Questões de Concurso
Sobre modelos lineares em estatística
Foram encontradas 858 questões
Ano: 2023
Banca:
FCC
Órgão:
TRT - 18ª Região (GO)
Prova:
FCC - 2023 - TRT - 18ª Região (GO) - Analista Judiciário - Estatística |
Q2098354
Estatística
Um pesquisador deseja utilizar um modelo de regressão linear simples da forma Yi = β0 + β1Xi + ei onde β0 e β1 são parâmetros desconhecidos e ei
corresponde ao erro aleatório da i-ésima observação. O pesquisador utiliza-se da análise de resíduos
para verificar a qualidade do ajuste do modelo. Na análise de resíduos, é correto afirmar que
Ano: 2023
Banca:
FCC
Órgão:
TRT - 18ª Região (GO)
Prova:
FCC - 2023 - TRT - 18ª Região (GO) - Analista Judiciário - Estatística |
Q2098353
Estatística
Um conjunto de dados amostrais foram ajustados a um modelo de regressão linear múltipla da forma Yi = β0 + β1Xi1 + β2Xi2 + β3Xi3 + ei.
Todos os pressupostos necessários para a validade do modelo foram verificados e atendidos. β0, β1, β2 e β3 são parâmetros
desconhecidos e ei
corresponde ao erro aleatório da i-ésima observação com distribuição N(0, σ2). Uma amostra de 24 observações
forneceu um coeficiente de determinação múltiplo, R2, igual a 0,8. Nesse caso, o coeficiente de determinação ajustado é igual a
Ano: 2023
Banca:
FGV
Órgão:
Receita Federal
Prova:
FGV - 2023 - Receita Federal - Analista-Tributário (manhã) |
Q2096268
Estatística
UUma reta de regressão linear simples foi obtida a partir do modelo
Y = αX + β + e
pelo método de mínimos quadrados usual e mostrou as seguintes estimativas dos coeficientes: α = 3,4 e b = 0,5; além disso, obteve-se um coeficiente de correlação amostral igual a 0,9.
Com base nesses dados, avalie se as afirmativas a seguir estão corretas.
I. A porcentagem da variação total dos dados que é explicada pela regressão é menor do que 60%. II. A reta de regressão obtida ajusta bem o modelo. III. O intercepto α = 3,4 mostra que a valor grandes de x correspondem valores grandes de y.
Está correto o que se afirma em
Y = αX + β + e
pelo método de mínimos quadrados usual e mostrou as seguintes estimativas dos coeficientes: α = 3,4 e b = 0,5; além disso, obteve-se um coeficiente de correlação amostral igual a 0,9.
Com base nesses dados, avalie se as afirmativas a seguir estão corretas.
I. A porcentagem da variação total dos dados que é explicada pela regressão é menor do que 60%. II. A reta de regressão obtida ajusta bem o modelo. III. O intercepto α = 3,4 mostra que a valor grandes de x correspondem valores grandes de y.
Está correto o que se afirma em
Ano: 2023
Banca:
Instituto Consulplan
Órgão:
SEGEP-RO
Prova:
Instituto Consulplan - 2023 - SEGEP-RO - Analista de Desenvolvimento Social - Estatística |
Q2089717
Estatística
Considerando que o coeficiente de determinação, também
chamado de R², é uma das medidas de ajuste de um modelo
de regressão linear múltipla, analise as afirmativas a seguir.
I. A raiz quadrada de R² representa o coeficiente de correlação. II. Seu valor diminui à medida que novas covariáveis são incorporadas no modelo de regressão linear múltipla. III. Expressa a quantidade da variância dos dados que é explicada pelo modelo.
Está correto o que se afirma em
I. A raiz quadrada de R² representa o coeficiente de correlação. II. Seu valor diminui à medida que novas covariáveis são incorporadas no modelo de regressão linear múltipla. III. Expressa a quantidade da variância dos dados que é explicada pelo modelo.
Está correto o que se afirma em
Ano: 2023
Banca:
Instituto Consulplan
Órgão:
SEGER-ES
Prova:
Instituto Consulplan - 2023 - SEGER-ES - Analista do Executivo - Estatística |
Q2086190
Estatística
Em modelos de regressão linear múltipla, a análise de resíduos
tem um papel fundamental na verificação da qualidade do
ajuste. A medida de influência responsável por medir a diferença entre um modelo de regressão com determinada observação e um modelo sem aquela observação denomina-se:
Ano: 2023
Banca:
IADES
Órgão:
SEAGRI-DF
Prova:
IADES - 2023 - SEAGRI-DF - Analista de Desenvolvimento e Fiscalização Agropecuária -Economista |
Q2082844
Estatística
Um pesquisador avaliou o impacto de alguns fatores sobre a
nota de estudos sociais dos alunos. Para isso, considerou um
modelo de regressão linear múltipla. Os resultados são
apresentados na tabela a seguir.
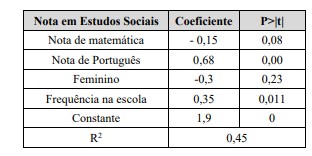
Tendo em vista a interpretação de resultados de modelos de regressão linear múltipla, assinale a alternativa correta.
Tendo em vista a interpretação de resultados de modelos de regressão linear múltipla, assinale a alternativa correta.
Q2073946
Estatística
Uma regressão linear simples é expressa por
y = α + βx + ε, onde α e β são os coeficientes linear
e angular da reta, os quais devem ser estimados a
partir de uma amostra e ε representa o erro aleatório
da regressão.
Considere que:
■ As estimativas pelo método de mínimos quadrados ordinários para o coeficiente linear α é igual a 1,5 e, para o coeficiente angular β é de 2,0 e que a variável x não está correlacionada com o erro ε. ■ Os resíduos das amostras envolvidas são independentes e identicamente distribuídos, com distribuição normal, média igual a 0,0 e variância com valor constante. ■ O valor assumido para x é igual a 3,0.
Diante do exposto, assinale a alternativa que traz o valor predito para y.
Considere que:
■ As estimativas pelo método de mínimos quadrados ordinários para o coeficiente linear α é igual a 1,5 e, para o coeficiente angular β é de 2,0 e que a variável x não está correlacionada com o erro ε. ■ Os resíduos das amostras envolvidas são independentes e identicamente distribuídos, com distribuição normal, média igual a 0,0 e variância com valor constante. ■ O valor assumido para x é igual a 3,0.
Diante do exposto, assinale a alternativa que traz o valor predito para y.
Q2073943
Estatística
Considere a tabela (na página ao lado) a qual traz
os limites unilaterais de cauda direita da distribuição F
de Fisher-Snedecor ao nível de 5% de probabilidade.
Analise a seguinte situação, observando os dados da do quadro de ANOVA a seguir.
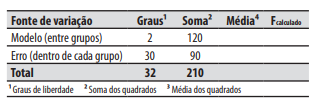
Um criador separou seu rebanho em três grupos, cada um com espécies diferentes: X, Y e Z. Em dado momento, ele resolveu testar se as espécies diferem de peso, ou seja, ele pretende descobrir se há mais variação de peso entre os grupos de cada espécie ou dentro de cada grupo.
Assim, ele tem as seguintes hipóteses estatísticas:
■ H0 Todas as espécies têm o mesmo peso, ou seja, o criador tem menos variação entre os grupos do que dentro dos grupos. ■ H1 As espécies diferem em peso, ou seja, o criador observa mais variação entre os grupos do que dentro dos grupos.
Considerando que o criador adota o seguinte critério de decisão:
■ Se o Fcalculado for menor ou igual ao Fcrítico para α = 0,05, aceita-se a hipótese nula H0. ■ Se o Fcalculado for maior que o Fcrítico para α = 0,05, aceita-se a hipótese alternativa H1.
Assinale a alternativa correta.
Analise a seguinte situação, observando os dados da do quadro de ANOVA a seguir.
Um criador separou seu rebanho em três grupos, cada um com espécies diferentes: X, Y e Z. Em dado momento, ele resolveu testar se as espécies diferem de peso, ou seja, ele pretende descobrir se há mais variação de peso entre os grupos de cada espécie ou dentro de cada grupo.
Assim, ele tem as seguintes hipóteses estatísticas:
■ H0 Todas as espécies têm o mesmo peso, ou seja, o criador tem menos variação entre os grupos do que dentro dos grupos. ■ H1 As espécies diferem em peso, ou seja, o criador observa mais variação entre os grupos do que dentro dos grupos.
Considerando que o criador adota o seguinte critério de decisão:
■ Se o Fcalculado for menor ou igual ao Fcrítico para α = 0,05, aceita-se a hipótese nula H0. ■ Se o Fcalculado for maior que o Fcrítico para α = 0,05, aceita-se a hipótese alternativa H1.
Assinale a alternativa correta.
Q2073941
Estatística
No que diz respeito à regressão linear, existem
pressupostos que são fundamentais para o seu uso,
sendo que os dados precisam atender a estes critérios
para que a análise de regressão linear seja confiável.
Com base nestes pressupostos, analise as afirmativas abaixo com relação ao conjunto de dados X.
1. O pressuposto da homocedasticidade é satisfeito quando a variação em torno da reta de regressão aumenta conforme variam os valores de X. 2. O pressuposto da independência de erros é satisfeito quando os erros em torno da reta de regressão são constantes para cada valor de X. 3. O pressuposto da normalidade de erros é satisfeito quando os erros em torno da reta de regressão são distribuídos de forma normal para cada valor de X.
Assinale a alternativa que indica todas as afirmativas corretas.
Com base nestes pressupostos, analise as afirmativas abaixo com relação ao conjunto de dados X.
1. O pressuposto da homocedasticidade é satisfeito quando a variação em torno da reta de regressão aumenta conforme variam os valores de X. 2. O pressuposto da independência de erros é satisfeito quando os erros em torno da reta de regressão são constantes para cada valor de X. 3. O pressuposto da normalidade de erros é satisfeito quando os erros em torno da reta de regressão são distribuídos de forma normal para cada valor de X.
Assinale a alternativa que indica todas as afirmativas corretas.
Q2073933
Estatística
Seja 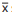 o vetor de médias estimado e S a matriz de
covariância estimada do vetor de dados sob controle
do vetor médio do processo.
o vetor de médias estimado e S a matriz de
covariância estimada do vetor de dados sob controle
do vetor médio do processo.
Assinale a alternativa que contém a expressão estatística utilizada como base para o gráfico de controle T2 de Hotelling.
o vetor de médias estimado e S a matriz de
covariância estimada do vetor de dados sob controle
do vetor médio do processo.
Assinale a alternativa que contém a expressão estatística utilizada como base para o gráfico de controle T2 de Hotelling.
Q2073929
Estatística
O coeficiente de determinação R2
é uma medida
estatística de quanto estão próximos os dados da
linha de regressão ajustada. Ele também é conhecido
como o coeficiente de determinação ou o coeficiente
de determinação múltipla para a regressão múltipla.
Identifique abaixo as afirmativas verdadeiras ( V ) e as falsas ( F ) a respeito do coeficiente de determinação R2.
( ) O R2 está sempre entre os valores 0 e 1. ( ) O R2 pode atingir valores de –1 a 1, dependendo da força da correlação entre as variáveis. ( ) Se aumentarmos o número de variáveis independentes, o coeficiente R2 pode aumentar ou permanecer igual, mas nunca decrescer. ( ) O R2 indica a porcentagem em que a variação explicada pela regressão representa da variação total.
Assinale a alternativa que indica a sequência correta, de cima para baixo.
Identifique abaixo as afirmativas verdadeiras ( V ) e as falsas ( F ) a respeito do coeficiente de determinação R2.
( ) O R2 está sempre entre os valores 0 e 1. ( ) O R2 pode atingir valores de –1 a 1, dependendo da força da correlação entre as variáveis. ( ) Se aumentarmos o número de variáveis independentes, o coeficiente R2 pode aumentar ou permanecer igual, mas nunca decrescer. ( ) O R2 indica a porcentagem em que a variação explicada pela regressão representa da variação total.
Assinale a alternativa que indica a sequência correta, de cima para baixo.
Q2073927
Estatística
Identifique abaixo as afirmativas verdadeiras ( V )
e as falsas ( F ) quanto aos Modelos Mistos Estatísticos.
( ) São modelos caracterizados por conter efeitos aleatórios e efeitos fixos. ( ) São usados para conjuntos de dados com estrutura multinível, ou seja, para análise de dados com estrutura hierárquica. ( ) Podem existir em casos onde existem somente efeitos aleatórios nas variáveis preditoras do modelo.
Assinale a alternativa que indica a sequência correta, de cima para baixo
( ) São modelos caracterizados por conter efeitos aleatórios e efeitos fixos. ( ) São usados para conjuntos de dados com estrutura multinível, ou seja, para análise de dados com estrutura hierárquica. ( ) Podem existir em casos onde existem somente efeitos aleatórios nas variáveis preditoras do modelo.
Assinale a alternativa que indica a sequência correta, de cima para baixo
Q2073921
Estatística
Dado o quadro de ANOVA a seguir:
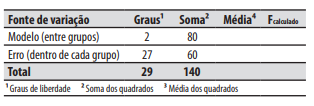
Assinale a alternativa que indica o valor mais próximo do Fcalculado.
Assinale a alternativa que indica o valor mais próximo do Fcalculado.
Ano: 2023
Banca:
FGV
Órgão:
CGE-SC
Prova:
FGV - 2023 - CGE-SC - Auditor do Estado - Economia - Tarde (Conhecimentos Específicos) |
Q2067267
Estatística
Considere o modelo de regressão estimado:
Wi = 0,5 + 0,1*Ei + 0,2*Di + ui,
em que wi é o logaritmo neperiano do salário, Ei é o logaritmo neperiano dos anos de estudo e Di é uma variável binária igual a 1 se homem e a 0 se mulher.
Considere que todas as estimativas são estatisticamente significativas a 1%.
A partir das estimativas acima, é possível concluir que, em média,
Wi = 0,5 + 0,1*Ei + 0,2*Di + ui,
em que wi é o logaritmo neperiano do salário, Ei é o logaritmo neperiano dos anos de estudo e Di é uma variável binária igual a 1 se homem e a 0 se mulher.
Considere que todas as estimativas são estatisticamente significativas a 1%.
A partir das estimativas acima, é possível concluir que, em média,
Ano: 2023
Banca:
FGV
Órgão:
CGE-SC
Prova:
FGV - 2023 - CGE-SC - Auditor do Estado - Economia - Tarde (Conhecimentos Específicos) |
Q2067265
Estatística
Considere o modelo de regressão:
Y = XB + u,
sendo Y um vetor nx1, X uma matriz nxk, B um vetor kx1 e u um vetor nx1. Y é a variável dependente, X representa um conjunto de regressores, B os parâmetros populacionais do modelo e u o termo aleatório.
As hipóteses a seguir são necessárias para que o estimador de MQO de B seja não viesado, à exceção de uma. Assinale-a.
Y = XB + u,
sendo Y um vetor nx1, X uma matriz nxk, B um vetor kx1 e u um vetor nx1. Y é a variável dependente, X representa um conjunto de regressores, B os parâmetros populacionais do modelo e u o termo aleatório.
As hipóteses a seguir são necessárias para que o estimador de MQO de B seja não viesado, à exceção de uma. Assinale-a.
Ano: 2023
Banca:
FGV
Órgão:
CGE-SC
Prova:
FGV - 2023 - CGE-SC - Auditor do Estado - Economia - Tarde (Conhecimentos Específicos) |
Q2067263
Estatística
Considere o modelo de regressão linear simples:
yi = a + bxi + ui,
em que y é a variável dependente, x é a variável explicativa, a é ointercepto, b é o coeficiente de inclinação e u, o termo aleatóriodo modelo.
A partir de uma amostra aleatória, obtém-se as seguintesinformações:
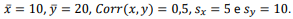
Assim, os estimadores dos parâmetros α e b que minimizam asoma dos quadrados dos resíduos são, respectivamente, iguais a
Ano: 2022
Banca:
UEG
Órgão:
UEG
Prova:
UEG - 2022 - UEG - Analista de Gestão Governamental - Atividades Laboratoriais – Biologia/Agrárias |
Q4138532
Estatística
Na avaliação de cultivares em campo, os tratamentos são as cultivares, portanto os tratamentos são qualitativos.
Os dados devem ser submetidos a uma análise de
Q4084630
Estatística
Preencha corretamente as lacunas do texto a seguir
quanto aos conceitos básicos e melhoramento genético animal.
A __________ é uma medida de dispersão. Também é considerada uma medida de __________ que ocorre em uma população em relação a uma característica qualquer. Já a ____________ é o termo estatístico que expressa o quanto se pode esperar na ___________ de uma variável por mudança unitária da outra variável.
A sequência que preenche corretamente as lacunas do texto é
A __________ é uma medida de dispersão. Também é considerada uma medida de __________ que ocorre em uma população em relação a uma característica qualquer. Já a ____________ é o termo estatístico que expressa o quanto se pode esperar na ___________ de uma variável por mudança unitária da outra variável.
A sequência que preenche corretamente as lacunas do texto é
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976942
Estatística
Os métodos de regressão linear são utilizados para se buscar soluções por polinômios ou métodos
iterativos que possibilitem estimar os valores de f(x), considerando-se um certo x de entrada. Uma das soluções é pelo Método dos Mínimos quadrados, que consiste em escolher os α de tal forma que a soma dos
quadrados dos desvios seja mínima, ou seja, de acordo com o critério dos quadrados mínimos, os coeficientes αk, que fazem com que φ(x) se aproxime ao máximo de f(x) descrito por
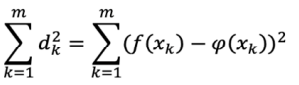
Assinale a alternativa em que se tem valor mais aproximado do cálculo pelo método dos mínimos quadrados, considerando α = 2,1831, x = 0,32 e o f(x) = x2. Repare que os dados dessa análise podem ser visualizados no gráfico a seguir.
Assinale a alternativa em que se tem valor mais aproximado do cálculo pelo método dos mínimos quadrados, considerando α = 2,1831, x = 0,32 e o f(x) = x2. Repare que os dados dessa análise podem ser visualizados no gráfico a seguir.
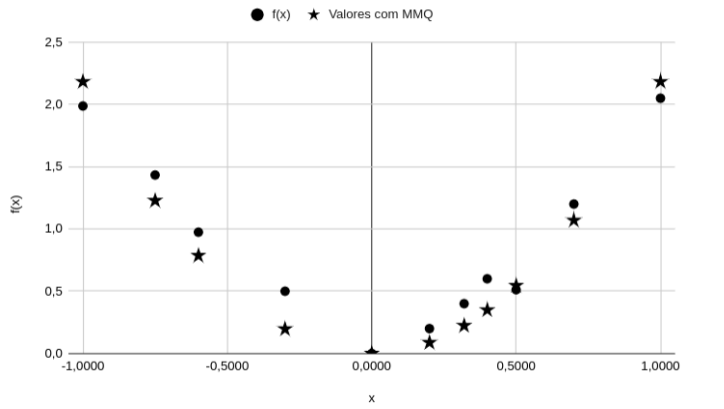
Fonte: IFSP, 2022.
Ano: 2022
Banca:
FUNDATEC
Órgão:
SUSEPE-RS
Prova:
FUNDATEC - 2022 - SUSEPE-RS - Técnico Superior Penitenciário - Estatística |
Q3958871
Estatística
Um experimento foi conduzido para determinar se o peso dos filhos de um casal pode
ser determinado a partir do peso, altura e idade dos pais bem como o gênero do filho (masculino e
feminino). Dados de 200 famílias foram coletados, nos quais apenas filhos com idades entre 19 e 21
anos, de ambos os sexos, foram considerados. Na tabela abaixo, apresenta-se alguns modelos de
regressão considerados para o problema, juntos com o R2 ajustado de cada modelo e o p-valor do
teste F de significância do modelo, utlizando-se a notação mnemônica Pp, Ap, Ip para o peso, altura e
idade do pai, respectivamente, e Pm, Am e Im para o peso, altura e idade da mãe, respectivamente e
por G a variável indicadora do gênero do filho, assumindo valor 0 quando o gênero for masculino e 1
se feminino.

Com as informações dadas sobre os modelos, analise as seguintes assertivas e assinale a alternativa correta.
I. O modelo menos adequado dentre os três apresentados é o modelo 1, pois tem p-valor elevado no teste de significância e R2 ajustado baixo, comparado com os outros.
II. Como os p-valores dos modelos 2 e 3 são pequenos e iguais, ambos explicam a mesma quantidade da variabilidade na resposta.
III. O modelo mais adequado dentre os três apresentados é o 2, pois o modelo apresenta p-valor baixo, indicando a significância do modelo, e ainda apresenta o maior R2 ajustado, o que indica que, dentre os modelos considerados, ele é o que melhor explica a variabilidade na resposta.
Com as informações dadas sobre os modelos, analise as seguintes assertivas e assinale a alternativa correta.
I. O modelo menos adequado dentre os três apresentados é o modelo 1, pois tem p-valor elevado no teste de significância e R2 ajustado baixo, comparado com os outros.
II. Como os p-valores dos modelos 2 e 3 são pequenos e iguais, ambos explicam a mesma quantidade da variabilidade na resposta.
III. O modelo mais adequado dentre os três apresentados é o 2, pois o modelo apresenta p-valor baixo, indicando a significância do modelo, e ainda apresenta o maior R2 ajustado, o que indica que, dentre os modelos considerados, ele é o que melhor explica a variabilidade na resposta.