Questões de Concurso
Sobre amostragem em estatística
Foram encontradas 1.411 questões
Um estudo por amostragem aleatória estratificada foi realizado para estimar a fração (p) de empresas com alguma dívida fiscal. A população, constituída por 500 empresas, foi dividida em três estratos, conforme a tabela a seguir. Enquanto p representa uma fração global, denota-se como Pk a fração de empresas do estrato k com alguma dívida fiscal. Assim, a tabela também mostra o tamanho da amostra em cada estrato, bem como o erro padrão do estimador de Pk.
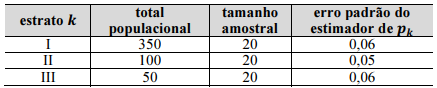
Com base nessas informações, se 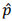 representar o estimador da
fração global de empresas com alguma dívida fiscal, a estimativa
da variância de será
representar o estimador da
fração global de empresas com alguma dívida fiscal, a estimativa
da variância de será
Um levantamento por amostragem aleatória simples (sem
reposição) será efetuado sobre uma população constituída por N = 225 empresas. O objetivo dessa amostragem é estimar o
parâmetro 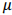 , que representa o preço médio (populacional) de
determinado produto comercializado por essas empresas. Se
, que representa o preço médio (populacional) de
determinado produto comercializado por essas empresas. Se 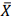 denota a média amostral, a margem de erro (∈) com 95% de
confiança é
denota a média amostral, a margem de erro (∈) com 95% de
confiança é 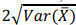 . O desvio padrão populacional dos
preços é igual a R$ 400.
. O desvio padrão populacional dos
preços é igual a R$ 400.
Nessa situação hipotética, para que a margem de erro seja igual a R$ 200, o tamanho da amostra para esse levantamento deverá ser igual a
A amostragem diz respeito à técnica especial para recolher amostras, que garante, tanto quanto possível, o acaso da escolha. Também chamada de levantamentos amostrais, são processos nos quais a amostra é obtida de uma população bem definida, por meio de processos bem protocolados e controlados pelo pesquisador. Pode-se subdividi-los em dois subgrupos: levantamentos probabilísticos e não probabilísticos. A esse respeito, analise as alternativas a seguir:
I. O levantamento probabilístico reúne técnicas que usam mecanismos aleatórios de seleção dos elementos de uma amostra, atribuindo a cada um deles uma probabilidade, conhecida, a priori, de pertencer à amostra.
II. No levantamento não probabilístico estão inclusas: amostras intencionais, nas quais os elementos são selecionados com o auxílio de especialistas, e amostras de voluntários, como ocorre em alguns testes sobre novos medicamentos e vacinas.
III. Apesar dos diferentes métodos de amostragem usados para a obtenção dos dados, é simples e preciso comparar os resultados obtidos em diversas amostras, quer sejam elas probabilísticas ou não probabilísticas.
IV. A amostragem não probabilística é justificável quando não há acesso à população como um todo.
É CORRETO o que se afirmar em:
Dentro da Estatística Descritiva, os métodos de amostragem probabilísticos (aleatórios) são mais complexos, morosos e dispendiosos que os métodos empíricos, uma vez que exigem conhecimento prévio da população em estudo. Alguns exemplos de métodos probabilísticos (aleatórios) foram elencados a seguir, exceto:
Alguns dos principais conceitos que se encontram presentes ao longo dos estudos estatísticos foram apresentados a seguir. Destaque a alternativa que possui um erro conceitual.
Tal planejamento amostral é denominado na Estatística como amostragem
Supondo que [X1, X2 , ... , Xn] seja uma amostra aleatória da variável aleatória X com distribuição Poisson
com parâmetro θ, ou seja, P(θ), é correto afirmar que
Seja a amostra aleatória de tamanho pequeno [X1, X2, ... , X10] de uma variável aleatória X com distribuição de probabilidade normal com média μ e variância σ2, então, as estatísticas x̄–μ/σ/√10, x̄–μ/s/√10, x̄–μ/σ e x̄–μ/s têm quais distribuições, respectivamente?
Em uma amostra aleatória com n = 25, observações da variável aleatória X que representam uma característica quantitativa foram obtidas por um estatístico que precisa estimar a média μ e o desvio-padrão σ da população (distribuição) de onde a amostra foi tomada por intervalo de nível 95% deconfiança. A análise dos dados forneceu os seguintes resultados: média amostral x̄ = 21,980 e desvio-padrão amostral s = 2,11877. O teste de Shapiro-Wilk, para verificar a Normalidade dos dados, resultou em W = 0,972867 e valor-p p = 0,721053; o escore t24,0,975 = 2,0639 e os escores X224;0,975 = 39,3641 e X224;0,025 = 12,4012.
Então, é correto afirmar que os intervalos de confiança para a média μ e o desvio-padrão σ são, respectivamente,
O estatístico que trata da análise de dados
referentes à Justiça Federal necessita conduzir
um estudo que requer informações sobre
determinada característica quantitativa, X, dos
processados em determinada Vara Federal. Um
dos objetivos é construir um intervalo de 95% de
confiança para o valor médio da característica
quantitativa do grupo de processados, com erro
de amostragem ou precisão de 0,5 σ, meio
desvio-padrão. Ele tomou, então, uma amostra
aleatória piloto de tamanho n0 = 5 que forneceu as
seguintes estatísticas amostrais, média e
variância, para a característica: x̄0 = 127,6 e S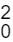 = 1290,8. A respeito das informações
anteriores, sabe-se que é possível assumir o
modelo de distribuição normal para a
característica quantitativa do grupo de
processados, que é finito com N = 2000 indivíduos
e com variância desconhecida. Assim,
conhecendo o escore da distribuição t de t4 (0,975) = 2,78, é correto afirmar que o tamanho
definitivo da amostra n é
= 1290,8. A respeito das informações
anteriores, sabe-se que é possível assumir o
modelo de distribuição normal para a
característica quantitativa do grupo de
processados, que é finito com N = 2000 indivíduos
e com variância desconhecida. Assim,
conhecendo o escore da distribuição t de t4 (0,975) = 2,78, é correto afirmar que o tamanho
definitivo da amostra n é
O estatístico de uma Vara Federal necessita verificar se a idade média dos condenados por prevaricação e a dos condenados por corrupção passiva são iguais. Para isso tomou amostras aleatórias de tamanhos: n1 = 15 de condenados por prevaricação e n2 = 20 condenados por corrupção passiva. As amostras forneceram as estatísticas: média amostral x̄1 = 25 anos e desvio-padrão amostral s1 = 2 anos do grupo da prevaricação e x̄2 = 31 anos e desvio-padrão amostral s2 = 3,5 anos do grupo da corrupção passiva. Verificou-se, aplicando os testes, que as amostras eram provenientes de distribuição normal, mas com variâncias desconhecidas e diferentes. Então, foi aplicado o teste adequado à situação e obteve-se, para a estatística do teste, o valor
Seja a amostra aleatória de variável aleatória X que tem distribuição normal com média μ e variância σ2, N(μ, σ2), [x1, x2, ... , xn], então, é correto afirmar que a Variância e o Erro Quadrático Médio do estimador de Máxima Verossimilhança (EMV) do parâmetro σ2 são, respectivamente,
Sendo a sequência de n ensaios binomiais
independentes, tendo a mesma probabilidade  θ de
“sucesso” em cada ensaio, se Sn = X1 + X2 + ... +
Xn é o número de sucessos nos n primeiros
ensaios, então Sn /n
θ de
“sucesso” em cada ensaio, se Sn = X1 + X2 + ... +
Xn é o número de sucessos nos n primeiros
ensaios, então Sn /n 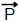 θ, ou seja, Sn /n converge em
probabilidade para θ. O enunciado da Lei dos
Grandes Números a que se exprime esse
resultado é a Lei dos Grandes Números de
θ, ou seja, Sn /n converge em
probabilidade para θ. O enunciado da Lei dos
Grandes Números a que se exprime esse
resultado é a Lei dos Grandes Números de
A amostragem por conveniência é uma técnica de coleta de dados na qual se aplica um método não probabilístico para a seleção da amostra; uma desvantagem dessa técnica é que as amostras produzidas por ela podem não ser representativas da população geral.