sobre gestão de processos judiciais. Para alternar a visualização de Processos por Assunto e Ano para Processos por Ano e Assunto, facilitando comparações e gerando diferentes perspectivas para analistas, deve-se utilizar a operação:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878268
Modelagem de Processos de Negócio (BPM)
A analista de negócios Manuela está modelando os processos do seu departamento, que é intensivo em atividades com entrada e saída de dados.
De acordo com o BPMN, a representação do fluxo de mensagem entre uma Tarefa e um Objeto de Dados que Manuela deve utilizar é:
De acordo com o BPMN, a representação do fluxo de mensagem entre uma Tarefa e um Objeto de Dados que Manuela deve utilizar é: