Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 568 questões
Em relação às fases do CRISP-DM, julgue o próximo item.
A fase 7 do CRISP-DM indica que o processo de construção do armazém de dados correspondente deve ser revisado em função das atualizações dos dados.
Em relação às fases do CRISP-DM, julgue o próximo item.
Na fase de modelagem do CRISP-DM, além da divisão de dados em treinamento, testes e validação, são escolhidos os algoritmos que podem ser testados e utilizados de acordo com o tipo de exploração dos dados desejada.
I – As soluções para resolver o problema de valores ausentes são diversas, sendo as mais comuns: remoção do exemplar em que ocorre a falta do valor, preenchimento manual dos valores e preenchimento automático dos valores.
II – Os valores ruidosos referem-se a modificações dos valores originais e que, portanto, consistem em erros de medidas ou em valores consideravelmente diferentes da maioria dos outros valores do conjunto de dados, os chamados outliers. Há duas abordagens para o tratamento destes dados: inspeção e correção manual; e identificação e limpeza automática.
III - Procedimentos para integração de dados consistem em realizar ações que permitam integrar, adequadamente, dados provenientes de diversas fontes de dados. Geralmente, quando os dados provêm de diferentes fontes, os valores assumidos por atributos não possuem o mesmo domínio ou não estão formatados sob o mesmo tipo de dado, ainda que digam respeito à mesma descrição de uma entidade do mundo real. As principais motivações para a aplicação de procedimentos de integração de dados são, portanto, a presença de valores inconsistentes e a presença de valores redundantes.
De acordo com Silva, Peres e Boscarioli (2016), é CORRETO afirmar que:
I – A mineração de dados é uma disciplina exclusiva da engenharia da computação, utilizada como ferramenta por demais áreas de conhecimento.
II – As tarefas descritivas da mineração de dados fazem inferência a partir dos dados e possuem o objetivo de realizar predições.
III – Durante as tarefas de mineração de dados, os valores de dados outliers não podem ser descartados, para garantir a fidedignidade do modelo em uso.
Conforme Castro e Ferrari (2016), é CORRETO afirmar que:
I – As aplicações de OLAP são dominadas por consultas ad hoc complexas. Em termos de SQL (Structured Query Language), as consultas OLAP envolvem operadores de agrupamento e agregação e fornecem excelente suporte para condições booleanas complexas.
II – O problema fundamental na manutenção de um Data Warehouse é a manutenção síncrona de tabelas replicadas e visões materializadas.
III – A mineração de dados está relacionada à subárea da estatística chamada análise combinatória de dados.
RAGHU, R.; GEHRKE, J., Sistemas de Gerenciamento de Banco de Dados, 3° Ed. Editora McGraw-Hill, 2011.
Assinale a alternativa correta conforme Raghu e Gehrke (2011):
Avalie a tabela apresentada em Silva, Peres e Boscarioli (2017, p. 48) e responda a questão.
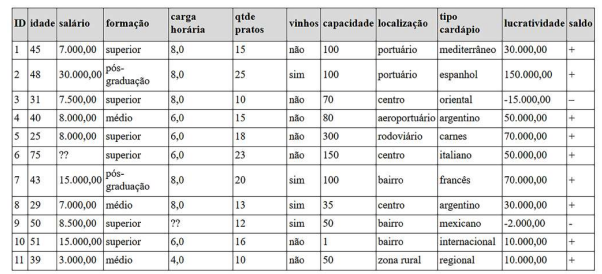
(SILVA, Leandro Augusto da; PERES, Sarajane Marques; BOSCARIOLI, Clodis. Introdução à Mineração de Dados Com Aplicações em R. Rio de Janeiro: Elsevier, 2016.)
A avalie as seguintes sentenças
I - Se a mineração de dados for executada com algoritmos que aceitam apenas dados categóricos, poderse-á aplicar alguma técnica de categorização para conversão de dados. Por exemplo, converter “idade” em “jovem” (para idades de 18 até 49 anos) ou “sênior” (para idades de 50 a 90 anos).
II - Se a mineração de dados for executada com algoritmos que aceitem apenas dados numéricos, poder-se-á aplicar alguma técnica de discretização para conversão de dados. Por exemplo, converter “formação” de “nenhuma” para 1, “fundamental” em 2, “médio” em 3, “superior” em 4, “pós-graduação” em 5.
III - Se a mineração de dados for executada com algoritmos que aceitem somente um determinado tipo de dados, deve-se obter outro conjunto de dados.
De acordo com Silva, Peres e Boscarioli (2016), é VERDADEIRO o que se afirma:
Avalie a tabela apresentada em Silva, Peres e Boscarioli (2017, p. 48) e responda a questão.
(SILVA, Leandro Augusto da; PERES, Sarajane Marques; BOSCARIOLI, Clodis. Introdução à Mineração de Dados Com Aplicações em R. Rio de Janeiro: Elsevier, 2016.)
Considere as sentenças relacionadas às tarefas de mineração de dados.
I - As tarefas preditivas usam os valores dos atributos descritivos para prever valores futuros ou incógnitos de outros atributos de interesse.
II - As tarefas consultivas usam valores dos atributos para identificar modelos que podem ser utilizados na classificação e reconhecimento de padrões.
III - As tarefas descritivas têm o objetivo de reconhecer padrões que descrevem os dados de maneira que o ser humano possa interpretar.
IV - As tarefas imperativas são implementadas com linguagens de programação baseadas em paradigmas imperativos.
De acordo com Silva, Peres e Boscarioli (2016), é VERDADEIRO o que se afirma:
(SILVA, Leandro Augusto da; PERES, Sarajane Marques; BOSCARIOLI, Clodis. Introdução à Mineração de Dados Com Aplicações em R. Rio de Janeiro: Elsevier, 2016.)
I. Seu objetivo é extrair conjuntos de itens frequentes de um banco de dados.
II. Um exemplo de padrão frequente são as regras de associação.
III. Dado um conjunto de itens X = {x1, x2,…,xm} e um conjunto de transações T = {t1, t2, …, tn}, um subconjunto de X, S, é chamado de conjunto de itens frequentes se S ocorre em uma porcentagem de todas as transações em T que excede um limite, denominado suporte.
IV. O suporte de um conjunto de itens Y, suporte(Y), é definido como o número de transações em T que contêm o conjunto de itens Y.
Das afirmativas acima, é correto afirmar que:
Assinale a alternativa que apresenta corretamente uma metodologia para processos de mineração de dados

Julgue o item subsecutivo, referentes a mineração de dados.
A mineração de dados é o processo de descoberta de padrões e de outras informações valiosas de grandes conjuntos de dados.
Julgue o item subsecutivo, referentes a mineração de dados.
Na modelagem da metodologia CRISP-DM, métodos como validação cruzada e métricas de desempenho são empregados para se avaliar o quão bem os modelos se saem em dados não vistos.
Considere o conjunto de dados a seguir.
[3, 5, 7, 8, 10, 12, 15, 20, 22, 30, 50]
O valor normalizado por escalonamento robusto referente ao elemento “22” é dado aproximadamente por
Assinale a opção que contém apenas tarefas de mineração de dados.