Questões de Concurso
Para tecnologista
Foram encontradas 4.871 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331315
Estatística
São algoritmos de classificação, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331314
Engenharia de Software
Observe as afirmativas a seguir, em relação a seleção
de atributos para algoritmos de aprendizado de máquina:
I. Se temos atributos na base de dados que sejam redundantes, irrelevantes ou inúteis, devemos eliminá-los.
II. Podemos eliminar atributos que contribuem muito pouco na construção de um modelo como os que tem um mesmo valor na grande maioria das instâncias.
III. Os atributos removidos do conjunto de treinamento devem ser também removidos do conjunto de testes.
Sobre as afirmativas acima, pode-se dizer que:
I. Se temos atributos na base de dados que sejam redundantes, irrelevantes ou inúteis, devemos eliminá-los.
II. Podemos eliminar atributos que contribuem muito pouco na construção de um modelo como os que tem um mesmo valor na grande maioria das instâncias.
III. Os atributos removidos do conjunto de treinamento devem ser também removidos do conjunto de testes.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331313
Estatística
Considere o problema de calcular agrupamentos dos
objetos apresentados na figura abaixo:
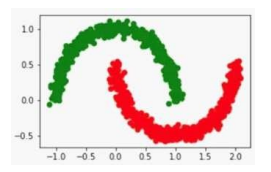
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331312
Sistemas de Informação
Quando realizamos o agrupamento de objetos de acordo
com seus atributos, ou seja, uma tarefa de aprendizado
não supervisionado, precisamos avaliar a qualidade deste
agrupamento sem informação de supervisão. Como não se
tem as classes ou rótulos das instâncias, é preciso avaliar
a qualidade dos grupos apenas através de aferições estatísticas de similaridade intra e inter-grupos. Dentre estes
índices, podemos citar, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331311
Algoritmos e Estrutura de Dados
Sobre o algoritmo Apriori para mineração de regras de
associação, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331310
Medicina
A bioética aborda temas delicados, alguns considerados
tabus. Dentre os temas abaixo,o que NÃO é relacionado
à bioética:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331309
Medicina
São princípios da ética biomédica, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331308
Saúde Pública
O CRISPR é uma técnica de edição de genes que traz
promessas no diagnóstico e tratamento de várias doenças.
Entretanto ela levanta uma série de desafios bioéticos. Com
relação a isso, é INCORRETO afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331307
Direito Digital
Segundo a LGPD, são direitos dos titulares dos dados
pessoais, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331306
Direito Digital
Sobre a Lei Geral de Proteção de Dados (LGPD), é
correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331305
Direito Digital
Sobre os termos apresentados na Lei Geral de Proteção
de Dados (LGPD), conforme apresentado na Coluna I.
Estabeleça a correta correspondência com as definições
da Coluna II.
Coluna I
1. Dado pessoal. 2. Dado pessoal sensível. 3. Dado anonimizado. 4. Banco de dados.
Coluna II
( ) informação relacionada a pessoa natural identificada ou identificável.
( ) conjunto estruturado de dados pessoais, estabelecido em um ou em vários locais, em suporte eletrônico ou físico.
( ) dado pessoal sobre origem racial ou étnica, convicção religiosa, opinião política, filiação a sindicato ou a organização de caráter religioso, filosófico ou político, dado referente à saúde ou à vida sexual, dado genético ou biométrico, quando vinculado a uma pessoa natural.
( ) dado relativo a titular que não possa ser identificado, considerando a utilização de meios técnicos razoáveis e disponíveis na ocasião de seu tratamento.
A sequência correta, de cima para baixo, é:
Coluna I
1. Dado pessoal. 2. Dado pessoal sensível. 3. Dado anonimizado. 4. Banco de dados.
Coluna II
( ) informação relacionada a pessoa natural identificada ou identificável.
( ) conjunto estruturado de dados pessoais, estabelecido em um ou em vários locais, em suporte eletrônico ou físico.
( ) dado pessoal sobre origem racial ou étnica, convicção religiosa, opinião política, filiação a sindicato ou a organização de caráter religioso, filosófico ou político, dado referente à saúde ou à vida sexual, dado genético ou biométrico, quando vinculado a uma pessoa natural.
( ) dado relativo a titular que não possa ser identificado, considerando a utilização de meios técnicos razoáveis e disponíveis na ocasião de seu tratamento.
A sequência correta, de cima para baixo, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331304
Saúde Pública
Quando construímos sistemas para realizar predições e
classificações, encontramos padrões nos dados e precisamos ter métricas para nos ajudar a aferir o desempenho
desses sistemas. É correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331303
Estatística
Em muitas situações precisamos trabalhar com dados
muito volumosos. Imagine que se queira saber a média de
altura de todas as pessoas vivas no mundo e não houvesse
uma maneira factível de medir todas as pessoas (população). Usualmente, extraímos um conjunto de dados menor
mas representativo e então analisamos este subconjunto
(amostra). Medimos alguns milhares de pessoas e esperamos que essa medida possa ser próxima o bastante da
medida que obteríamos se medíssemos todo mundo. Para
que essa medida seja confiável, precisamos calcular o intervalo de confiança. Para isto, precisamos selecionar diversas
amostras da população. Este tipo de técnica é chamada de:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331302
Estatística
Em relação a coleções de valores aleatórios gerados a
partir de distribuições de probabilidade:
I. Se selecionamos um valor, em seguida outro e outro formando uma lista, sua média é o valor esperado.
II. Variáveis independentes são aquelas que não dependem das outras variáveis ou seja não se influenciam.
III. Muitos algoritmos de aprendizado de máquina requerem variáveis independentes e identicamente distribuídas ou seja selecionadas da mesma distribuição.
De cima para baixo, a sequência correta é:
I. Se selecionamos um valor, em seguida outro e outro formando uma lista, sua média é o valor esperado.
II. Variáveis independentes são aquelas que não dependem das outras variáveis ou seja não se influenciam.
III. Muitos algoritmos de aprendizado de máquina requerem variáveis independentes e identicamente distribuídas ou seja selecionadas da mesma distribuição.
De cima para baixo, a sequência correta é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331301
Banco de Dados
Imagine que você está responsável por organizar uma
base de dados de vacinação de cidadãos de um determinado município. Tendo em vista que que existem potenciais
problemas de duplicidade de registros, você decidiu realizar
algumas tarefas de sumarização dos dados. A opção mais
adequada para esse processo é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331300
Saúde Pública
Observe as afirmativas a seguir, em relação a técnicas
de interação analítica para análise visual de dados:
I. A ordenação e o agrupamento de elementos facilitam a análise dos dados.
II. O uso de escala logarítmica para representação de dados não é recomendada por distorcer os dados.
III. A filtragem dos dados potencializa o processo analítico por trazer foco aos dados de interesse.
Sobre as afirmativas acima, pode-se dizer que:
I. A ordenação e o agrupamento de elementos facilitam a análise dos dados.
II. O uso de escala logarítmica para representação de dados não é recomendada por distorcer os dados.
III. A filtragem dos dados potencializa o processo analítico por trazer foco aos dados de interesse.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331299
Estatística
Em relação ao nosso sistema de percepção visual e
cognição, é INCORRETO afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331298
Estatística
Quando analisamos dados visualmente, buscamos
encontrar e compreender as partes da informação e como
elas se relacionam com outras. Por exemplo, em uma série
temporal, visamos analisar como determinadas variáveis
se relacionam com a variável tempo. Um análise de parte-todo ilustra como as partes se relacionam entre si e com
o todo. Séries temporais e parte-todo são dois exemplos
de relacionamentos quantitativos clássicos que podem ser
visualizados através de técnicas de visualização.
A coluna I mostra os relacionamentos quantitativos e a coluna II as técnicas de visualização. Estabeleça a correta correspondência entre as colunas I e II.
Coluna I
1. Série temporal. 2. Parte-todo.
Coluna II
( ) gráfico de linhas. ( ) gráfico de pizza. ( ) treemap. ( ) gráfico de radar. ( ) gráfico de marimekko.
A sequência correta, de cima para baixo, é:
A coluna I mostra os relacionamentos quantitativos e a coluna II as técnicas de visualização. Estabeleça a correta correspondência entre as colunas I e II.
Coluna I
1. Série temporal. 2. Parte-todo.
Coluna II
( ) gráfico de linhas. ( ) gráfico de pizza. ( ) treemap. ( ) gráfico de radar. ( ) gráfico de marimekko.
A sequência correta, de cima para baixo, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331297
Banco de Dados
Sobre os relacionamentos dos bancos de dados relacionais, podemos afirmar que:
I. Não precisam ser entre duas entidades distintas, sendo possível a presença de um relacionamento entre apenas uma entidade.
II. Os relacionamentos podem ter atributos.
III. São representados por elipses no modelo entidade-relacionamento.
IV. A cardinalidade especifica o número mínimo e o máximo de instâncias que uma entidade pode participar.
I. Não precisam ser entre duas entidades distintas, sendo possível a presença de um relacionamento entre apenas uma entidade.
II. Os relacionamentos podem ter atributos.
III. São representados por elipses no modelo entidade-relacionamento.
IV. A cardinalidade especifica o número mínimo e o máximo de instâncias que uma entidade pode participar.
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331296
Banco de Dados
Sobre a o modelo entidade-relacionado, é INCORRETO
afirmar que: