Questões de Concurso
Para analista judiciário
Foram encontradas 14.773 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181567
Direito Penal
Matheus, servidor público no âmbito do Poder Executivo do
Estado Alfa, abandonou, dolosamente, o cargo público por ele
ocupado, sem qualquer justificativa e fora dos casos permitidos
em lei. Registre-se, contudo, que a conduta de Matheus não
gerou prejuízo ao poder público.
Nesse cenário, considerando as disposições do Código Penal, é correto afirmar que Matheus:
Nesse cenário, considerando as disposições do Código Penal, é correto afirmar que Matheus:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181566
Engenharia de Software
O Modelo de Requisitos para Sistemas Informatizados de Gestão
de Processos e Documentos do Poder Judiciário (MoReq-Jus),
aprovado pela Resolução CNJ nº 522/2023, explicita que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181565
Direito Administrativo
O prefeito do Município Alfa, no Estado do Rio de Janeiro,
pretende publicar edital de licitação visando à celebração de
contrato administrativo com a entidade vencedora. Registre-se
que o referido agente político demonstrou interesse na
utilização, como modalidade de licitação, de regras combinadas
do pregão e da concorrência.
Nesse cenário, considerando as disposições da Lei nº 14.133/2021, é correto afirmar que:
Nesse cenário, considerando as disposições da Lei nº 14.133/2021, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181564
Direito Constitucional
Matheus, servidor público no Tribunal de Justiça do Estado do Rio
de Janeiro, tomou conhecimento de que a sociedade empresária
Alfa impetrou, em juízo, mandado de segurança coletivo, com o
objetivo de proteger o direito líquido e certo dos seus acionistas.
Nesse cenário, considerando as disposições da Constituição Federal, é correto afirmar que a sociedade empresária Alfa agiu de forma:
Nesse cenário, considerando as disposições da Constituição Federal, é correto afirmar que a sociedade empresária Alfa agiu de forma:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181563
Direito Administrativo
João, servidor público no âmbito do Tribunal de Justiça do Estado
do Rio de Janeiro, está analisando determinado processo em que
a autarquia estadual Alfa e a sociedade de economia mista Beta
são partes.
Nesse cenário, considerando o entendimento doutrinário dominante, é correto afirmar que:
Nesse cenário, considerando o entendimento doutrinário dominante, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181562
Direito Constitucional
O prefeito do Município Sigma almeja contratar pessoa com
expertise na área de gestão e governança digital, para dirigir um
setor especificamente direcionado ao aprimoramento das
atividades que demandam suporte tecnológico, de modo a
aprimorar os serviços oferecidos à população. A exigência de um
profissional qualificado para a direção do setor refletia uma
necessidade permanente da Administração Pública.
Ao consultar sua assessoria jurídica em relação ao formato da referida contratação, o chefe do Poder Executivo municipal foi corretamente esclarecido de que:
Ao consultar sua assessoria jurídica em relação ao formato da referida contratação, o chefe do Poder Executivo municipal foi corretamente esclarecido de que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181561
Direito Constitucional
O secretário de Infraestrutura do Estado Beta, logo após ser
empossado, solicitou que sua assessoria elaborasse edital de
licitação com o objetivo de realizar a concessão do serviço local
de gás canalizado, de modo a viabilizar a sua exploração por uma
sociedade empresária. Essa forma de exploração, ao ver do
secretário, tenderia a alcançar maiores níveis de eficiência,
considerando a maior mobilidade do setor privado.
Considerando os balizamentos oferecidos pela narrativa e a sistemática constitucional, é correto afirmar que o referido serviço local:
Considerando os balizamentos oferecidos pela narrativa e a sistemática constitucional, é correto afirmar que o referido serviço local:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181560
Direito Constitucional
João e Maria tiveram um embate argumentativo, considerando
as ideias que prestigiavam. João, valendo-se de sua liberdade de
expressão, teria feito comentários que Maria entendia serem
prejudiciais à sua imagem no ambiente sociopolítico e, em último
nível, ao seu direito à honra. Por tal razão, Maria ajuizou ação de
reparação de danos morais em face de João.
O juiz de direito, ao julgar a causa, observou corretamente que:
O juiz de direito, ao julgar a causa, observou corretamente que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181559
Direito Digital
A analista Carla deve anonimizar um conjunto de dados pessoais,
observando o disposto na LGPD (Lei nº 13.709/2018). Os dados
não serão usados para formação de perfis comportamentais e
Carla não reverterá a anonimização, após feita. A analista sabe
que, se determinadas condições não forem atendidas, os dados
anonimizados ainda poderão ser considerados como pessoais, à
luz da LGPD.
A fim de que os dados anonimizados não venham a ser considerados pessoais, Carla deve garantir que:
A fim de que os dados anonimizados não venham a ser considerados pessoais, Carla deve garantir que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181558
Direito Digital
A empresa Beta implementa políticas de ciclo de vida de dados
na sua organização; contudo, ainda possui algumas atividades as
quais não estão em conformidade com a LGPD (Lei Geral de
Proteção de Dados). A empresa já definiu regras para a
classificação, retenção e descarte seguro dos registros
administrativos, exceto para a fase de arquivamento.
Para garantir que a empresa Beta esteja em conformidade com a LGPD para a fase de arquivamento, esta deverá garantir:
Para garantir que a empresa Beta esteja em conformidade com a LGPD para a fase de arquivamento, esta deverá garantir:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181557
Segurança da Informação
Durante a implantação de um sistema de gestão hospitalar em
uma rede pública de saúde, a equipe de segurança da informação
optou por autorizar o acesso do usuário final com base na sua
função predefinida para proteger os dados clínicos dos pacientes.
O sistema possui múltiplos perfis de usuários, como médicos,
enfermeiros, administradores, técnicos de laboratório e
auditores. Cada perfil requer acesso a diferentes conjuntos de
dados e funcionalidades.
Considerando os desafios de governança e segurança de dados, é correto afirmar que a implementação do RBAC (controle de acesso baseado em função):
Considerando os desafios de governança e segurança de dados, é correto afirmar que a implementação do RBAC (controle de acesso baseado em função):
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181556
Governança de TI
Ana é a CEO (Chief Executive Officer) de uma empresa de
e-commerce e determinou uma reunião para a elaboração do
planejamento estratégico anual. Nessa reunião, foi decidido que
seriam adotadas práticas de FinOps (Financial Cloud Operations)
para alinhar os custos dos serviços de nuvem com os objetivos de
negócio.
Com o passar do tempo, Ana tem notado que essa estratégia trouxe como benefício:
Com o passar do tempo, Ana tem notado que essa estratégia trouxe como benefício:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181555
Segurança da Informação
Durante a implantação de uma infraestrutura em nuvem via
Terraform, uma equipe de DevOps percebe que credenciais
sensíveis estão expostas em arquivos .tf versionados no GitHub.
Após essa identificação, a equipe precisará ocultar as credenciais
sensíveis para evitar a sua exposição.
Para que a equipe de DevOps consiga cumprir esse item, a ação a ser tomada, dentro das melhores práticas, deverá ser a de:
Para que a equipe de DevOps consiga cumprir esse item, a ação a ser tomada, dentro das melhores práticas, deverá ser a de:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181554
Direito Digital
Uma empresa pública de saneamento contratou uma auditoria
externa para adequação à Lei Geral de Proteção de Dados (LGPD).
A auditoria identificou que havia dados pessoais de clientes
inativos em sistemas legados e sem utilização armazenados há
mais de 10 anos.
A auditoria externa, em seu relatório, informou que, para garantir a conformidade com a LGPD, a empresa pública de saneamento deverá:
A auditoria externa, em seu relatório, informou que, para garantir a conformidade com a LGPD, a empresa pública de saneamento deverá:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181553
Direito Digital
Uma universidade pública foi solicitada a enviar dados
estatísticos sobre o desempenho acadêmico dos seus alunos para
um instituto de pesquisa. Contudo, precisa garantir que não
exista nesses dados nenhuma informação sensível, de forma que
seja removida a possibilidade de associação, direta ou indireta, a
um indivíduo.
Para atender aos requisitos da LGPD e proteger a privacidade dos estudantes, a universidade deverá:
Para atender aos requisitos da LGPD e proteger a privacidade dos estudantes, a universidade deverá:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181552
Direito Digital
O TJRJ está desenvolvendo um sistema cujas operações
envolverão o tratamento de dados pessoais. A fim de garantir a
conformidade com a Lei nº 13.709/2018, o módulo B do sistema
deve observar especificamente o princípio da LGPD que assegura
que o tratamento seja compatível com os fins informados ao
titular, de acordo com o contexto do tratamento.
O princípio da LGPD especificamente observado pelo módulo B é o da:
O princípio da LGPD especificamente observado pelo módulo B é o da:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181549
Sistemas Operacionais
O sistema operacional Moderno implementa a alocação de
memória virtual baseada em paginação, combinando técnicas e
estruturas de dados encontrados em outros sistemas
operacionais. A tabela de páginas de memória do Moderno foi
implementada nos mesmos moldes do Linux.
Sendo assim, é correto afirmar que a tabela de páginas de memória do Moderno:
Sendo assim, é correto afirmar que a tabela de páginas de memória do Moderno:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181548
Matemática
Um tribunal deseja prever o tempo de tramitação (em dias) de
processos de uma determinada classe, desde a distribuição até a
sentença em 1ª instância. Um cientista de dados ajustou um
modelo de regressão usando variáveis como tipo de ação, vara,
quantidade de partes e histórico de movimentações, e avaliou o
modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
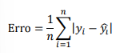
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”.
A métrica utilizada pelo cientista de dados é:
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”.
A métrica utilizada pelo cientista de dados é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181546
Sistemas de Informação
Uma empresa de e-commerce implantou um modelo de machine
learning para prever a probabilidade de churn, métrica que indica
a rotatividade ou evasão de clientes. Após seis meses em
produção, a equipe de dados observou que, embora as
distribuições estatísticas das features de entrada permanecessem
estáveis (mesmas médias, mesmos desvios-padrão e mesmas
distribuições), o relacionamento entre essas features e a
variável-alvo (churn) havia mudado significativamente devido a
alterações no comportamento dos consumidores causadas por
novas políticas de fidelização da empresa.
Diante desse cenário, é correto afirmar que o modelo:
Diante desse cenário, é correto afirmar que o modelo:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Engenheiro de Dados |
Q4181545
Engenharia de Software
O desempenho de modelos de aprendizado de máquina está
intrinsecamente relacionado ao equilíbrio entre viés e variância.
Modelos com alto viés tendem a simplificar excessivamente o
problema, resultando em subajuste (underfitting), enquanto
modelos com alta variância podem capturar ruído nos dados de
treinamento, levando ao sobreajuste (overfitting). Para mitigar
esses problemas, diversas técnicas de regularização podem ser
empregadas, ajustando a complexidade do modelo e melhorando
sua capacidade de generalização.
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que: