Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 568 questões
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
Outliers podem ser resultantes de erros de medição, entrada
de dados ou processamento de dados, ou amostragem não
representativa.
No que se refere à qualidade e visualização de dados, julgue o item a seguir.
Para a identificação de outliers, deve-se calcular o intervalo
interquartil (IQR) e identificar dados que estão a mais de 1,5
vezes o IQR abaixo do primeiro quartil ou acima do terceiro
quartil.
A respeito de análise exploratória de dados, julgue o item a seguir.
Na etapa de pré-processamento de dados, a discretização
envolve o ranqueamento estatístico dos dados, dividindo-os
em faixas ou intervalos e agrupando-os em classes definidas
com base em suas características intrínsecas.
A respeito de análise exploratória de dados, julgue o item a seguir.
Um dado anômalo, ou outlier, é um valor que se destaca
significativamente dos demais em um conjunto de dados e
pode ser identificado visualmente por meio do gráfico boxplot.
A respeito de análise exploratória de dados, julgue o item a seguir.
Na análise exploratória de dados, é comum categorizar os
valores não numéricos como variáveis qualitativas, que
podem ser subdivididas em discreta, como raça e cor, e em
ordinal, como tamanho de uma roupa ou classe social.
No que se refere a deep learning e mineração de dados, julgue o item subsecutivo.
A mineração de dados é comumente classificada por sua
capacidade de realizar determinadas tarefas, entre as quais
está a estimação, que, embora similar à classificação, é usada
quando o registro é identificado por um valor numérico e não
um categórico.
No que se refere a modelagem dimensional, mineração de dados e big data, julgue o item subsequente.
No modelo CRISP-DM, a fase de preparação dos dados é caracterizada por atividades como análise da qualidade dos dados,
exploração dos dados, geração dos primeiros insights e formulação de hipóteses.
( ) Em um sistema BigData, o pipeline de dados implementa as etapas necessárias para mover dados de sistemas de origem, transformar esses dados com base nos requisitos e armazenar os dados em um sistema de destino, incluindo todos os processos necessários para transformar dados brutos em dados preparados que os usuários podem consumir.
( ) Dentre os métodos de manipulação de valores ausentes, em processamento massivo e paralelo, consta a normalização numérica, que se refere ao processo de ajustar os dados para que estejam em uma escala comparável, geralmente entre 0 e 1.
( ) A demanda crescente por medidas de criptografia ponta a ponta (da produção ao backup) tornam menos eficazes e relevantes tecnologias legadas, como a deduplicação de dados (data deduplication), que busca ajudar a otimizar o armazenamento e melhorar o desempenho de um sistema ao estabelecer processo de identificar e eliminar dados duplicados em um sistema.
As afirmativas são, respectivamente,
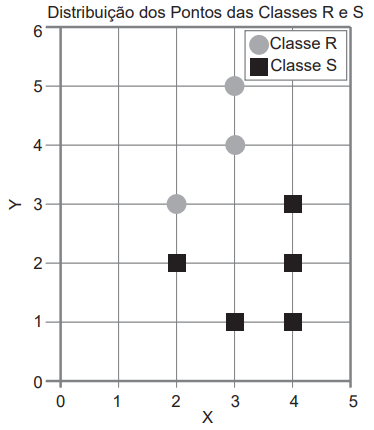
Nesse contexto, as classes dos pontos [(3,2),(3,3) e (4,4)] são, respectivamente:
Avalie se os dados ausentes são categorizados como
I. MCAR. Valores ausentes completamente aleatórios.
II. Valores ausentes aleatórios.
III. MICE. Valores ausentes usando imputação múltipla usando equações encadeadas.
Está correto o que se apresenta em
Julgue o item a seguir que tratam de extração e representação de conhecimento.
Em mineração de dados, interpretação e explanação consiste
em filtrar o conjunto de dados por meio de mecanismo que
varia de acordo com a técnica de mineração utilizada.
Considerando processos de análise e mineração de dados, julgue o item subsecutivo.
No contexto de mineração de dados, o atributo da veracidade
está associado ao grau de confiabilidade dos dados utilizados
na solução.
Considerando processos de análise e mineração de dados, julgue o item subsecutivo.
Em data mining, um mesmo processo de análise de dados
pode utilizar bancos de dados relacionais ou NoSQL, mas
não simultaneamente.
Considerando processos de análise e mineração de dados, julgue o item subsecutivo.
O processo de análise por inferência busca o conhecimento
dos dados para obtenção de resultados consolidados.
Considerando processos de análise e mineração de dados, julgue o item subsecutivo.
Em data mining, a técnica de associação é uma função que
determina o coeficiente de afinidade entre certos eventos.
Considerando processos de análise e mineração de dados, julgue o item subsecutivo.
É na fase de mineração do data mining que são definidos os metadados dos dados manipulados.