Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 568 questões
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880235
Banco de Dados
Árvores de decisão (AD) são classificadores muito utilizados em
Ciência de Dados. Com relação as características da AD, analise as
afirmativas a seguir.
I. É a representação de uma função que mapeia um vetor de valores de atributos para um único valor de saída.
II. Uma árvore de decisão chega à sua decisão realizando uma sequência de testes, começando por uma de suas raízes e seguindo o ramo apropriado até que uma folha seja alcançada.
III. Cada nó interno na árvore corresponde a um teste do valor de um dos atributos de entrada, os ramos a partir do nó são rotulados com os possíveis valores do atributo, e os nós folha especificam qual valor deve ser retornado pela função.
Está correto o que se afirma em
I. É a representação de uma função que mapeia um vetor de valores de atributos para um único valor de saída.
II. Uma árvore de decisão chega à sua decisão realizando uma sequência de testes, começando por uma de suas raízes e seguindo o ramo apropriado até que uma folha seja alcançada.
III. Cada nó interno na árvore corresponde a um teste do valor de um dos atributos de entrada, os ramos a partir do nó são rotulados com os possíveis valores do atributo, e os nós folha especificam qual valor deve ser retornado pela função.
Está correto o que se afirma em
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880232
Banco de Dados
A regressão logística é um modelo muito popular na ciência de
dados, ele é muito utilizado em diversos projetos da ALEGO. Com
relação às características da regressão logística, analise as
afirmativas a seguir.
I. É um modelo de regressão linear e dentro do contexto do aprendizado de máquina, a regressão logística pertence à família de modelos de aprendizado de máquina supervisionado.
II. Representa dois grupos de interesse como uma variável binária com valores 0 e 1, não importando qual o grupo é designado com os valores o versus 1, mas a designação de como dever ser observada interpretação dos coeficientes.
III. A função logística é representada pelas seguintes fórmulas:
a) Logit(pi) = 1/(1+ ln(-pi))
b) exp(pi/(1-pi)) = β_0 + β _1*X_1 + … + β _k*K_k.
onde:
logit(pi) é a variável dependente ou de resposta, e x é a variável independente.
Está correto o que se afirma em
I. É um modelo de regressão linear e dentro do contexto do aprendizado de máquina, a regressão logística pertence à família de modelos de aprendizado de máquina supervisionado.
II. Representa dois grupos de interesse como uma variável binária com valores 0 e 1, não importando qual o grupo é designado com os valores o versus 1, mas a designação de como dever ser observada interpretação dos coeficientes.
III. A função logística é representada pelas seguintes fórmulas:
a) Logit(pi) = 1/(1+ ln(-pi))
b) exp(pi/(1-pi)) = β_0 + β _1*X_1 + … + β _k*K_k.
onde:
logit(pi) é a variável dependente ou de resposta, e x é a variável independente.
Está correto o que se afirma em
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880223
Banco de Dados
Os analistas de Ciência de Dados da ALEGO reconhecem que a
abordagem tradicional de análise de dados envolve um ciclo
composto por diversas etapas e uma vez que tenham definidos
seus modelos preditivos, eles podem ser aplicados a novos
conjuntos de dados. A figura criada pelos analistas representa um
ciclo de análise preditiva e score de dados. Analise a figura e
relacione a numeração indicada nas etapas com as suas
respectivas operações.
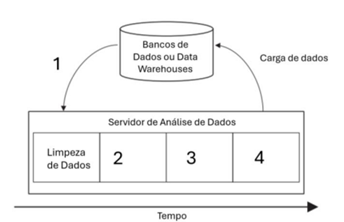
A relação correta, na ordem dada, é:
A relação correta, na ordem dada, é:
Ano: 2026
Banca:
FUNATEC
Órgão:
Prefeitura de São José do Divino - PI
Prova:
FUNATEC - 2026 - Prefeitura de São José do Divino - PI - Professor(a) - Ensino Fundamental Anos Finais - Informática |
Q3865193
Banco de Dados
O processo de KDD (Knowledge Discovery in
Databases) é fundamental na mineração de dados e
envolve etapas bem definidas.
Baseando-se nessas informações, pode-se concluir que a etapa do KDD responsável pela limpeza, seleção e transformação dos dados antes da aplicação dos algoritmos é denominada:
Baseando-se nessas informações, pode-se concluir que a etapa do KDD responsável pela limpeza, seleção e transformação dos dados antes da aplicação dos algoritmos é denominada:
Ano: 2026
Banca:
CESPE / CEBRASPE
Órgão:
TCE-MG
Prova:
CESPE / CEBRASPE - 2026 - TCE-MG - Analista de Controle Externo - Especialidade: Ciência da Computação |
Q3856625
Banco de Dados
Assinale a opção que apresenta a ferramenta de TI mais
apropriada para examinar grandes volumes de registros
financeiros e identificar inconsistências em uma auditoria de
políticas públicas e finanças.
Ano: 2026
Banca:
CESPE / CEBRASPE
Órgão:
TCE-MG
Prova:
CESPE / CEBRASPE - 2026 - TCE-MG - Analista de Controle Externo - Especialidade: Ciência da Computação |
Q3856600
Banco de Dados
Assinale a opção correta acerca do modelo LDA (latent dirichlet
allocation), amplamente utilizado para extração de tópicos em
tarefas de mineração de textos.
Q3851685
Banco de Dados
A análise de dados, no contexto da análise de negócios, envolve o
uso integrado de tecnologias computacionais, técnicas estatísticas
e métodos de ciência administrativa para transformar dados
históricos em informações úteis, apoiando decisões e
recomendando ações. Dentro desse escopo, a análise preditiva
busca responder “o que provavelmente acontecerá?”, recorrendo
a ferramentas capazes de identificar padrões e antecipar
comportamentos futuros a partir de grandes volumes de dados.
Considerando os facilitadores característicos da análise de negócios preditiva, assinale a opção que apresenta um facilitador típico dessa abordagem.
Considerando os facilitadores característicos da análise de negócios preditiva, assinale a opção que apresenta um facilitador típico dessa abordagem.
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Infraestrutura de TI |
Q3841867
Banco de Dados
Atualmente, as empresas têm executado um processo
administrativo, denominado gestão de dados, que
consiste em recolher, organizar, proteger e usar
informações, com o objetivo de utilizar os dados para
melhorar a eficiência, a produtividade e a tomada de
decisões. Nesse contexto, um termo, que tem por
significado a mineração de dados, consiste no uso de
processos para explorar grandes quantidades de dados
digitais à procura de padrões consistentes, como regras
de associação ou sequências temporais, visando
descobrir relacionamentos sistemáticos entre variáveis,
detectando assim novos subconjuntos de dados.
Paralelamente, outro termo, traduzido como armazém de
dados, é, basicamente, um depósito de dados digitais
para armazenar informações corporativas detalhadas.
Esses dois termos são conhecidos, respectivamente, como:
Esses dois termos são conhecidos, respectivamente, como:
Ano: 2025
Banca:
Quadrix
Órgão:
Fundação do ABC
Provas:
Quadrix - 2025 - Fundação do ABC - Assistente Social - Edital nº 1
|
Quadrix - 2025 - Fundação do ABC - Enfermeiro - Edital nº 1 |
Quadrix - 2025 - Fundação do ABC - Farmacêutico - Edital nº 1 |
Quadrix - 2025 - Fundação do ABC - Médico Generalista - Edital nº 1 |
Q3756313
Banco de Dados
Texto associado
Texto para as questão.
O conhecimento tem sido reconhecido como um
dos mais importantes recursos de uma organização, que
torna possíveis ações inteligentes nos planos organizacional
e individual e leva a inovações e à capacidade de
continuamente criar produtos e serviços excelentes. O
processo de gestão do conhecimento abrange toda a forma
de gerar, armazenar, distribuir e utilizar o conhecimento, de
modo que se torna necessária a utilização de tecnologias
de informação para facilitar esse processo, dado o grande
aumento no volume de dados.
Ao longo do tempo, percebeu‑se que a velocidade
de coleta de informações era muito maior que a velocidade
de processamento ou de análise dessas informações.
Isso gerou um problema e uma contradição, pois as
organizações, por possuírem uma grande quantidade
de dados, possuem uma falsa sensação de que estão
bem‑informadas, no entanto essas informações de nada
servem se não forem analisadas de forma correta e em
tempo hábil.
Em outras palavras, a coleta e o armazenamento
de dados, por si sós, não contribuem para melhorar
a estratégia da organização. É necessário que sejam
feitas análises sobre essa grande quantidade de dados,
estabelecendo‑se indicadores para descobrir padrões de
comportamento implícitos nos dados, além de relações
de causa e efeito. O processamento e a análise das
informações geradas pelas enormes bases de dados atuais
de forma correta estão entre os requisitos essenciais para
uma boa tomada de decisão.
Em um ambiente tão mutável como o das
organizações, na atualidade, torna‑se necessária a aplicação
de técnicas e ferramentas automáticas que agilizem o
processo de extração de informações relevantes de grandes
volumes de dados. Uma metodologia emergente, que tenta
solucionar o problema da análise de grandes quantidades
de dados e ultrapassa a habilidade e a capacidade humanas,
é a descoberta de conhecimento em banco de dados.
Data mining, ou mineração de dados, é uma
técnica que faz parte de uma das etapas da descoberta de
conhecimento em banco de dados. Ela é capaz de revelar,
automaticamente, o conhecimento que está implícito em
grandes quantidades de informações armazenadas nos
bancos de dados de uma organização. Essa técnica pode
fazer, entre outras atividades, uma análise antecipada dos
eventos, prevendo tendências e comportamentos futuros
e permitindo aos gestores a tomada de decisões com base
em fatos, em vez de em suposições.
Internet: <scielo.br> (com adaptações).
Segundo o texto, a técnica de mineração de dados
Ano: 2025
Banca:
UFSM
Órgão:
UFSM
Prova:
UFSM - 2025 - UFSM - Analista de Tecnologia da Informação (Inteligência Artificial) |
Q3729822
Banco de Dados
Em uma pesquisa sobre hábitos daqueles que passaram no concurso público X, gerou-se a seguinte
tabela como exemplo dos dados coletados.
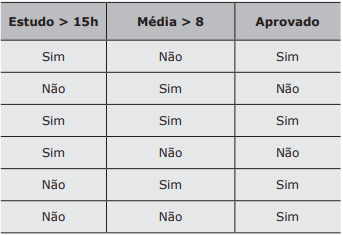
Hábitos vs Aprovação no Concurso X. A primeira coluna significa que o estudo semanal foi maior que 15h um mês antes do concurso. A segunda coluna refere-se à média final no curso superior. A coluna “Aprovado” refere-se a quem foi aprovado na primeira tentativa.
Para esta tabela, considerando a regra gerada pelo algoritmo Apriori, {Estudo>15h}→{Aprovado}, assinale a alternativa com a afirmação correta.
Hábitos vs Aprovação no Concurso X. A primeira coluna significa que o estudo semanal foi maior que 15h um mês antes do concurso. A segunda coluna refere-se à média final no curso superior. A coluna “Aprovado” refere-se a quem foi aprovado na primeira tentativa.
Para esta tabela, considerando a regra gerada pelo algoritmo Apriori, {Estudo>15h}→{Aprovado}, assinale a alternativa com a afirmação correta.
Ano: 2025
Banca:
UFSM
Órgão:
UFSM
Prova:
UFSM - 2025 - UFSM - Analista de Tecnologia da Informação (Inteligência Artificial) |
Q3729820
Banco de Dados
Há múltiplas maneiras de criar sistemas de recomendação. Uma das maneiras, baseada em mineração de dados, é identificar quais itens costumam
ocorrer em conjunto e posteriormente programá-las
no sistema. Tal problema é solucionado por algoritmos de associação que podem gerar regras ao estilo
setA→setB (leia-se, conjunto A implica conjunto B),
em que diversas métricas podem ser obtidas para
validar a força da regra.
Assinale a alternativa que, respectivamente, corresponde a um algoritmo de associação e a uma métrica usada para validar a regra.
Assinale a alternativa que, respectivamente, corresponde a um algoritmo de associação e a uma métrica usada para validar a regra.
Ano: 2025
Banca:
FGV
Órgão:
AgSUS
Prova:
FGV - 2025 - AgSUS - Analista de Gestão Tecnologia da Informação |
Q3660448
Banco de Dados
Um analista de dados da AgSUS sabe que a detecção de anomalias,
ou detecção de valores discrepantes, é a identificação de uma
observação, evento ou ponto de dados que se desvia do que é
padrão ou esperado, tornando-o inconsistente em relação ao resto
do conjunto de dados. Relacione os tipos de anomalias de dados
às suas respectivas definições.
1. Anomalias não intencionais.
2. Anomalias pontuais.
3. Anomalias contextuais.
4. Anomalias coletivas.
( ) Essas anomalias, também conhecidas como valores discrepantes globais, são pontos de dados individuais que estão muito fora do restante do conjunto de dados. Um exemplo desses tipo anomalia é um saque de conta bancária que é significativamente maior do que qualquer um dos saques anteriores do usuário;
( ) Essas anomalias envolvem um conjunto de instâncias de dados que juntas se desviam da norma, mesmo que as instâncias individuais possam parecer normais. Um exemplo desse tipo de anomalia seria um conjunto de dados de tráfego de rede que mostra um aumento repentino no tráfego de vários endereços IP ao mesmo tempo;
( ) Essas anomalias são pontos de dados que se desviam da norma devido a erros ou ruído no processo de coleta de dados. Esses erros podem ser sistemáticos ou aleatórios, originados por problemas como sensores defeituosos ou erro humano durante a entrada de dados. Esse tipo de anomalia pode distorcer o conjunto de dados, dificultando a obtenção de insights precisos;
( ) Essas anomalias são pontos de dados que se desviam da norma dentro de um contexto específico. Essas anomalias não são necessariamente valores discrepantes quando consideradas isoladamente, mas se tornam anômalas quando vistas dentro de seu contexto específico. Por exemplo, considere o uso de energia. Se houver um aumento repentino no consumo de energia ao meio-dia, quando normalmente nenhum membro da família está em casa. Este dado pode não ser um valor discrepante quando comparado ao consumo de energia pela manhã ou à noite (quando as pessoas geralmente estão em casa), mas é anômalo em relação ao horário em que ocorreu.
A relação correta, na ordem dada, é:
1. Anomalias não intencionais.
2. Anomalias pontuais.
3. Anomalias contextuais.
4. Anomalias coletivas.
( ) Essas anomalias, também conhecidas como valores discrepantes globais, são pontos de dados individuais que estão muito fora do restante do conjunto de dados. Um exemplo desses tipo anomalia é um saque de conta bancária que é significativamente maior do que qualquer um dos saques anteriores do usuário;
( ) Essas anomalias envolvem um conjunto de instâncias de dados que juntas se desviam da norma, mesmo que as instâncias individuais possam parecer normais. Um exemplo desse tipo de anomalia seria um conjunto de dados de tráfego de rede que mostra um aumento repentino no tráfego de vários endereços IP ao mesmo tempo;
( ) Essas anomalias são pontos de dados que se desviam da norma devido a erros ou ruído no processo de coleta de dados. Esses erros podem ser sistemáticos ou aleatórios, originados por problemas como sensores defeituosos ou erro humano durante a entrada de dados. Esse tipo de anomalia pode distorcer o conjunto de dados, dificultando a obtenção de insights precisos;
( ) Essas anomalias são pontos de dados que se desviam da norma dentro de um contexto específico. Essas anomalias não são necessariamente valores discrepantes quando consideradas isoladamente, mas se tornam anômalas quando vistas dentro de seu contexto específico. Por exemplo, considere o uso de energia. Se houver um aumento repentino no consumo de energia ao meio-dia, quando normalmente nenhum membro da família está em casa. Este dado pode não ser um valor discrepante quando comparado ao consumo de energia pela manhã ou à noite (quando as pessoas geralmente estão em casa), mas é anômalo em relação ao horário em que ocorreu.
A relação correta, na ordem dada, é:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Prova:
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Tecnologia da Informação |
Q3595755
Banco de Dados
Durante a preparação de um conjunto de dados para análise
preditiva de inadimplência, um cientista de dados identificou
diversos problemas de qualidade nos dados, incluindo:
• campos numéricos com valores negativos que não fazem sentido (como "idade" ou "renda");
• colunas categóricas com múltiplas grafias para a mesma categoria (ex: "PE", "pe", "Pernambuco");
• presença de valores nulos em campos-chave como “renda” e “número de dependentes”;
• valores repetidos na chave primária “ID cliente”.
Com base nas dimensões de qualidade de dados e nas boas práticas de tratamento com Python - especialmente usando Pandas -, é correto afirmar que a:
• campos numéricos com valores negativos que não fazem sentido (como "idade" ou "renda");
• colunas categóricas com múltiplas grafias para a mesma categoria (ex: "PE", "pe", "Pernambuco");
• presença de valores nulos em campos-chave como “renda” e “número de dependentes”;
• valores repetidos na chave primária “ID cliente”.
Com base nas dimensões de qualidade de dados e nas boas práticas de tratamento com Python - especialmente usando Pandas -, é correto afirmar que a:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Prova:
FGV - 2025 - TCE-PE - Analista de Controle Externo - Tecnologia da Informação |
Q3594430
Banco de Dados
A mineração de dados é um dos principais componentes do
processo de descoberta de conhecimento em bases de dados (KDD
- Knowledge Discovery in Databases). Seu objetivo é extrair
padrões relevantes, previamente desconhecidos, e
potencialmente úteis a partir de grandes volumes de dados.
Sobre a mineração de dados, assinale a afirmativa correta.
Sobre a mineração de dados, assinale a afirmativa correta.
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Analista de Controle Externo - Contas Públicas
|
FGV - 2025 - TCE-PE - Analista de Controle Externo - Obras Públicas |
FGV - 2025 - TCE-PE - Analista de Controle Externo - Tecnologia da Informação |
Q3593196
Banco de Dados
A Mineração de Dados é a etapa do processo de KDD (Knowledge
Discovery in Databases) responsável por extrair modelos de
conhecimento a partir dos dados disponíveis. Após a construção
desses modelos, é fundamental avaliar sua qualidade, o que exige
compará-los com dados específicos para mensurar métricas que
reflitam seu desempenho. Para garantir uma avaliação imparcial,
os dados utilizados na criação do modelo não devem ser os
mesmos empregados em sua validação. Assim, o processo de KDD
deve utilizar, no mínimo, dois conjuntos distintos de dados: um
conjunto de treinamento, para gerar o modelo, e um conjunto de
testes, para avaliá-lo.
Selecione a opção que identifica o método de particionamento de dados em que o “conjunto de treinamento” é gerado por N sorteios aleatórios com reposição a partir do conjunto de dados original (que contém N registros). Já o “conjunto de testes” é composto pelos registros não selecionados para o “conjunto de treinamento”.
Selecione a opção que identifica o método de particionamento de dados em que o “conjunto de treinamento” é gerado por N sorteios aleatórios com reposição a partir do conjunto de dados original (que contém N registros). Já o “conjunto de testes” é composto pelos registros não selecionados para o “conjunto de treinamento”.
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
Polícia Federal
Provas:
CESPE / CEBRASPE - 2025 - Polícia Federal - Agente de Polícia Federal
|
CESPE / CEBRASPE - 2025 - Polícia Federal - Escrivão de Polícia Federal |
CESPE / CEBRASPE - 2025 - Polícia Federal - Papiloscopista |
Q3530279
Banco de Dados
Julgue o item subsequente, relativos à teoria da informação e a banco de dados.
A mineração de dados é uma técnica em que se utilizam exclusivamente algoritmos de aprendizado supervisionado para a identificação de padrões em grandes volumes de dados; no contexto de Big Data, a premissa principal é a utilização de bancos de dados relacionais tradicionais, que são suficientes para o enfrentamento dos desafios de volume, variedade e velocidade característicos desse ambiente.
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
Polícia Federal
Provas:
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 1: Contábil-Financeira
|
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 2: Engenharia Elétrica/Eletrônica |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 21: Antropologia Forense |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 22: Meio Ambiente |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 16: Física Forense |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 17: Engenharia de Minas |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 20: Engenharia Ambiental |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 19: Genética Forense: |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 3: Informática Forense |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 5: Geologia Forense |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 7: Engenharia Civil |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 11: Engenharia Cartográfica |
CESPE / CEBRASPE - 2025 - Polícia Federal - Perito Criminal Federal - Área 12: Medicina Legal |
Q3530064
Banco de Dados
Acerca de segurança da informação, bancos de dados e aprendizado de máquina, julgue o próximo item.
A técnica de clustering em data mining atribui categorias aos grupos de dados para facilitar a análise e a tomada de decisão.
Ano: 2025
Banca:
INSTITUTO AOCP
Órgão:
TRE-TO
Prova:
INSTITUTO AOCP - 2025 - TRE-TO - Analista Judiciário - Área de Atividade: Apoio Especializado - Especialidade: Tecnologia da Informação |
Q3472935
Banco de Dados
Um analista judiciário especialista em tecnologia
da informação do TRE-TO está atuando em uma
demanda para mais implementações de IA nas
operações do tribunal. Os objetivos dessa tarefa
são oferecer soluções mais práticas e simplificar
e automatizar atividades rotineiras, fazendo com
que a IA atue como uma aliada na tomada de
decisões. Considerando essa situação, a partir do
uso do Banco de Dados Oracle 21C, qual
ferramenta o analista pode utilizar para simplificar
o desenvolvimento de modelos de machine
learning preditivos, auxiliando a escolha do
modelo, a seleção de atributos a serem utilizados
e os ajustes dos parâmetros necessários para a
criação de modelos cada vez mais precisos?
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
STM
Prova:
CESPE / CEBRASPE - 2025 - STM - Analista Judiciário - Área: Apoio Especializado - Especialidade: Suporte em Tecnologia da Informação |
Q3409309
Banco de Dados
Texto associado
Acerca de deep learning, de Big Data e de redes neurais, julgue
o item subsequente.
Em uma rede neural artificial, a função de ativação é
responsável por armazenar os pesos de cada conexão entre os
neurônios para posterior retropropagação.
Ano: 2025
Banca:
CESPE / CEBRASPE
Órgão:
STM
Prova:
CESPE / CEBRASPE - 2025 - STM - Analista Judiciário - Área: Apoio Especializado - Especialidade: Suporte em Tecnologia da Informação |
Q3409307
Banco de Dados
Texto associado
Acerca de deep learning, de Big Data e de redes neurais, julgue
o item subsequente.
O overfitting, em modelos de deep learning, ocorre quando o
modelo tem alta precisão tanto nos dados de treinamento
quanto nos dados de teste, indicativo de que o modelo
generaliza bem.