Questões de Concurso
Sobre modelos lineares em estatística
Foram encontradas 858 questões
Ano: 2025
Banca:
VUNESP
Órgão:
ARSESP
Prova:
VUNESP - 2025 - ARSESP - Especialista em Regulação e Fiscalização de Serviços Públicos - Área de Conhecimento/Ênfases: Econômico-Financeira |
Q3786160
Estatística
Seja o modelo de regressão linear y = β0
+ β1
x, com y = {10, 30, 70, 70, 120}, x = {2, 4, 6, 8, 10} e B̂1 = 13.
O valor estimado de β0 pelo método dos mínimos quadrados ordinais é:
O valor estimado de β0 pelo método dos mínimos quadrados ordinais é:
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Obras e Concessões - tarde |
Q3785588
Estatística
Programa/política avaliada: Faixa Azul – sinalização preferencial
para motociclistas em vias da cidade de São Paulo, com o objetivo
de reduzir sinistros e mortes.
Os pesquisadores avaliaram o impacto da ação sobre os sinistros de trânsito na cidade utilizando métodos de inferência causal… A análise aplica modelos de Diferença-em-Diferenças específicos de adoção escalonada para estimar os efeitos da intervenção. Em todas as especificações, os impactos estimados foram pequenos e estatisticamente indistintos de zero. Se houve efeito, ele foi pequeno a ponto de não ser detectado.
LOUREIRO, Michele. Estudo não encontra relação direta entre Faixa Azul e redução de sinistros em São Paulo. Centro de Estudos das Cidades – Insper, São Paulo, 29 set. 2025.
À luz do método empregado para a avaliação do programa e dos resultados reportados para sinistros/óbitos de motociclistas, assinale a opção que apresenta a conclusão metodologicamente correta.
Os pesquisadores avaliaram o impacto da ação sobre os sinistros de trânsito na cidade utilizando métodos de inferência causal… A análise aplica modelos de Diferença-em-Diferenças específicos de adoção escalonada para estimar os efeitos da intervenção. Em todas as especificações, os impactos estimados foram pequenos e estatisticamente indistintos de zero. Se houve efeito, ele foi pequeno a ponto de não ser detectado.
LOUREIRO, Michele. Estudo não encontra relação direta entre Faixa Azul e redução de sinistros em São Paulo. Centro de Estudos das Cidades – Insper, São Paulo, 29 set. 2025.
À luz do método empregado para a avaliação do programa e dos resultados reportados para sinistros/óbitos de motociclistas, assinale a opção que apresenta a conclusão metodologicamente correta.
Ano: 2025
Banca:
FGV
Órgão:
Prefeitura de Rio de Janeiro - RJ
Prova:
FGV - 2025 - Prefeitura de Rio de Janeiro - RJ - Gestor de Segurança Municipal |
Q3782900
Estatística
Durante uma análise de regressão sobre o impacto de treinamento
em incidentes de segurança, um único funcionário apresentou um
número de incidentes muito acima do padrão. O pesquisador
observou que o coeficiente da variável “horas de treinamento”
mudou drasticamente quando esse funcionário foi removido da
amostra.
Esse comportamento indica que o ponto é
Esse comportamento indica que o ponto é
Ano: 2025
Banca:
FGV
Órgão:
CGE-SP
Prova:
FGV - 2025 - CGE-SP - Auditor Estadual de Controle - Tecnologia da Informação - tarde |
Q3781122
Estatística
Um cientista de dados de uma agência reguladora está
desenvolvendo modelos de Machine Learning para dois
problemas distintos: classificar empresas de alto e baixo risco de
fraude focando na Classificação Binária e prever o valor futuro de
um indicador econômico tendo por base os fundamentos da
Regressão.
Sobre as técnicas de modelagem e avaliação mais adequadas para cada cenário, avalie as afirmativas a seguir.
I. No problema de Classificação Binária com uma base desbalanceada, a métrica do coeficiente de determinação R 2 deve ser priorizada sobre a acurácia.
II. No problema de Regressão, o erro quadrático médio (MSE - Mean Squared Error) é altamente sensível a outliers, e sua raiz quadrada RMSE possui a mesma unidade de medida da variável alvo.
III. O modelo de Regressão Logística é uma técnica de classificação que é adequada para estimar a probabilidade de um evento, mas é incorreto utilizá-lo para prever um valor contínuo como na Regressão.
Está correto o que se afirma em
Sobre as técnicas de modelagem e avaliação mais adequadas para cada cenário, avalie as afirmativas a seguir.
I. No problema de Classificação Binária com uma base desbalanceada, a métrica do coeficiente de determinação R 2 deve ser priorizada sobre a acurácia.
II. No problema de Regressão, o erro quadrático médio (MSE - Mean Squared Error) é altamente sensível a outliers, e sua raiz quadrada RMSE possui a mesma unidade de medida da variável alvo.
III. O modelo de Regressão Logística é uma técnica de classificação que é adequada para estimar a probabilidade de um evento, mas é incorreto utilizá-lo para prever um valor contínuo como na Regressão.
Está correto o que se afirma em
Q3757981
Estatística
Assinale a opção incorreta.
Q3757977
Estatística
Com relação a forma implícita dos modelos de solução do Método
dos Mínimos Quadrados (MMQ), assinale a opção incorreta.
Q3705829
Estatística
Conforme descrito e ilustrado por Guimarães e Hirakata (2012), em modelos
correlacionados é comum se observar um “efeito principal”, que é o efeito direto de uma variável
independente sobre a variável dependente e um “efeito de interação”, que é o efeito conjunto de duas
ou mais variáveis independentes sobre a variável dependente (Fonte: GUIMARÃES, Luciano Santos
Pinto; HIRAKATA, Vânia Naomi. Uso do modelo de equações de estimativas generalizadas na análise
de dados longitudinais. Revista HCPA, Porto Alegre, v. 32, n. 4, p. 503-511, 2012). Considerando um
exemplo genérico, onde se deseja avaliar o efeito do grupo (A ou B) e do tempo (pré, durante e pós
intervenção) na variável escore de ansiedade, relacione a Coluna 1 à Coluna 2, associando as
ilustrações gráficas abaixo aos seus respectivos efeitos.
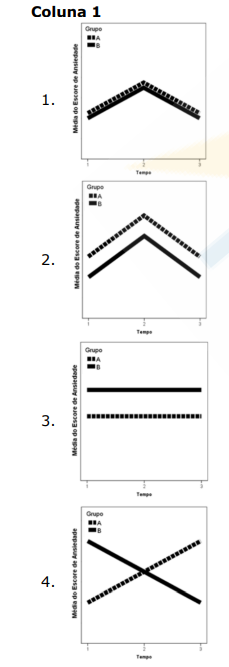
Coluna 2
( ) Efeito somente do tempo. ( ) Efeito somente do grupo. ( ) Efeito do grupo e do tempo. ( ) Efeito do grupo e do tempo com o efeito da interação.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Coluna 2
( ) Efeito somente do tempo. ( ) Efeito somente do grupo. ( ) Efeito do grupo e do tempo. ( ) Efeito do grupo e do tempo com o efeito da interação.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Q3705828
Estatística
As Equações de Estimação Generalizadas (Generalized Estimating Equations – GEE)
foram desenvolvidas com o objetivo de fornecer estimativas consistentes e eficientes dos parâmetros
de modelos de regressão em situações em que os dados apresentam correlação. Esse método tem
sido amplamente empregado em análises de dados longitudinais e outros cenários com medidas
repetidas. Com base nos pressupostos e características dos modelos GEE, assinale a alternativa
correta.
Q3705827
Estatística
Os Modelos de Equações de Estimação Generalizadas (Generalized Estimating
Equations – GEE) não exigem a suposição de esfericidade, pois permitem especificar diretamente a
estrutura de correlação entre medidas repetidas. A matriz de correlação de trabalho (working
correlation matrix) é uma estimativa dessa estrutura de dependência, utilizada para ajustar
corretamente os erros padrão e gerar estimativas robustas dos efeitos populacionais. No SPSS, ao
realizar uma análise GEE, é possível escolher entre cinco opções de matrizes de correlação para ajuste
dos modelos. Nesse contexto, relacione a Coluna 1 à Coluna 2, associando as seguintes matrizes às
suas respectivas características.
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Coluna 1
1. Independente. 2. AR-1 (Autoregressive de 1ª ordem). 3. Troca (Exchangeable). 4. Dependente de ordem m. 5. Não estruturada.
Coluna 2
( ) Assume que a correlação entre quaisquer dois elementos é nula.
( ) Permite uma correlação diferente para cada par de medidas repetidas.
( ) Assume que cada medida repetida só é correlacionada com as m medições anteriores dentro do mesmo sujeito.
( ) Assume que todas as medidas dentro de um sujeito têm a mesma correlação m entre si (correlação homogênea).
( ) A correlação entre quaisquer dois elementos é igual a m para elementos adjacentes, m² para elementos separados por um terceiro e assim por diante, tal que –1 < m < 1.
A ordem correta de preenchimento dos parênteses, de cima para baixo, é:
Q3705826
Estatística
Um estudo clínico tem como objetivo avaliar o efeito de uma intervenção cirúrgica
sobre o peso corporal, verificando se a cirurgia resulta em uma redução significativa do peso em
comparação ao grupo que não foi submetido ao procedimento. Para isso, os pacientes foram divididos
em dois grupos: caso (submetidos à cirurgia) e controle (sem cirurgia). O peso corporal foi mensurado
em dois momentos: antes da cirurgia (peso basal) e três meses após a cirurgia (peso pós-cirurgia),
ou apenas após 3 meses, para o grupo controle. Considere os seguintes planejamentos estatísticos:
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
I. Plano 1 – ANCOVA (Análise de Covariância): Ajusta os valores de peso pós-cirurgia pelo peso basal, controlando eventuais diferenças iniciais entre os grupos. Nesse caso, o peso pós-cirurgia é a variável dependente, o grupo (caso versus controle) é o fator e o peso basal é incluído como covariável.
II. Plano 2 – GEE (Generalized Estimating Equations): Leva em conta a correlação entre medidas repetidas do mesmo indivíduo, permitindo estimar efeitos da cirurgia, do tempo e a variabilidade entre os pacientes. Considera as medidas repetidas de peso ao longo do tempo como variáveis dependentes, grupo (caso versus controle) e tempo (basal e pós-cirúrgico) como fatores.
III. Plano 3 – Test t pareado: Compara o peso basal e o peso pós-cirurgia dentro de cada grupo, separadamente. O peso é a variável dependente, o tempo (basal e pós-cirúrgico) é o fator de comparação.
Quais assertivas apresentam planejamentos que oferecem análises que permitem verificar estatisticamente se a cirurgia promove uma redução significativa no peso em comparação ao grupo controle?
Q3705823
Estatística
Considere o modelo de regressão linear simples: yi = a + bxi + ei com i = 1, …, n,
tal que ei é o componente aleatório de yi . Sobre as suposições necessárias para que os estimadores
de mínimos quadrados ordinários (MQO) sejam eficientes, assinale a alternativa correta.
Q3705822
Estatística
Texto associado
Um professor de educação física elaborou 2 programas de treino (programa A e
programa B) e quer aplicar em um grupo de 24 alunos, a fim de testar suas eficiências
quanto ao ganho de resistência em um determinado período de tempo. Entretanto, ele
percebeu que, entre esses 24 alunos, existem 3 níveis de condicionamento físico (baixo,
médio e alto). Para controlar essa fonte de variação, o professor estratificou os alunos por
nível de condicionamento e, em cada nível, selecionou aleatoriamente 4 alunos para o
Programa A e 4 alunos para o Programa B, de modo que cada nível contém o mesmo número
de observações por treino.
Considere, ainda, que o ganho de resistência dos alunos será avaliado pela diferença entre
a distância percorrida em 12 minutos de caminhada/corrida, medida antes e após o período
de treinamento.
Os dados coletados incluem:
• Aluno: Identificador do aluno.
• Programa: A ou B.
• Nível: Baixo, médio ou alto.
• Resistência: Diferença entre a distância percorrida antes e após o período de treinamento.
Considerando o desenho experimental descrito anteriormente, para saber se existe
diferença significativa entre os programas, a 5% de significância, o professor utilizou o código e a
saída de resultados a seguir, em linguagem R (supondo que todos os pressupostos são atendidos):

Com base no código e nos resultados observados, analise as assertivas abaixo e assinale a alternativa correta.
I. A estatística de teste F, para comparar os programas, pode ser calculada a partir da soma dos quadrados e dos graus de liberdade, tal que F = 18,60, aproximadamente.
II. Se a hipótese nula for verdadeira, o valor de F tende a 1. Mas se a hipótese nula for falsa, o valor de F tende a ser maior que 1.
III. Mesmo com valor de p <0,05, para avaliar o efeito do programa, ainda é necessário o uso de testes “pós-ANOVA”, também conhecidos como testes post-hoc, para identificar qual programa apresentou maior ganho de resistência.
IV. O erro residual estimado (Residual standard error = 20.63461) indica a variabilidade média explicada pelo modelo.
Com base no código e nos resultados observados, analise as assertivas abaixo e assinale a alternativa correta.
I. A estatística de teste F, para comparar os programas, pode ser calculada a partir da soma dos quadrados e dos graus de liberdade, tal que F = 18,60, aproximadamente.
II. Se a hipótese nula for verdadeira, o valor de F tende a 1. Mas se a hipótese nula for falsa, o valor de F tende a ser maior que 1.
III. Mesmo com valor de p <0,05, para avaliar o efeito do programa, ainda é necessário o uso de testes “pós-ANOVA”, também conhecidos como testes post-hoc, para identificar qual programa apresentou maior ganho de resistência.
IV. O erro residual estimado (Residual standard error = 20.63461) indica a variabilidade média explicada pelo modelo.
Q3705821
Estatística
Texto associado
Um professor de educação física elaborou 2 programas de treino (programa A e
programa B) e quer aplicar em um grupo de 24 alunos, a fim de testar suas eficiências
quanto ao ganho de resistência em um determinado período de tempo. Entretanto, ele
percebeu que, entre esses 24 alunos, existem 3 níveis de condicionamento físico (baixo,
médio e alto). Para controlar essa fonte de variação, o professor estratificou os alunos por
nível de condicionamento e, em cada nível, selecionou aleatoriamente 4 alunos para o
Programa A e 4 alunos para o Programa B, de modo que cada nível contém o mesmo número
de observações por treino.
Considere, ainda, que o ganho de resistência dos alunos será avaliado pela diferença entre
a distância percorrida em 12 minutos de caminhada/corrida, medida antes e após o período
de treinamento.
Os dados coletados incluem:
• Aluno: Identificador do aluno.
• Programa: A ou B.
• Nível: Baixo, médio ou alto.
• Resistência: Diferença entre a distância percorrida antes e após o período de treinamento.
Analisando as diferentes metodologias de Análise de Variância (ANOVA), a técnica
mais indicada para análise do desenho experimental descrito acima (supondo que todos os
pressupostos são atendidos) é:
Q3673439
Estatística
A regressão linear simples e a regressão linear múltipla são modelos econométricos que podem ser utilizados
para a previsão de variáveis (dependentes = y) a partir da relação significante com outras variáveis
(independentes = x). Para o uso ideal de um modelo desse tipo no sentido de se ter a previsão de algum
aspecto financeiro, como receita ou despesas, deve-se tomar como base algumas premissas, como, por
exemplo:
Q3662536
Estatística
Um pesquisador realizou um ajuste de modelo de regressão linear simples. Abaixo está a saída do código executado no software R:

De acordo com a saída do código, qual a alternativa CORRETA?
Q3662533
Estatística
Um modelo de regressão logística tem a função de ligação dada por:

Q3662532
Estatística
Um pesquisador educacional coletou dados sobre a relação entre o número de horas de estudo por semana (x) e a nota final em um exame (y). Os dados seguem abaixo:

Ajustando um modelo de regressão linear simples aos dados, os valores estimados do Intercepto (alpha) e coeficiente angular (beta) usando o método de mínimos quadrados são dados, respectivamente, por
Ano: 2025
Banca:
FGV
Órgão:
AgSUS
Prova:
FGV - 2025 - AgSUS - Analista de Gestão Tecnologia da Informação |
Q3660470
Estatística
O uso de técnicas de análise de regressão são amplamente
utilizadas na estatística para prever resultados com base em um
conjunto de variáveis de entrada.
Com relação às características da Regressão linear e da Regressão logística, analise os itens a seguir:
I. As duas técnicas buscam modelar a relação entre variáveis dependentes e independentes, no entanto, apresentam como principal diferença o tipo de variável que elas são capazes de prever.
II. A regressão linear minimiza as discrepâncias entre os valores de saída previstos e reais ao ajustar uma probabilidade, onde a variável dependente é limitada entre 0 e 1.
III. Ambos os tipos de regressões requerem um tamanho de amostra adequado e grande, de mesma dimensão, para representar valores em todas as categorias de resposta produzindo modelo com poder estatístico suficiente para detectar efeito significativo.
Está correto o que se afirma em
Com relação às características da Regressão linear e da Regressão logística, analise os itens a seguir:
I. As duas técnicas buscam modelar a relação entre variáveis dependentes e independentes, no entanto, apresentam como principal diferença o tipo de variável que elas são capazes de prever.
II. A regressão linear minimiza as discrepâncias entre os valores de saída previstos e reais ao ajustar uma probabilidade, onde a variável dependente é limitada entre 0 e 1.
III. Ambos os tipos de regressões requerem um tamanho de amostra adequado e grande, de mesma dimensão, para representar valores em todas as categorias de resposta produzindo modelo com poder estatístico suficiente para detectar efeito significativo.
Está correto o que se afirma em
Ano: 2025
Banca:
FGV
Órgão:
AgSUS
Prova:
FGV - 2025 - AgSUS - Analista de Gestão Tecnologia da Informação |
Q3660447
Estatística
Em relação a regressão logística, analise as afirmativas a seguir.
I. É uma forma especializada de regressão que é formulada para prever e explicar uma variável categórica binária e, não uma medida dependente métrica.
II. Os modelos lineares generalizados podem ser considerados como uma abordagem de modelagem de dois estágios. Primeiro se modela a variável de resposta usando uma distribuição de probabilidade, como a distribuição binomial ou de Poisson e segundo se modela o parâmetro da distribuição usando uma coleção de preditores e uma forma especial de rede neural.
III. A regressão logística por ser usado como uma ferramenta para construir modelos quando existe uma variável de resposta categórica com três níveis. A regressão logística é um tipo de modelo linear não generalizado para variáveis de resposta onde a regressão linear múltipla não funciona muito bem.
Estão corretas as afirmativas
I. É uma forma especializada de regressão que é formulada para prever e explicar uma variável categórica binária e, não uma medida dependente métrica.
II. Os modelos lineares generalizados podem ser considerados como uma abordagem de modelagem de dois estágios. Primeiro se modela a variável de resposta usando uma distribuição de probabilidade, como a distribuição binomial ou de Poisson e segundo se modela o parâmetro da distribuição usando uma coleção de preditores e uma forma especial de rede neural.
III. A regressão logística por ser usado como uma ferramenta para construir modelos quando existe uma variável de resposta categórica com três níveis. A regressão logística é um tipo de modelo linear não generalizado para variáveis de resposta onde a regressão linear múltipla não funciona muito bem.
Estão corretas as afirmativas
Ano: 2025
Banca:
FGV
Órgão:
AgSUS
Prova:
FGV - 2025 - AgSUS - Analista de Gestão Tecnologia da Informação |
Q3660446
Estatística
Matheus é um professor que precisa identificar padrões de
utilização de LLMs (Large Language Models) em um grupo de
estudantes. Ele utilizou como dados as notas finais da avaliação da
disciplina de Estatística Básica (com distribuição das notas
variando 0 a 100) e correlacionou esses dados à quantidade de
horas dedicadas ao uso de LLMs pelos estudantes durante o
semestre. O professor construiu um modelo para prever a
pontuação de um aluno (Y), em função do número de horas
dedicadas ao LLMs durante o último semestre (X), obtendo o
modelo a seguir.
Ŷ = 100 − 0, 25x
Matheus certificou-se que o modelo atende a todas as premissas do modelo de regressão linear. As pontuações esperadas para dois alunos que dedicaram 300 horas e 50 horas ao uso de LLMs no último semestre são, respectivamente,
Ŷ = 100 − 0, 25x
Matheus certificou-se que o modelo atende a todas as premissas do modelo de regressão linear. As pontuações esperadas para dois alunos que dedicaram 300 horas e 50 horas ao uso de LLMs no último semestre são, respectivamente,