Questões de Concurso
Sobre conhecimentos de estatística em estatística
Foram encontradas 1.223 questões
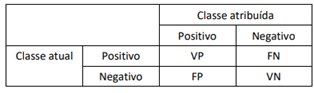
Com relação ao cálculo das medidas de desempenho, analise as afirmativas a seguir.
I. A medida da especificidade (também conhecido por Taxa de verdadeiros negativos) pode ser alcançada através da fórmula: Especificidade = VN / (VN + FP).
II. A medida da sensibilidade (também conhecido por Taxa de verdadeiros positivos ou Recall) pode ser alcançada através da fórmula: Recall = VP / (VP + FN).
III. O valor preditivo positivo (também conhecido como Precisão) pode ser alcançada através da fórmula: Precisão = VN / (VN + FN)
IV. Por fim, O valor preditivo negativo (VPN) pode ser alcançada através da fórmula: VPN = VP / (VP + FP).
Está correto o que se afirma em
I. Os dados figuram como o elemento central. O objetivo é extrair desses toda informação possível para que se possam tomar decisões e antecipar resultados de maneira precisa.
II. Não é campo de conhecimento alheio às outras ciências. Ao contrário, que se trata de uma combinação de instrumentos fornecidos por diversos campos do saber, com destaque para a Estatística e a Ciência da Computação.
III. CD lida exclusivamente com a análise de dados estruturados, como planilhas e bancos de dados SQL, focando apenas em visualizações básicas e relatórios descritivos.
Está correto o que se afirma em
O gráfico de equidade abaixo apresenta, para cada ano do Ensino Fundamental, a distribuição da proficiência ponderada em Língua Portuguesa na última ADR do município, edição 2025.3. Em cada boxplot, o traço dentro da caixa representa a mediana, e os símbolos na legenda indicam o padrão de desempenho: Defasagem, Intermediário e Adequado.
Distribuição da Proficiência em Língua Portuguesa por ano escolar (1º ao 9º EF) e Nível de Aprendizagem
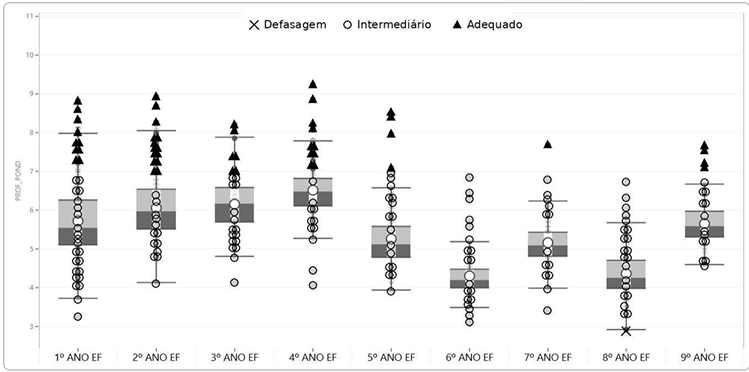
Disponível em: https://sites.google.com/educacao.fortaleza.ce.gov.br/painelsme/. Acesso em: 30 dez. 2025.
Descrição do gráfico: O gráfico intitulado “Distribuição da Proficiência em Língua Portuguesa por ano escolar (1º ao 9º EF) e Nível de Aprendizagem” compara a distribuição da proficiência do 1º ao 9º ano do EF usando boxplots (caixas com mediana) e pontos individuais. A classificação dos pontos é por forma: ✕ Defasagem, ○ Intermediário e ▲ Adequado (legenda no topo). Em geral, do 1º ao 4º ano há medianas mais altas e vários ▲ acima de 7– 8 (com destaque para o 4º ano). O 5º ano cai um pouco. Os menores níveis aparecem no 6º e no 8º ano (medianas perto de 4 – 4,5), e, no 8º, há um ✕ próximo de 3. O 7º fica intermediário e o 9º volta a subir com mais pontos ▲ acima de 7.
Considerando apenas a mediana de cada boxplot, em qual ano o município apresenta o maior nível central de proficiência?
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Com base nas boas práticas de avaliação de modelos de aprendizado de máquina, inclusive em cenários com classes desbalanceadas, analise as afirmativas a seguir, considerando (V) para a(s) afirmativa(s) verdadeira(s) e (F) para a(s) falsa(s).
( ) Na validação cruzada k-fold estratificada, cada partição de treino e teste preserva aproximadamente a mesma proporção de classes do conjunto original, o que contribui para estimativas de desempenho mais estáveis em problemas com desbalanceamento de classes.
( ) Curvas ROC e a métrica AUC-ROC são tipicamente mais informativas do que curvas precision-recall em cenários com classes fortemente desbalanceadas, justamente porque destacam com maior sensibilidade o comportamento do classificador em relação à classe minoritária.
( ) A métrica F1-score corresponde ao dobro do produto entre precisão (precision) e sensibilidade (recall) dividido pela soma de ambos, de modo que valores muito discrepantes entre precisão e recall tendem a produzir um F1-score relativamente baixo.
( ) Ao diminuir o limiar de decisão de um classificador binário (por exemplo, de 0,7 para 0,3), a precisão tende a aumentar, pois mais exemplos positivos são corretamente identificados como tal, ainda que isso geralmente ocorra às custas de uma redução no recall.
A sequência correta é:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
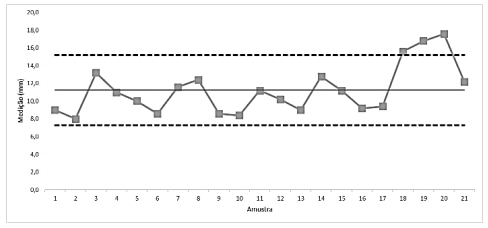
Com base no gráfico apresentado, analise os itens a seguir:
I. O processo pode ser considerado estável até a medição 17, pois, neste intervalo, a variabilidade está contida dentro dos limites de controle, indicando que apenas as causas comuns inerentes ao processo estão em atuação.
II. As variações observadas nas medições 18, 19 e 20 são evidências da ocorrência de causas especiais, que não pertencem ao contexto usual do processo, tornando-o instável e exigindo a intervenção do operador ou supervisor para correção imediata.
III. De acordo com os princípios do CEP (Controle por Prevenção), as anomalias detectadas entre as medições 18 e 20 devem ser tratadas por meio de uma inspeção após a conclusão de todo o ciclo produtivo, para comparação com as especificações e subsequente rejeição ou retrabalho.
Está correto o que se afirma em
A taxa de frequência e de gravidade são, respectivamente,
Segundo conceitos estatísticos, essa sequência dos parâmetros citados corresponde, respectivamente, a variáveis
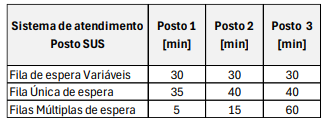
Com base na análise dos dados, assinale a alternativa INCORRETA:
Assinale a alternativa que completa, correta e respectivamente, as lacunas do texto.
• turma A (10 alunos): 7, 8, 5, 9, 7, 6, 8, 10, 5, 5.
• turma B (10 alunos): 6, 7, 8, 6, 9, 7, 7, 8, 6, 6.
Com base nesses dados, a respeito das notas das turmas A e B, assinale a alternativa correta.
I- É a única medida de tendência central que sempre assume valores inteiros, mesmo quando aplicada a variáveis discretas.
II- É determinada pela divisão da soma de todos os valores de um conjunto de dados pelo número total de observações.
III- Trata-se de uma medida de tendência central insensível a valores extremos, motivo pelo qual não é recomendada para distribuições simétricas.
Assinale CORRETAMENTE:
Acerca da análise estatística deste conjunto de dados, marque V, para as afirmativas verdadeiras, e F, para as falsas:
(__)A média aritmética do tempo de pausa é exatamente 15 minutos, indicando que a distribuição é perfeitamente simétrica.
(__)O conjunto de dados é bimodal, apresentando duas modas distintas, 10 minutos e 12 minutos.
(__)A mediana, que representa o valor central do conjunto ordenado, é 15 minutos.
(__)A moda deste conjunto é 10 minutos, e a mediana é 12 minutos, sendo a média superior à mediana.
Após análise, assinale a alternativa que apresenta a sequência correta dos itens acima, de cima para baixo:
Acerca desta situação e dos cálculos de probabilidade envolvidos, marque V, para as afirmativas verdadeiras, e F, para as falsas:
(__) A probabilidade de um indivíduo não doente testar positivo (taxa de Falso Positivo) é de 2%.
(__) Se um indivíduo testa positivo, a probabilidade de ele estar realmente doente é superior a 90%, dada a alta sensibilidade do teste.
(__) A probabilidade de um indivíduo doente testar negativo (taxa de Falso Negativo) é de 5%.
(__) A probabilidade de um indivíduo selecionado aleatoriamente estar doente E testar positivo (Verdadeiro Positivo) é de 0,49%.
Após análise, assinale a alternativa que apresenta a sequência correta dos itens acima, de cima para baixo:
Acerca da análise estatística deste conjunto de dados, marque V, para as afirmativas verdadeiras, e F, para as falsas:
(__) A média aritmética do tempo de pausa é exatamente 15 minutos, indicando que a distribuição é perfeitamente simétrica.
(__) O conjunto de dados é bimodal, apresentando duas modas distintas, 10 minutos e 12 minutos.
(__) A mediana, que representa o valor central do conjunto ordenado, é 15 minutos.
(__) A moda deste conjunto é 10 minutos, e a mediana é 12 minutos, sendo a média superior à mediana.
Após análise, assinale a alternativa que apresenta a sequência correta dos itens acima, de cima para baixo: