Questões de Concurso
Para tribunal
Foram encontradas 191.597 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
De acordo com os princípios do COBIT® 2019, para garantir a qualidade dos dados analíticos, um sistema de governança deve:
O princípio da LGPD especificamente observado pelo módulo B é o da:
Ao levar esse fato ao gerente de projetos, a equipe usou o PMBOK para justificar as alterações com base no princípio do(a):
A equipe ágil deve lidar com essa demanda:
O conjunto está fortemente desbalanceado: apenas 3% dos registros pertencem à classe denominada inadimplente. O time deseja aumentar a quantidade de exemplos da classe minoritária sem simplesmente duplicar registros existentes, gerando novas amostras sintéticas entre os pontos reais da classe positiva, para reduzir o risco de overfitting associado ao oversampling ingênuo.
A técnica de balanceamento de classes adequada para esse cenário é:
Para contornar essa limitação, os cientistas de dados decidiram utilizar um modelo de arquitetura robusta (como a ResNet-50), que já foi previamente treinado em milhões de imagens genéricas do banco de dados ImageNet. A estratégia adotada consiste em manter os pesos das camadas iniciais da rede inalterados (congelados), aproveitando a capacidade do modelo de reconhecer formas e texturas, e treinar apenas as últimas camadas para distinguir a lesão de pele específica.
Essa técnica de reaproveitamento de conhecimento prévio de um domínio para resolver um problema em outro domínio com poucos dados é denominada:
A avaliação dessa metodologia de validação é:
Nesse contexto, relacione os tipos de dados às suas respectivas descrições.
1. Dados estruturados
2. Dados semiestruturados
3. Dados não estruturados
( ) Gravações em áudio e vídeo de audiências públicas, armazenadas em arquivos MP4, acompanhadas apenas de nome do arquivo e data de criação.
( ) Registros de protocolo eletrônico armazenados em tabelas de banco de dados relacional, com campos bem definidos (número do processo, data, unidade, assunto) e chaves primárias/estrangeiras.
( ) Arquivos de log de acesso ao portal de serviços do governo, registrados em formato JSON, contendo campos como timestamp, user_id, endpoint, status_code, com alguns campos opcionais variando conforme o tipo de requisição.
A sequência correta é:
Um tribunal deseja prever o tempo de tramitação (em dias) de processos de uma determinada classe, desde a distribuição até a sentença em 1ª instância. Um cientista de dados ajustou um modelo de regressão usando variáveis como tipo de ação, vara, quantidade de partes e histórico de movimentações, e avaliou o modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
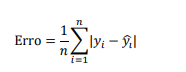
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
O pipeline inclui as seguintes etapas:
(1) ingestão de dados em tempo real via streaming;
(2) feature engineering com agregações temporais (médias móveis de 7 e 30 dias);
(3) predição usando um modelo de gradient boosting;
(4) deployment em arquitetura de microsserviços.
Após três meses em produção, o time de MLOps observou degradação gradual no F1-score de 0.89 para 0.72, enquanto o monitoramento revelou que as distribuições das features agregadas apresentavam mudanças estatisticamente significativas (p < 0.01 no teste de Kolmogorov-Smirnov), embora as features brutas individuais permanecessem estáveis.
Considerando as melhores práticas de pipelines de ML em produção e estratégias de deployment, a equipe deve:
Diante desse cenário, é correto afirmar que o modelo:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
A principal diferença conceitual entre essas duas abordagens reside no fato de que, no aprendizado supervisionado:
Considerando os impactos dessa decisão de projeto e os fundamentos da modelagem de dados, é correto afirmar que:
O administrador de banco de dados (DBA), preocupado com a integridade dos dados e o espaço de armazenamento, propôs que essa hierarquia fosse modelada seguindo os princípios da normalização. Segundo a proposta, a tabela de produtos conteria apenas o ID da subcategoria, que apontaria para uma tabela de subcategorias, que, por sua vez, apontaria para uma tabela de categorias, e assim sucessivamente, evitando a repetição de textos descritivos (como o nome do departamento) em milhões de linhas de produtos.
Considerando os conceitos de modelagem dimensional (Ralph Kimball) e o impacto dessa decisão na performance de consultas analíticas (OLAP), é correto afirmar que:
• Transacional e BI: o sistema de vendas gera registros financeiros que exigem consistência estrita (ACID). A equipe de analistas de negócios consome esses dados via painéis de BI que demandam baixa latência em consultas complexas com múltiplas junções (joins).
• Big Data e IA: o sistema de e-commerce gera petabytes de logs de navegação (clickstream) e dados de sensores IoT das lojas físicas (dados semiestruturados). A equipe de ciência de dados precisa acessar esses dados em seu formato bruto para treinar modelos preditivos, sem a perda de informações causada por agregações prematuras.
O arquiteto de dados precisa propor uma solução única que evite a duplicação de dados entre silos (um Data Warehouse para o BI e um Data Lake para a IA) e reduza o custo de armazenamento, mantendo a governança.
Considerando os requisitos apresentados e as características das arquiteturas modernas de dados, a abordagem arquitetural e de modelagem adequada é:
Um administrador de segurança está configurando uma ACL em um roteador Cisco IOS para filtrar tráfego malicioso. A política de segurança determina que apenas os hosts da sub-rede 10.50.0.0/24 cujo último octeto seja ímpar (por exemplo, 10.50.0.1, 10.50.0.3, 10.50.0.5 etc.) possam acessar o servidor financeiro no IP 172.16.1.10, para qualquer protocolo IP.
Considere o seguinte comando de ACL, em que deve ser preenchida apenas a máscara curinga da origem:
>access-list 101 permit ip 10.50.0.1 [wildcard mask] host 172.16.1.10
A máscara curinga (Wildcard Mask) correta para casar, em uma única instrução, exatamente todos os endereços da sub-rede 10.50.0.0/24 cujo último octeto é ímpar é:
S* 0.0.0.0/0 [1/0] via 200.10.10.1 (ISP1) O 0.0.0.0/0 [110/20] via 201.20.20.1 (ISP2) C 10.10.0.0/16 is directly connected, ETH0/0 C 192.168.100.0/24 is directly connected, ETH0/0
Considere que não há outras rotas mais específicas para destinos externos.
Quando um host da rede 192.168.100.0/24 envia um pacote para o endereço 8.8.8.8, o comportamento esperado de encaminhamento nesse roteador, de acordo com os critérios de escolha de rota em roteadores tradicionais, é que o pacote será:
A arquitetura de armazenamento projetada para atender a esses requisitos de escalabilidade web e acesso via API é conhecida como: