Questões de Concurso
Sobre inferência estatística em estatística
Foram encontradas 1.612 questões
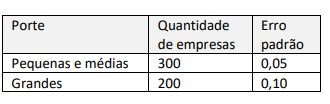
Em relação às variâncias dos estimadores obtidos pelas duas análises, é correto afirmar que:
A média da nota de satisfação foi de 7,2 (em uma escala de 0 a 10), e a variância populacional previamente estimada é de 1,44. A equipe deseja construir um intervalo de confiança de 95% para estimar a média da população com base na amostra. Utilize a tabela abaixo com valores da curva normal padrão (Z):

Com base nesses dados, o intervalo de confiança de 95% para a média populacional é, aproximadamente:
O desempenho é considerado satisfatório quando até 5% das metas pactuadas não são cumpridas. Em contrapartida, é considerado insatisfatório quando 20% ou mais das metas pactuadas não são cumpridas.
Os dados prévios são limitados, e a equipe deseja garantir decisões estatisticamente robustas — especialmente quanto à aceitação ou rejeição de municípios com base nos indicadores reportados. Para definir o tamanho da amostra e a regra de decisão sobre o desempenho dos municípios, a equipe técnica estabeleceu os seguintes critérios:
• a margem de erro máxima permitida para estimar a proporção populacional de municípios com desempenho satisfatório é de 4%;
• o nível de confiança deve ser de 95%;
• os erros do tipo I e II devem ser controlados de modo que:
▪ municípios com desempenho considerado bom sejam rejeitados erroneamente em, no máximo, 5% dos casos;
▪ municípios com desempenho considerado ruim sejam aceitos erroneamente em, no máximo, 10% dos casos.
Com base nessas informações, uma interpretação adequada dos parâmetros definidos pela equipe é a de que:
A partir dessa situação hipotética, assinale a opção correta.
A partir dessa situação hipotética, assinale a opção correta, considerando que os tempos de tramitação desse tipo de processo tenham distribuição normal.
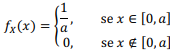
Considerando uma amostra aleatória simples X1, X2, X3 retirada de uma população cuja função de densidade seja dada pela expressão precedente, assinale a opção em que é apresentada uma estatística suficiente para a estimação do parâmetro desconhecido α.
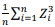 converge em probabilidade para
converge em probabilidade para Considerando a obtenção de dados quantitativos sobre a morfologia e o tamanho de nanopartículas com formas irregulares, qual abordagem é mais adequada para garantir uma análise estatística rigorosa?
O que esse valor indica?
I.O coeficiente ( β) de uma variável preditora contínua no modelo logístico representa a mudança no logaritmo da razão de chances (log odds) para cada aumento de uma unidade na variável preditora, mantendo as outras variáveis constantes.
II.A exponencial do coeficiente (exp(β )), conhecida como "odds ratio" ou razão de chances, indica o fator pelo qual as chances de ocorrência do evento de interesse são multiplicadas para cada aumento de uma unidade na variável preditora.
III.A avaliação do ajuste de um modelo logístico não utiliza o R² da regressão linear, mas sim pseudo-R² (como o de McFadden ou Nagelkerke) e a estatística de Hosmer-Lemeshow, que compara as probabilidades previstas com as observadas em grupos.
Está correto o que se afirma em:
(__)Para comparar a média de uma amostra pequena (n < 30) com uma média populacional conhecida, sendo a variância populacional desconhecida, o teste estatístico mais apropriado é o teste Z.
(__)Em um teste de hipóteses para uma proporção populacional, a hipótese nula (H 0: p = p 0) é testada utilizando-se uma estatística de teste que, para amostras grandes, segue aproximadamente uma distribuição normal padrão.
(__)O p-valor (ou nível descritivo) de um teste de hipóteses representa a probabilidade de se observar um resultado tão ou mais extremo que o obtido na amostra, assumindo que a hipótese nula seja verdadeira.
(__)Para comparar as variâncias de duas populações normais independentes, utiliza-se o teste Qui-quadrado ( χ²), que avalia a razão entre as variâncias amostrais.
Após análise, assinale a alternativa que apresenta a sequência correta dos itens acima, de cima para baixo:
I.A média amostral (barx) é um estimador pontual não viciado (ou não tendencioso) da média populacional (μ), pois o valor esperado de todas as possíveis médias amostrais é igual ao verdadeiro parâmetro populacional.
II.Um intervalo de confiança de 95% para a média populacional significa que há 95% de probabilidade de que a média amostral (barx) esteja contida nesse intervalo específico.
III.Para um mesmo tamanho de amostra, a amplitude de um intervalo de confiança para a média diminui à medida que o nível de confiança aumenta (por exemplo, de 90% para 99%), pois uma maior confiança exige uma estimativa mais precisa.
Está correto o que se afirma em:
I.Para comparar as médias de uma variável contínua entre quatro grupos independentes (por exemplo, quatro tratamentos diferentes), o procedimento estatístico mais adequado é realizar múltiplos testes t de Student, comparando os grupos dois a dois (Grupo 1 vs 2, 1 vs 3, etc.).
II.O teste Qui-quadrado de independência é utilizado para verificar se existe associação entre duas variáveis categóricas (qualitativas), comparando as frequências observadas em uma tabela de contingência com as frequências que seriam esperadas caso não houvesse associação entre as variáveis.
III.A Análise de Variância (ANOVA) compara as médias de múltiplos grupos ao analisar a razão entre a variabilidade entre os grupos e a variabilidade dentro dos grupos. Se a variabilidade entre os grupos for significativamente maior que a variabilidade dentro deles, rejeita-se a hipótese nula de que todas as médias populacionais são iguais.
Está correto o que se afirma em:
Dado que o 97,5 percentil da distribuição normal padrão é igual a 1,96, um intervalo de 95% de confiança para μ será dado aproximadamente por:
A respeito da inferência do modelo de regressão linear múltipla da forma y = β0 + β1x1 +β2x2 +⋯+ βkxk + ε , julgue o item subsecutivo, considerando que valem as suposições clássicas, como linearidade nos parâmetros, independência entre observações, homoscedasticidade, normalidade e ausência de multicolinearidade perfeita.
O p-valor representa a probabilidade de que a hipótese nula seja verdadeira condicional aos dados observados.
Considerando que um modelo de regressão linear apresenta a forma y = X ∙ β + ε , em que y é o vetor resposta, X é a matriz de covariáveis, β é o vetor de parâmetros e ε é o erro do modelo, julgue o próximo item acerca do estimador de mínimos quadrados (EMQ) e do estimador de máxima verossimilhança (EMV) para esse modelo.
O EMQ requer menos suposições sobre distribuições que o EMV para ser consistente.
Considerando que um modelo de regressão linear apresenta a forma y = X ∙ β + ε , em que y é o vetor resposta, X é a matriz de covariáveis, β é o vetor de parâmetros e ε é o erro do modelo, julgue o próximo item acerca do estimador de mínimos quadrados (EMQ) e do estimador de máxima verossimilhança (EMV) para esse modelo.
Quando os erros são homoscedásticos e normalmente distribuídos, os estimadores EMQ e EMV são não viesados e atingem o limite inferior de Cramér-Rao.