Questões de Concurso Sobre estatística
Foram encontradas 14.291 questões
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Jornalista Web |
Q3332251
Estatística
Histogramas têm sido um dos recursos usados para
visualização de dados. Eles são diferentes de gráficos de
barras porque:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Citometria de fluxo |
Q3331594
Estatística
A análise que pode ser realizada para se calcular a
imprecisão de um resultado laboratorial é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331509
Estatística
Considere a seguinte implementação de um modelo de
regressão linear múltipla utilizando NumPy e scikit-learn,
usado para prever o financiamento de projetos com base
em características de projetos e pesquisadores. O código
abaixo foi executado e algumas métricas de desempenho
foram obtidas.
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331324
Estatística
Uma das dificuldades de se realizar agrupamentos de
dados é a definição do número de grupos. É correto afirmar
que contém apenas técnicas ou métricas que podem ser
úteis para automatizar a decisão do número K de grupos:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331323
Estatística
Sobre o algoritmo K-médias, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331322
Estatística
Dentre as seguintes listas, NÃO contêm apenas algoritmos que podem ser usados para realizar uma regressão, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331315
Estatística
São algoritmos de classificação, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331313
Estatística
Considere o problema de calcular agrupamentos dos
objetos apresentados na figura abaixo:
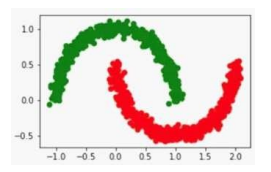
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331303
Estatística
Em muitas situações precisamos trabalhar com dados
muito volumosos. Imagine que se queira saber a média de
altura de todas as pessoas vivas no mundo e não houvesse
uma maneira factível de medir todas as pessoas (população). Usualmente, extraímos um conjunto de dados menor
mas representativo e então analisamos este subconjunto
(amostra). Medimos alguns milhares de pessoas e esperamos que essa medida possa ser próxima o bastante da
medida que obteríamos se medíssemos todo mundo. Para
que essa medida seja confiável, precisamos calcular o intervalo de confiança. Para isto, precisamos selecionar diversas
amostras da população. Este tipo de técnica é chamada de:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331302
Estatística
Em relação a coleções de valores aleatórios gerados a
partir de distribuições de probabilidade:
I. Se selecionamos um valor, em seguida outro e outro formando uma lista, sua média é o valor esperado.
II. Variáveis independentes são aquelas que não dependem das outras variáveis ou seja não se influenciam.
III. Muitos algoritmos de aprendizado de máquina requerem variáveis independentes e identicamente distribuídas ou seja selecionadas da mesma distribuição.
De cima para baixo, a sequência correta é:
I. Se selecionamos um valor, em seguida outro e outro formando uma lista, sua média é o valor esperado.
II. Variáveis independentes são aquelas que não dependem das outras variáveis ou seja não se influenciam.
III. Muitos algoritmos de aprendizado de máquina requerem variáveis independentes e identicamente distribuídas ou seja selecionadas da mesma distribuição.
De cima para baixo, a sequência correta é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331299
Estatística
Em relação ao nosso sistema de percepção visual e
cognição, é INCORRETO afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331298
Estatística
Quando analisamos dados visualmente, buscamos
encontrar e compreender as partes da informação e como
elas se relacionam com outras. Por exemplo, em uma série
temporal, visamos analisar como determinadas variáveis
se relacionam com a variável tempo. Um análise de parte-todo ilustra como as partes se relacionam entre si e com
o todo. Séries temporais e parte-todo são dois exemplos
de relacionamentos quantitativos clássicos que podem ser
visualizados através de técnicas de visualização.
A coluna I mostra os relacionamentos quantitativos e a coluna II as técnicas de visualização. Estabeleça a correta correspondência entre as colunas I e II.
Coluna I
1. Série temporal. 2. Parte-todo.
Coluna II
( ) gráfico de linhas. ( ) gráfico de pizza. ( ) treemap. ( ) gráfico de radar. ( ) gráfico de marimekko.
A sequência correta, de cima para baixo, é:
A coluna I mostra os relacionamentos quantitativos e a coluna II as técnicas de visualização. Estabeleça a correta correspondência entre as colunas I e II.
Coluna I
1. Série temporal. 2. Parte-todo.
Coluna II
( ) gráfico de linhas. ( ) gráfico de pizza. ( ) treemap. ( ) gráfico de radar. ( ) gráfico de marimekko.
A sequência correta, de cima para baixo, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331293
Estatística
Em relação à maldição da dimensionalidade, avalie se
são verdadeiras (V) ou falsas (F) as afirmativas a seguir:
I. Refere-se ao fenômeno de que muitos tipos de análises de dados se tornam mais difíceis a medida que a dimensionalidade de dados diminui.
II. Para tarefas de classificação, significa que não há instâncias de dados suficientes para criar um modelo que atribua de forma confiável a classe real das instâncias.
III. Quando a dimensionalidade cresce, os dados se tornam cada vez menos esparsos no espaço.
As afirmativas I, II e III são respectivamente:
I. Refere-se ao fenômeno de que muitos tipos de análises de dados se tornam mais difíceis a medida que a dimensionalidade de dados diminui.
II. Para tarefas de classificação, significa que não há instâncias de dados suficientes para criar um modelo que atribua de forma confiável a classe real das instâncias.
III. Quando a dimensionalidade cresce, os dados se tornam cada vez menos esparsos no espaço.
As afirmativas I, II e III são respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331291
Estatística
É correto afirmar que os dois tipos de variáveis são
quantitativas:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Bioinformática |
Q3331212
Estatística
A escolha entre usar um teste de hipótese paramétrico
ou não paramétrico depende das características dos dados
e dos objetivos da análise. Por exemplo, se as suposições
para um teste paramétrico são atendidas, prefere-se usar
esses testes devido ao seu maior poder estatístico. Em relação aos testes de hipóteses, é INCORRETO afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - ecnologia da informação e comunicação (TIC) com foco em análise e desenvolvimento de sistema |
Q3331037
Estatística
É INCORRETO afirmar que os modelos preditivos:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - ecnologia da informação e comunicação (TIC) com foco em análise e desenvolvimento de sistema |
Q3331020
Estatística
No contexto da tarefa de aprendizagem não-supervisionada conhecida como clusterização é correto
afirmar que a abordagem:
Ano: 2024
Banca:
IDCAP
Órgão:
Prefeitura de Serra - ES
Prova:
IDCAP - 2024 - Prefeitura de Serra - ES - Estatístico |
Q3329935
Estatística
Considere uma pesquisa realizada para estimar a média de uma característica em uma grande população. Qual das seguintes afirmações sobre métodos de amostragem e estimadores está correta?
Ano: 2024
Banca:
IDCAP
Órgão:
Prefeitura de Serra - ES
Prova:
IDCAP - 2024 - Prefeitura de Serra - ES - Estatístico |
Q3329933
Estatística
Em um hospital foi feito um estudo estatístico com os índices de recuperação de centenas de pacientes. Verificou-se que o índice médio de recuperação dos pacientes era 6,0 com um desvio padrão de 2,0. Assinale a alternativa que indica o valor Z da variável aleatória normal padronizada para um índice de recuperação igual a 8,0.
Ano: 2024
Banca:
IDCAP
Órgão:
Prefeitura de Serra - ES
Prova:
IDCAP - 2024 - Prefeitura de Serra - ES - Estatístico |
Q3329931
Estatística
José Renato irá participar de um jogo de dados. O dado é honesto e possui 6 faces numeradas de 1 a 6. O jogo funciona assim: 1.José Renato irá escolher um número X. 2.O dado será lançado aleatoriamente n vezes. 3.José Renato vence o jogo se ao final dos n lançamentos tenham sido sorteado o seu número X pelo menos k vezes. Assinale a expressão que indica a probabilidade de José Renato vencer este jogo.