Questões de Concurso Sobre programação
Foram encontradas 15.002 questões
Ano: 2025
Banca:
INSTITUTO AOCP
Órgão:
MPE-RS
Prova:
INSTITUTO AOCP - 2025 - MPE-RS - Analista do Ministério Público - Informática |
Q3991678
Programação
Na linguagem de programação JavaScript, com
operação e utilização de array, qual é o nome da
função, considerando apenas seu nome e não sua
sintaxe completa, que consiste em adicionar um
valor, variável ou objeto na primeira posição de
um array, fazendo com que todos os outros
valores avancem uma posição à frente?
Ano: 2025
Banca:
INSTITUTO AOCP
Órgão:
MPE-RS
Prova:
INSTITUTO AOCP - 2025 - MPE-RS - Analista do Ministério Público - Informática |
Q3991658
Programação
Um analista de tecnologia da informação está
trabalhando com aprendizado de máquina
utilizando a ferramenta TensorFlow. Com essa
ferramenta, é possível operar matrizes ou
tensores multidimensionais, tendo como um de
seus atributos o Tensor.shape, o qual
Ano: 2025
Banca:
INSTITUTO AOCP
Órgão:
IF-PB
Prova:
INSTITUTO AOCP - 2025 - IF-PB - Analista de Tecnologia da Informação |
Q3986319
Programação
No âmbito da Extensible Markup Language (XML),
um elemento é a unidade fundamental de estrutura
e armazenamento de dados. Ele deve ser formado
por uma tag de abertura, um conteúdo e uma tag
de fechamento.
Assinale a alternativa que apresenta corretamente um exemplo válido de elemento XML.
Assinale a alternativa que apresenta corretamente um exemplo válido de elemento XML.
Ano: 2025
Banca:
INSTITUTO AOCP
Órgão:
IF-PB
Prova:
INSTITUTO AOCP - 2025 - IF-PB - Analista de Tecnologia da Informação |
Q3986317
Programação
PHP, Java e Python são linguagens amplamente
utilizadas no desenvolvimento de sistemas, cada
uma com características próprias em relação à
forma de execução, à tipagem, ao paradigma e aos
recursos de escrita de código. Acerca dessas
linguagens, informe se é verdadeiro (V) ou falso (F)
o que se afirma a seguir e assinale a alternativa
com a sequência correta.
( ) PHP é uma linguagem de script interpretada em tempo de execução pelo servidor, sem necessidade de compilação prévia para geração de bytecode.
( ) Java não é uma linguagem fortemente tipada, não exigindo declaração explícita de tipos e verificação em tempo de compilação.
( ) Python é considerada uma linguagem multiparadigma, oferecendo suporte à programação orientada a objetos, funcional e procedural.
( ) PHP, Java e Python não possuem suporte nativo para inclusão de comentários no código, exigindo ferramentas externas para documentação.
( ) PHP é uma linguagem de script interpretada em tempo de execução pelo servidor, sem necessidade de compilação prévia para geração de bytecode.
( ) Java não é uma linguagem fortemente tipada, não exigindo declaração explícita de tipos e verificação em tempo de compilação.
( ) Python é considerada uma linguagem multiparadigma, oferecendo suporte à programação orientada a objetos, funcional e procedural.
( ) PHP, Java e Python não possuem suporte nativo para inclusão de comentários no código, exigindo ferramentas externas para documentação.
Ano: 2025
Banca:
LEGALLE Concursos
Órgão:
TCE-SP
Prova:
LEGALLE Concursos - 2025 - TCE-SP - Auditor de Controle Externo - Processo de Promoção 2023 |
Q3970427
Programação
Theano é uma biblioteca Python criada pela
Universidade de Montreal para computação científica. A
biblioteca permite a definição, otimização e análise de
expressões matemáticas envolvendo matrizes
multidimensionais de forma eficiente. Analise as principais
funcionalidades do Theano nas seguintes assertivas:
l. lntegração com a biblioteca NumPy.
ll. Diferenciação simbólica eficiente.
lll. Execução em CPU.
Está(áo) CORRETA(S)
l. lntegração com a biblioteca NumPy.
ll. Diferenciação simbólica eficiente.
lll. Execução em CPU.
Está(áo) CORRETA(S)
Ano: 2025
Banca:
VUNESP
Órgão:
UEA
Prova:
VUNESP - 2025 - UEA - Sistema de Ingresso Seriado - 2ª Série do Ensino Médio - Prova de Acompanhamento II |
Q3921847
Programação
Em um código de programação escrito em linguagem natural,
o comando  soma os valores das variáveis Receita e Entrada e guarda o
resultado na variável Receita. Considere o seguinte código
de programação, escrito em linguagem natural.
soma os valores das variáveis Receita e Entrada e guarda o
resultado na variável Receita. Considere o seguinte código
de programação, escrito em linguagem natural.

Após a execução desse código, o valor da variável Receita excede o valor da variável Despesa em
soma os valores das variáveis Receita e Entrada e guarda o
resultado na variável Receita. Considere o seguinte código
de programação, escrito em linguagem natural. Após a execução desse código, o valor da variável Receita excede o valor da variável Despesa em
Q3903024
Programação
O foco central do paradigma orientado a objetos é:
Q3903022
Programação
Sobre a verificação e inferência de tipos em linguagens
de programação, assinale a alternativa CORRETА.
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Desenvolvimento de Sistemas |
Q3845359
Programação
A Orientação a Objetos (OO) constitui um paradigma
aplicado na programação, que consiste na interação
entre diversas unidades chamadas de objetos. A
Programação Orientada a Objetos se apoia em quatro
pilares principais, sendo que em um deles realiza-se o
agrupamento das coisas que fazem sentido estarem
juntas, para fins de organização e reutilização melhor do
código. Em outro pilar, tem-se a possibilidade de um
objeto assumir diversas formas diferentes na orientação
a objetos.
Esses dois pilares da OO são conhecidos, respectivamente, como:
Esses dois pilares da OO são conhecidos, respectivamente, como:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Desenvolvimento de Sistemas |
Q3845354
Programação
Em relação à versão anterior, na linguagem de
programação Python 3.11, vários módulos foram
melhorados. Nesse contexto, a sintaxe de um dos
módulos retorna 2 elevado à potência de x e a de outro
retorna a raiz cúbica de x.
As sintaxes especificadas para esses módulos são, respectivamente:
As sintaxes especificadas para esses módulos são, respectivamente:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Desenvolvimento de Sistemas |
Q3845353
Programação
A programação estruturada estabelece uma disciplina no
desenvolvimento de algoritmos, independentemente da
sua complexidade e da linguagem na qual será
codificado, que facilita a compreensão da solução
através de um número restrito de mecanismos de
codificação. Nesse sentido, observe as estruturas de
controle em (a) e (b).
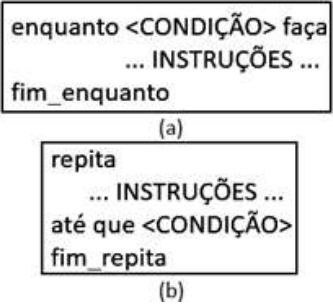
Na estrutura "enquanto.... fim_enquanto" em (a), o fluxo de execução das instruções permanece no loop de repetição, quando o teste da condição retorna um valor booleano BOL1, ao passo que a execução da estrutura termina, quando o teste da condição retorna outro valor booleano BOL2. Em contrapartida, na estrutura "repita ... fim_repita" em (b), o fluxo de execução das instruções permanece no loop de repetição, quando o teste da condição retorna um valor booleano BOL3, ao passo que a execução da estrutura se encerra quando o teste da condição retorna outro valor booleano BOL4.
FALSO, VERDADEIRO, FALSO e VERDADEIROOs valores booleanos ou lógicos BOL1, BOL2, BOL3 e BOL4 são, respectivamente:
Na estrutura "enquanto.... fim_enquanto" em (a), o fluxo de execução das instruções permanece no loop de repetição, quando o teste da condição retorna um valor booleano BOL1, ao passo que a execução da estrutura termina, quando o teste da condição retorna outro valor booleano BOL2. Em contrapartida, na estrutura "repita ... fim_repita" em (b), o fluxo de execução das instruções permanece no loop de repetição, quando o teste da condição retorna um valor booleano BOL3, ao passo que a execução da estrutura se encerra quando o teste da condição retorna outro valor booleano BOL4.
FALSO, VERDADEIRO, FALSO e VERDADEIROOs valores booleanos ou lógicos BOL1, BOL2, BOL3 e BOL4 são, respectivamente:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Desenvolvimento de Sistemas |
Q3845352
Programação
No algoritmo da figura, são utilizados os conceitos de
passagem de parâmetros por valor de NR01 para P1 e
por referência de NR02 para P2.

Após a execução do algoritmo, serão impressos para as variáveis NR01, NR02 e XYZ, respectivamente, os seguintes valores:
Após a execução do algoritmo, serão impressos para as variáveis NR01, NR02 e XYZ, respectivamente, os seguintes valores:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Desenvolvimento de Sistemas |
Q3845350
Programação
Observe as figuras (a) e (b) que mostram,
respectivamente, o resultado da execução e o código
correspondente, em JavaScript.

Ao clicar no botão

exibido em (a), o código em (b) será executado, resultando na geração da seguinte sequência de números:
Ao clicar no botão
exibido em (a), o código em (b) será executado, resultando na geração da seguinte sequência de números:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Especialista em Petróleo e Gás - Avaliação Econômica |
Q3844544
Programação
Um programa durante a compilação inicia com uma
linguagem de alto nível, passa por uma etapa
intermediária, e termina com um microcódigo. Na etapa
intermediária é gerado um código conhecido como:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Especialista em Petróleo e Gás - Avaliação Econômica |
Q3844534
Programação
Na lógica de programação estruturada, existem
estruturas de controle bem definidas que permitem
representar qualquer algoritmo de forma clara e
organizada. De acordo com esse paradigma, existem
três estruturas básicas que, combinadas, são suficientes
para expressar a solução de qualquer problema
computacional. Essas estruturas são:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Especialista em Petróleo e Gás - Avaliação Econômica |
Q3844521
Programação
Texto associado
O texto seguinte servirá de base para responder à
questão.
Um especialista de avaliação econômica criou a seguinte
macro VerificarNota com um código na linguagem VBA.
Sub VerificarNota()
Dim nota As Integer
nota = 30
If nota > = 50 Then
MsgBox "Aprovado com distinção!"
ElseIf nota > = 39 Then
MsgBox "Escapou"
ElseIf (nota = 30.0) Then
MsgBox "Surpresa"
Else MsgBox "Eita"
End If
End Sub
Fonte: Documentação Microsoft
Após rodar essa macro, o resultado apresentado é:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Especialista em Petróleo e Gás - Avaliação Econômica |
Q3844520
Programação
Texto associado
O texto seguinte servirá de base para responder à
questão.
Considere o seguinte trecho de código na linguagem Visual Basic (VBA).
Dim i As Integer
For i = 1 To 10 Step -3
Debug.Print i
Next i
Fonte: Documentação Microsoft
Esse trecho de código quando executado na janela imediata:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Segurança da Informação |
Q3842962
Programação
Java, como plataforma de programação, é composta de
uma máquina virtual java (JVM), um completo conjunto
de APIs (bibliotecas) e a linguagem Java orientada a
objetos, constituindo uma tecnologia independente de
sistema operacional e hardware. Em Java, o acesso
direto a uma variável de instância de um objeto pode não
estar habilitado. Quando se declara uma variável de
instância, pode-se, opcionalmente, definir um
modificador de variável, seguido pelo tipo e identificador
daquela variável. O escopo de uma variável de instância
pode ser controlado pelo uso dos modificadores de
variáveis, de acordo com a classificação listada a seguir.
I.MA1 - Quando qualquer um pode acessar variáveis de instância públicas.
II.MA2 - Quando métodos do mesmo pacote ou subclasse podem acessar variáveis de instância protegidas.
III.MA3 -Quando apenas métodos da mesma classe, excluindo métodos de uma subclasse, podem acessar variáveis de instâncias privadas.
Os modificadores de acesso MA1, MA2 e MA3 são denominados, respectivamente:
I.MA1 - Quando qualquer um pode acessar variáveis de instância públicas.
II.MA2 - Quando métodos do mesmo pacote ou subclasse podem acessar variáveis de instância protegidas.
III.MA3 -Quando apenas métodos da mesma classe, excluindo métodos de uma subclasse, podem acessar variáveis de instâncias privadas.
Os modificadores de acesso MA1, MA2 e MA3 são denominados, respectivamente:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Segurança da Informação |
Q3842948
Programação
React é uma biblioteca JavaScript para criar interfaces
de usuário, sendo que os aplicativos são feitos de
componentes. Um componente é uma parte da interface
do usuário, que tem sua própria lógica e aparência,
podendo ser tão pequeno quanto um botão ou tão
grande quanto uma página inteira. Entre os principais
componentes, um corresponde a uma técnica avançada
do React para reutilizar lógica em componentes, sendo
uma função que recebe um componente como
argumento e retorna um novo componente com
funcionalidades adicionais.
Essa descrição diz respeito ao componente React:
Essa descrição diz respeito ao componente React:
Ano: 2025
Banca:
IDCAP
Órgão:
PPSA
Prova:
IDCAP - 2025 - PPSA - Analista de Tecnologia da Informação - Projetos de TI |
Q3842904
Programação
Observe as afirmativas a seguir, em relação aos
sistemas de Manipulação e Tratamento de Dados
empregando o pacote dlyr, do Sistema R, que é uma
linguagem e um ambiente para gráficos e computação
estatística:
I.A função group_by() sumariza a base, reduzindo vários valores a um único resumo.
II.A função arrange() seleciona colunas, escolhendo variáveis com base em seus nomes.
III.A função filter() filtra linhas, escolhe casos com base em seus valores.
Estão corretas as afirmativas:
I.A função group_by() sumariza a base, reduzindo vários valores a um único resumo.
II.A função arrange() seleciona colunas, escolhendo variáveis com base em seus nomes.
III.A função filter() filtra linhas, escolhe casos com base em seus valores.
Estão corretas as afirmativas: