Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 191.597 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Negócios |
Q3878260
Arquitetura de Software
O TJRJ hospeda a aplicação web Consulta+ em uma instância de
computação, na nuvem pública. A equipe de analistas do tribunal
precisa escalar a capacidade de atendimento da aplicação, que
atualmente suporta 5.000 requisições por minuto, para ao menos
12.000 requisições por minuto. A equipe deve decidir entre
adicionar recursos à instância atual, que passaria a suportar mais
14.000 requisições por minuto, por R$ 5.000,00 a mais, ou
adicionar novas instâncias, cada uma suportando 3.000
requisições por minuto, por R$ 1.050,00 cada uma. A escolha dos
analistas deve ser aquela de melhor custo-benefício.
Para aumentar a capacidade de Consulta+, os analistas do TJRJ devem optar pela escalabilidade:
Para aumentar a capacidade de Consulta+, os analistas do TJRJ devem optar pela escalabilidade:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874768
Engenharia de Software
O Modelo de Requisitos para Sistemas Informatizados de Gestão de Processos e Documentos do Poder Judiciário (MoReq-Jus), aprovado pela Resolução CNJ nº 522/2023, explicita que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874761
Direito Digital
Sistemas de Inteligência Artificial (IA) Generativa apresentam como características fundamentais: necessidade de grandes volumes de dados para seu treinamento; capacidade de inferência que permite a geração de novos dados semelhantes aos dados de treinamento; e adoção de um conjunto diversificado de técnicas computacionais.
Considerando a conformidade com a Lei Geral de Proteção de Dados Pessoais e as diretrizes de IA responsável e explicável, é correto afirmar que:
Considerando a conformidade com a Lei Geral de Proteção de Dados Pessoais e as diretrizes de IA responsável e explicável, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874760
Engenharia de Software
A Lei Geral de Proteção de Dados Pessoais (LGPD) tem como objetivo proteger os direitos fundamentais de privacidade, liberdade e o livre desenvolvimento da personalidade, ao mesmo tempo em que tem por fundamento o desenvolvimento econômico e tecnológico e a inovação. Portanto, a inovação tecnológica deve estar em harmonia com a proteção de dados pessoais.
A LGPD estabelece que o controlador deverá fornecer informações claras e adequadas a respeito dos critérios e dos procedimentos utilizados para a decisão automatizada, observados os segredos comercial e industrial.
Esse preceito da LGPD está relacionado à explicabilidade na inteligência artificial (IA), que se refere:
A LGPD estabelece que o controlador deverá fornecer informações claras e adequadas a respeito dos critérios e dos procedimentos utilizados para a decisão automatizada, observados os segredos comercial e industrial.
Esse preceito da LGPD está relacionado à explicabilidade na inteligência artificial (IA), que se refere:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874759
Gerência de Projetos
O Assistente de Inteligência Artificial Generativa (ASSIS) é um assistente jurídico desenvolvido para apoiar magistrados na elaboração de decisões e minutas de sentenças para processos judiciais de 1ª instância.
Utilizando modelos de linguagem generativa, o assistente é capaz de gerar automaticamente minutas de decisões e sentenças, além de responder perguntas relacionadas ao conteúdo dos processos.
Além disso, a tecnologia empregada poderá evoluir com o tempo, incorporando novos conhecimentos e tendências do direito.
No cenário descrito, o princípio do PMBOK 7ª edição que se destaca como aplicável é:
Utilizando modelos de linguagem generativa, o assistente é capaz de gerar automaticamente minutas de decisões e sentenças, além de responder perguntas relacionadas ao conteúdo dos processos.
Além disso, a tecnologia empregada poderá evoluir com o tempo, incorporando novos conhecimentos e tendências do direito.
No cenário descrito, o princípio do PMBOK 7ª edição que se destaca como aplicável é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874758
Governança de TI
O ciclo de vida de sistemas de inteligência artificial (IA) descreve a evolução e etapas de um sistema de IA, desde o início de seu desenvolvimento até a sua desativação.
A atividade de processar dados é iniciada na fase anterior ao treinamento do modelo, ou seja, durante a formação da base de dados de treinamento e teste, e percorre o ciclo de vida dos sistemas de IA.
Considerando as práticas de gerenciamento de serviços do ITIL 4, a que se alinha diretamente à atividade de processar dados é o gerenciamento de:
A atividade de processar dados é iniciada na fase anterior ao treinamento do modelo, ou seja, durante a formação da base de dados de treinamento e teste, e percorre o ciclo de vida dos sistemas de IA.
Considerando as práticas de gerenciamento de serviços do ITIL 4, a que se alinha diretamente à atividade de processar dados é o gerenciamento de:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874757
Governança de TI
O sistema de inteligência artificial (IA) é um sistema baseado em máquina que, para objetivos explícitos ou implícitos, infere, a partir das entradas que recebe, como gerar saídas tais como predição, conteúdo, recomendações ou decisões que podem influenciar ambientes físicos ou virtuais.
Aplicam-se os princípios do COBIT® 2019 na governança de sistemas de IA quando:
Aplicam-se os princípios do COBIT® 2019 na governança de sistemas de IA quando:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874756
Direito Digital
O TJRJ está desenvolvendo um sistema cujas operações envolverão o tratamento de dados pessoais. A fim de garantir a conformidade com a Lei nº 13.709/2018, o módulo B do sistema deve observar especificamente o princípio da LGPD que assegura que o tratamento seja compatível com os fins informados ao titular, de acordo com o contexto do tratamento.
O princípio da LGPD especificamente observado pelo módulo B é o da:
O princípio da LGPD especificamente observado pelo módulo B é o da:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874755
Gerência de Projetos
A empresa Y está desenvolvendo uma plataforma de e-commerce para uma empresa de vendas online. Com base nos testes de usabilidade e feedback do usuário, a equipe de desenvolvimento decidiu efetuar alterações nas funcionalidades, sendo que algumas delas resultariam em mudanças no escopo original.
Ao levar esse fato ao gerente de projetos, a equipe usou o PMBOK para justificar as alterações com base no princípio do(a):
Ao levar esse fato ao gerente de projetos, a equipe usou o PMBOK para justificar as alterações com base no princípio do(a):
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874754
Engenharia de Software
O departamento de TI de uma escola está desenvolvendo um Sistema de Gestão Escolar usando a metodologia ágil. Depois de definido 90% do escopo do projeto, o diretor da escola solicitou uma mudança significativa no escopo com a alegação de que a nova funcionalidade tinha se tornado prioridade.
A equipe ágil deve lidar com essa demanda:
A equipe ágil deve lidar com essa demanda:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874752
Engenharia de Software
Um órgão de controle estuda implantar uma plataforma avançada baseada em grandes modelos de linguagem para apoiar a análise de documentos, a consulta a bases normativas e a execução de fluxos complexos (por exemplo, checagem automática em diários oficiais, sistemas internos e bases abertas). A arquitetura em estudo combina LLMs, geração aumentada por recuperação (RAG), agentes de IA com uso de ferramentas externas e mecanismos de monitoramento para riscos éticos e de segurança.
Com base em conceitos de transformers e LLMs, RAG, agentificação, engenharia de prompts, bem como ética e segurança em IA, analise as afirmativas a seguir.
I. Em uma arquitetura com RAG, o LLM é utilizado principalmente como gerador condicionado a evidências: os documentos relevantes são buscados por similaridade de embeddings em um índice vetorial e incorporados ao contexto de entrada, de modo que decisões sobre fragmentação (tamanho dos trechos, sobreposição, estratégia de indexação) influenciam diretamente tanto a recuperação quanto a qualidade e a fundamentação das respostas.
II. Em arquiteturas que combinam LLMs com RAG, o risco de exposição indevida de dados sensíveis tende a ser intrinsecamente menor do que no uso direto de LLMs, porque os documentos sigilosos não precisam ser indexados: o modelo passa a depender principalmente de representações paramétricas já aprendidas no pré-treinamento, reduzindo a necessidade de controles específicos sobre o ciclo de vida dos dados no índice vetorial.
III. Técnicas de alinhamento com preferências humanas, como Reinforcement Learning e variantes de preference optimization, são frequentemente combinadas com boas práticas de engenharia de prompts (zero-shot, few-shot, encadeamento de pensamento) e com avaliações sistemáticas de prompts e saídas, pois, mesmo após o alinhamento, permanecem desafios como viés algorítmico, suscetibilidade a jailbreaks e prompt injection, exigindo camadas adicionais de governança, monitoramento e auditoria.
Está correto o que se afirma em:
Com base em conceitos de transformers e LLMs, RAG, agentificação, engenharia de prompts, bem como ética e segurança em IA, analise as afirmativas a seguir.
I. Em uma arquitetura com RAG, o LLM é utilizado principalmente como gerador condicionado a evidências: os documentos relevantes são buscados por similaridade de embeddings em um índice vetorial e incorporados ao contexto de entrada, de modo que decisões sobre fragmentação (tamanho dos trechos, sobreposição, estratégia de indexação) influenciam diretamente tanto a recuperação quanto a qualidade e a fundamentação das respostas.
II. Em arquiteturas que combinam LLMs com RAG, o risco de exposição indevida de dados sensíveis tende a ser intrinsecamente menor do que no uso direto de LLMs, porque os documentos sigilosos não precisam ser indexados: o modelo passa a depender principalmente de representações paramétricas já aprendidas no pré-treinamento, reduzindo a necessidade de controles específicos sobre o ciclo de vida dos dados no índice vetorial.
III. Técnicas de alinhamento com preferências humanas, como Reinforcement Learning e variantes de preference optimization, são frequentemente combinadas com boas práticas de engenharia de prompts (zero-shot, few-shot, encadeamento de pensamento) e com avaliações sistemáticas de prompts e saídas, pois, mesmo após o alinhamento, permanecem desafios como viés algorítmico, suscetibilidade a jailbreaks e prompt injection, exigindo camadas adicionais de governança, monitoramento e auditoria.
Está correto o que se afirma em:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874751
Ciência e Tecnologia
No contexto de redes convolucionais (CNN) aplicadas à visão computacional, as camadas de convolução têm como função:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874750
Engenharia de Software
Uma equipe está analisando o comportamento de um neurônio em uma rede neural binária já treinada. Para um determinado neurônio da camada de saída, mediu-se o valor da combinação linear z (antes da ativação) e o valor de saída a (após a ativação), obtendo-se os seguintes pares aproximados:
• Para z = 0, observou-se a ≈ 0,5;
• Para z = ln (3), observou-se a ≈ 0,75;
• Para z = −ln (3), observou-se a ≈ 0,25.
Admita que o neurônio utiliza uma única função de ativação escalar a = f(z), aplicada a todos os valores de z, e que as aproximações numéricas acima são consideradas exatas para fins de análise.
Nessa situação, conclui-se que a função de ativação compatível com os dados observados é:
• Para z = 0, observou-se a ≈ 0,5;
• Para z = ln (3), observou-se a ≈ 0,75;
• Para z = −ln (3), observou-se a ≈ 0,25.
Admita que o neurônio utiliza uma única função de ativação escalar a = f(z), aplicada a todos os valores de z, e que as aproximações numéricas acima são consideradas exatas para fins de análise.
Nessa situação, conclui-se que a função de ativação compatível com os dados observados é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874749
Estatística
Uma equipe de análise de risco de um tribunal implanta modelos de classificação para identificar processos com alta probabilidade de resultado desfavorável para a administração, trabalhando com bases historicamente desbalanceadas (poucos casos críticos em relação aos não críticos). Na fase de avaliação, discute-se o uso de validação cruzada, métricas baseadas em limiar de decisão e curvas de desempenho.
Com base nas boas práticas de avaliação de modelos de aprendizado de máquina, inclusive em cenários com classes desbalanceadas, analise as afirmativas a seguir, considerando (V) para a(s) afirmativa(s) verdadeira(s) e (F) para a(s) falsa(s).
( ) Na validação cruzada k-fold estratificada, cada partição de treino e teste preserva aproximadamente a mesma proporção de classes do conjunto original, o que contribui para estimativas de desempenho mais estáveis em problemas com desbalanceamento de classes.
( ) Curvas ROC e a métrica AUC-ROC são tipicamente mais informativas do que curvas precision-recall em cenários com classes fortemente desbalanceadas, justamente porque destacam com maior sensibilidade o comportamento do classificador em relação à classe minoritária.
( ) A métrica F1-score corresponde ao dobro do produto entre precisão (precision) e sensibilidade (recall) dividido pela soma de ambos, de modo que valores muito discrepantes entre precisão e recall tendem a produzir um F1-score relativamente baixo.
( ) Ao diminuir o limiar de decisão de um classificador binário (por exemplo, de 0,7 para 0,3), a precisão tende a aumentar, pois mais exemplos positivos são corretamente identificados como tal, ainda que isso geralmente ocorra às custas de uma redução no recall.
A sequência correta é:
Com base nas boas práticas de avaliação de modelos de aprendizado de máquina, inclusive em cenários com classes desbalanceadas, analise as afirmativas a seguir, considerando (V) para a(s) afirmativa(s) verdadeira(s) e (F) para a(s) falsa(s).
( ) Na validação cruzada k-fold estratificada, cada partição de treino e teste preserva aproximadamente a mesma proporção de classes do conjunto original, o que contribui para estimativas de desempenho mais estáveis em problemas com desbalanceamento de classes.
( ) Curvas ROC e a métrica AUC-ROC são tipicamente mais informativas do que curvas precision-recall em cenários com classes fortemente desbalanceadas, justamente porque destacam com maior sensibilidade o comportamento do classificador em relação à classe minoritária.
( ) A métrica F1-score corresponde ao dobro do produto entre precisão (precision) e sensibilidade (recall) dividido pela soma de ambos, de modo que valores muito discrepantes entre precisão e recall tendem a produzir um F1-score relativamente baixo.
( ) Ao diminuir o limiar de decisão de um classificador binário (por exemplo, de 0,7 para 0,3), a precisão tende a aumentar, pois mais exemplos positivos são corretamente identificados como tal, ainda que isso geralmente ocorra às custas de uma redução no recall.
A sequência correta é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874748
Engenharia de Software
No contexto dos principais paradigmas de aprendizado de máquina, relacione os tipos de aprendizado a seguir com as técnicas correspondentes.
1. Aprendizado supervisionado
2. Aprendizado não supervisionado
3. Aprendizado semisupervisionado
( ) Uso de algoritmos de clustering como k-means ou clustering hierárquico para agrupar observações com base em medidas de similaridade, sem rótulos de saída.
( ) Emprego de algoritmos de propagação de rótulos (label propagation ou label spreading), combinando um pequeno conjunto de exemplos rotulados com um grande volume de dados não rotulados para melhorar a generalização.
( ) Utilização de k-vizinhos mais próximos (k-NN) para classificar exemplos, tomando como referência os rótulos dos vizinhos mais próximos no conjunto de treino.
A sequência correta é:
1. Aprendizado supervisionado
2. Aprendizado não supervisionado
3. Aprendizado semisupervisionado
( ) Uso de algoritmos de clustering como k-means ou clustering hierárquico para agrupar observações com base em medidas de similaridade, sem rótulos de saída.
( ) Emprego de algoritmos de propagação de rótulos (label propagation ou label spreading), combinando um pequeno conjunto de exemplos rotulados com um grande volume de dados não rotulados para melhorar a generalização.
( ) Utilização de k-vizinhos mais próximos (k-NN) para classificar exemplos, tomando como referência os rótulos dos vizinhos mais próximos no conjunto de treino.
A sequência correta é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874747
Estatística
Um tribunal deseja prever o tempo de tramitação (em dias) de processos de uma determinada classe, desde a distribuição até a sentença em 1ª instância. Um cientista de dados ajustou um modelo de regressão usando variáveis como tipo de ação, vara, quantidade de partes e histórico de movimentações, e avaliou o modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
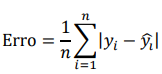
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874746
Engenharia de Software
Uma fintech desenvolveu um pipeline ponta a ponta (end-to-end) de machine learning para detecção de fraudes em transações financeiras.
O pipeline inclui as seguintes etapas:
(1) ingestão de dados em tempo real via streaming;
(2) feature engineering com agregações temporais (médias móveis de 7 e 30 dias);
(3) predição usando um modelo de gradient boosting;
(4) deployment em arquitetura de microsserviços.
Após três meses em produção, o time de MLOps observou degradação gradual no F1-score de 0.89 para 0.72, enquanto o monitoramento revelou que as distribuições das features agregadas apresentavam mudanças estatisticamente significativas (p < 0.01 no teste de Kolmogorov-Smirnov), embora as features brutas individuais permanecessem estáveis.
Considerando as melhores práticas de pipelines de ML em produção e estratégias de deployment, a equipe deve:
O pipeline inclui as seguintes etapas:
(1) ingestão de dados em tempo real via streaming;
(2) feature engineering com agregações temporais (médias móveis de 7 e 30 dias);
(3) predição usando um modelo de gradient boosting;
(4) deployment em arquitetura de microsserviços.
Após três meses em produção, o time de MLOps observou degradação gradual no F1-score de 0.89 para 0.72, enquanto o monitoramento revelou que as distribuições das features agregadas apresentavam mudanças estatisticamente significativas (p < 0.01 no teste de Kolmogorov-Smirnov), embora as features brutas individuais permanecessem estáveis.
Considerando as melhores práticas de pipelines de ML em produção e estratégias de deployment, a equipe deve:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874745
Engenharia de Software
Uma empresa de e-commerce implantou um modelo de machine learning para prever a probabilidade de churn, métrica que indica a rotatividade ou evasão de clientes. Após seis meses em produção, a equipe de dados observou que, embora as distribuições estatísticas das features de entrada permanecessem estáveis (mesmas médias, mesmos desvios-padrão e mesmas distribuições), o relacionamento entre essas features e a variável-alvo (churn) havia mudado significativamente devido a alterações no comportamento dos consumidores causadas por novas políticas de fidelização da empresa.
Diante desse cenário, é correto afirmar que o modelo:
Diante desse cenário, é correto afirmar que o modelo:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874744
Engenharia de Software
O desempenho de modelos de aprendizado de máquina está intrinsecamente relacionado ao equilíbrio entre viés e variância. Modelos com alto viés tendem a simplificar excessivamente o problema, resultando em subajuste (underfitting), enquanto modelos com alta variância podem capturar ruído nos dados de treinamento, levando ao sobreajuste (overfitting). Para mitigar esses problemas, diversas técnicas de regularização podem ser empregadas, ajustando a complexidade do modelo e melhorando sua capacidade de generalização.
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874743
Noções de Informática
O aprendizado de máquina (machine learning) é frequentemente categorizado em diferentes paradigmas, dependendo da natureza dos dados disponíveis e do problema a ser resolvido. Dois dos tipos mais comuns são o aprendizado supervisionado e o aprendizado não supervisionado.
A principal diferença conceitual entre essas duas abordagens reside no fato de que, no aprendizado supervisionado:
A principal diferença conceitual entre essas duas abordagens reside no fato de que, no aprendizado supervisionado: