Questões de Concurso
Sobre modelos lineares em estatística
Foram encontradas 858 questões
Ano: 2025
Banca:
IMPARH
Órgão:
CGM de Fortaleza - CE
Prova:
IMPARH - 2025 - CGM de Fortaleza - CE - Auditor de Controle Interno - Área 5 (Estatística) |
Q3150506
Estatística
Como podemos fazer inferência sobre os parâmetros do
modelo de regressão linear?
Ano: 2025
Banca:
IMPARH
Órgão:
CGM de Fortaleza - CE
Prova:
IMPARH - 2025 - CGM de Fortaleza - CE - Auditor de Controle Interno - Área 5 (Estatística) |
Q3150502
Estatística
Em testes de hipóteses, rejeitar a hipótese nula significa:
Ano: 2025
Banca:
IMPARH
Órgão:
CGM de Fortaleza - CE
Prova:
IMPARH - 2025 - CGM de Fortaleza - CE - Auditor de Controle Interno - Área 5 (Estatística) |
Q3150501
Estatística
Sobre o critério de mínimos quadrados na análise de
regressão linear, podemos afirmar que o mesmo:
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550626
Estatística
Analise o gráfico de resíduos, abaixo, utilizado para o ajuste de um modelo de regressão
linear simples 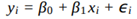 sendo
sendo 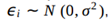 variáveis aleatórias independentes para todo para todo i = 1, ..., n.
variáveis aleatórias independentes para todo para todo i = 1, ..., n.
Gráfico de resíduos versus a ordem de coleta dos dados (ou a sequência de tempo) para o modelo ajustado
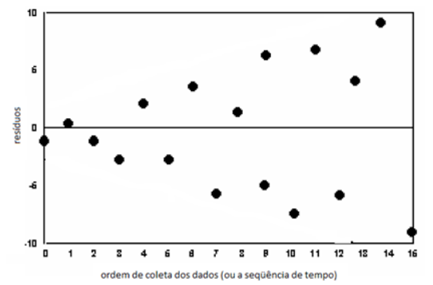
Esse gráfico indica que
sendo variáveis aleatórias independentes para todo para todo i = 1, ..., n. Gráfico de resíduos versus a ordem de coleta dos dados (ou a sequência de tempo) para o modelo ajustado
Esse gráfico indica que
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550625
Estatística
Texto associado
Para responder à questão, considere o excerto a seguir.
Para avaliar o desempenho dos alunos na disciplina de estatística, lecionada de forma virtual, foi conduzido um estudo. Para isso, selecionou-se uma amostra aleatória simples de 20estudantes. Para cada estudante selecionado nessa amostra, foram observadas a nota final na disciplina, yi, e o número de acessos desse estudante à página virtual da disciplina, xi. Considerando que as suposições para uma análise pelo modelo de regressão linear simples estão satisfeitas, ajustou-se o seguinte modelo: 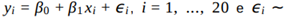 N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
A estatística 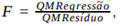 em que "QMRegressão" e "QMResíduo” são o quadrado médio da regressão e o quadrado médio dos resíduos, foi 42 e 49, respectivamente, para
o modelo ajustado. Esses valores são utilizados para testar as hipóteses
em que "QMRegressão" e "QMResíduo” são o quadrado médio da regressão e o quadrado médio dos resíduos, foi 42 e 49, respectivamente, para
o modelo ajustado. Esses valores são utilizados para testar as hipóteses
em que "QMRegressão" e "QMResíduo” são o quadrado médio da regressão e o quadrado médio dos resíduos, foi 42 e 49, respectivamente, para
o modelo ajustado. Esses valores são utilizados para testar as hipóteses
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550624
Estatística
Texto associado
Para responder à questão, considere o excerto a seguir.
Para avaliar o desempenho dos alunos na disciplina de estatística, lecionada de forma virtual, foi conduzido um estudo. Para isso, selecionou-se uma amostra aleatória simples de 20estudantes. Para cada estudante selecionado nessa amostra, foram observadas a nota final na disciplina, yi, e o número de acessos desse estudante à página virtual da disciplina, xi. Considerando que as suposições para uma análise pelo modelo de regressão linear simples estão satisfeitas, ajustou-se o seguinte modelo: N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
Os graus de liberdade da distribuição qui-quadrado da variável aleatória 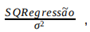 sendo S QRegressão a soma de quadrados da regressão, é igual a
sendo S QRegressão a soma de quadrados da regressão, é igual a
sendo S QRegressão a soma de quadrados da regressão, é igual a
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550623
Estatística
Texto associado
Para responder à questão, considere o excerto a seguir.
Para avaliar o desempenho dos alunos na disciplina de estatística, lecionada de forma virtual, foi conduzido um estudo. Para isso, selecionou-se uma amostra aleatória simples de 20estudantes. Para cada estudante selecionado nessa amostra, foram observadas a nota final na disciplina, yi, e o número de acessos desse estudante à página virtual da disciplina, xi. Considerando que as suposições para uma análise pelo modelo de regressão linear simples estão satisfeitas, ajustou-se o seguinte modelo: N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
N (0, σ2) são variáveis aleatórias independentes para todo i = 1, ..., 20.
O ajuste para o modelo produziu as estimativas β0 = 2, 43 e β1 = 0,2. Para a estimativa
do coeficiente associado à variável explicativa do modelo, a melhor interpretação é que
um acréscimo de uma unidade no número de acessos na página virtual da disciplina
proporciona, em média, um
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550622
Estatística
Texto associado
Para responder à questão, considere o enunciado a seguir.
Foi ajustado, a um conjunto de dados, o modelo de regressão linear 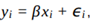 em que, para todo
em que, para todo 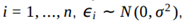 as variáveis são aleatórias independentes.
as variáveis são aleatórias independentes.
em que, para todo as variáveis são aleatórias independentes.
Considerando que ta;b e Za são os quantis das distribuições t-Student e normal padrão, respectivamente, o intervalo de 95% de confiança para β é
Ano: 2024
Banca:
COMPERVE - UFRN
Órgão:
UFERSA
Prova:
COMPERVE - UFRN - 2024 - UFERSA - Estatístico |
Q3550621
Estatística
Texto associado
Para responder à questão, considere o enunciado a seguir.
Foi ajustado, a um conjunto de dados, o modelo de regressão linear em que, para todo as variáveis são aleatórias independentes.
em que, para todo as variáveis são aleatórias independentes.
O estimador de mínimos quadrados de β é:
Ano: 2024
Banca:
INSTITUTO AOCP
Órgão:
UFS
Prova:
INSTITUTO AOCP - 2024 - UFS - Engenheiro Civil - Classe E |
Q3539389
Estatística
Na realização de uma perícia que tratava da
avaliação de um imóvel, o perito adotou uma
variável que assumia apenas duas posições: “0”
identificava imóveis em zona industrial e “1”
identificava imóveis em zona residencial. Como se
denomina essa variável?
Ano: 2024
Banca:
Instituto Access
Órgão:
CETEM
Prova:
Instituto Access - 2024 - CETEM - Tecnologista Pleno - Perfil 9 |
Q3486364
Estatística
Qual é o objetivo da análise de variância (ANOVA) em um
planejamento fatorial?
Q3443845
Estatística
A Empresa Delta S.A apurou os seguintes resultados sobre o aumento de custos em seus produtos:
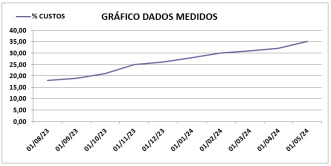
Sendo a Equação da Reta de Regressão dada por y = a + bx, onde a = 18,02 e b=0,06, pode-se calcular que para o dia 01/06/24 a estimativa de custos será de:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Análise, desenvolvimento e validação de metodologias para o controle físico-químico de produtos sujeitos à vigilância sanitária |
Q3341041
Estatística
O coeficiente de correlação (R2) entre a concentração
das soluções de MR de 2,3´-DHF e as absorbâncias encontradas foi de 0,99986. O valor do R2 é um dos parâmetros
utilizados para avaliar se a análise foi adequada. Sobre
esse valor pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Vigilância em Saúde |
Q3341013
Estatística
Para que o modelo de regressão linear seja confiável
e válido, os seguintes pressupostos devem ser satisfeitos,
EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Controle de Qualidade de insumos e medicamentos |
Q3339202
Estatística
A linearidade é a capacidade de um método de gerar
respostas analíticas diretamente proporcionais à concentração de um analito em uma amostra. De acordo com a
RDC nº 166/17, sobre a avaliação estatística da linearidade,
avalie as afirmativas abaixo:
I. O coeficiente de correlação (r²) deve estar acima de 0,990.
II. O coeficiente angular deve ser igual a zero.
III. Nos testes estatísticos, deve ser utilizado um nível de significância de 5%.
IV. É esperado que o coeficiente linear seja estatisticamente diferente de zero.
V. Para avaliar se os dados são homocedásticos ou não, é recomendado aplicar o teste F da Anova.
Sobre as afirmativas acima, pode-se dizer que:
I. O coeficiente de correlação (r²) deve estar acima de 0,990.
II. O coeficiente angular deve ser igual a zero.
III. Nos testes estatísticos, deve ser utilizado um nível de significância de 5%.
IV. É esperado que o coeficiente linear seja estatisticamente diferente de zero.
V. Para avaliar se os dados são homocedásticos ou não, é recomendado aplicar o teste F da Anova.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331509
Estatística
Considere a seguinte implementação de um modelo de
regressão linear múltipla utilizando NumPy e scikit-learn,
usado para prever o financiamento de projetos com base
em características de projetos e pesquisadores. O código
abaixo foi executado e algumas métricas de desempenho
foram obtidas.
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
import numpy as np from sklearn.model_selection import train_ test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
X = np.array([[1, 50], [2, 60], [3, 70], [4, 80], [5, 90], [1, 55], [2, 65], [3, 75], [4, 85], [5, 95]]) y = np.array([100000, 120000, 150000, 200000, 250000, 110000, 130000, 170000, 230000, 290000]) X_train, X_test, y_train, y_test = train_ test_split(X, y, test_size=0.2, random_ state=0)
model = LinearRegression() model.fit(X_train, y_train) y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred) mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred)
print(f”R-Quadrado: {r2}, MSE: {mse}, RMSE: {rmse}, MAE: {mae}”)
Após executar o código, foram obtidas as seguintes métricas de desempenho:
R-Quadrado: 0.9020746527777778 , MSE: 156680555.5555556, R M S E : 1 2 5 1 7 . 2 1 0 3 7 4 3 4 2 8 2 3 , M A E : 10083.333333333343
Com base nessas informações, analise as observações abaixo.
I. O valor de R-Quadrado próximo de 1 indica que o modelo explica uma grande proporção da variância dos dados de financiamento. Isso sugere que o modelo tem um bom ajuste aos dados, sendo capaz de capturar uma grande parte da relação entre as variáveis independentes e a variável dependente.
II. Um valor de MSE de aproximadamente 156 milhões sugere que, em média, o quadrado dos erros das previsões do modelo em relação aos valores reais é significativo. Isso indica que o modelo tem um bom ajuste de acordo e não existem erros consideráveis nas previsões.
III. Um MAE de aproximadamente 10083 sugere que, em média, as previsões do modelo desviam cerca de 10083 unidades dos valores reais. Comparado ao RMSE, o MAE não dá um peso tão grande a erros maiores, o que sugere que o modelo pode ter um número relativamente consistente de pequenos a moderados erros de previsão.
IV.A diferença entre o RMSE e o MAE sugere que o modelo pode estar lidando com alguns outliers ou previsões particularmente imprecisas que afetam mais o RMSE, pois o RMSE penaliza mais erros maiores do que erros menores.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331322
Estatística
Dentre as seguintes listas, NÃO contêm apenas algoritmos que podem ser usados para realizar uma regressão, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - ecnologia da informação e comunicação (TIC) com foco em análise e desenvolvimento de sistema |
Q3331037
Estatística
É INCORRETO afirmar que os modelos preditivos:
Ano: 2024
Banca:
IDCAP
Órgão:
Prefeitura de Serra - ES
Prova:
IDCAP - 2024 - Prefeitura de Serra - ES - Estatístico |
Q3329927
Estatística
Em um modelo de regressão polinomial de segundo grau, a relação entre a variável dependente Y e a variável independente X é modelada como:
Y=β0+β1 X+β2 X²+ε
Diante disto, assinale a alternativa que apresenta uma afirmação correta sobre esta regressão polinomial.
Y=β0+β1 X+β2 X²+ε
Diante disto, assinale a alternativa que apresenta uma afirmação correta sobre esta regressão polinomial.
Ano: 2024
Banca:
VUNESP
Órgão:
A.C. Camargo Cancer Center
Prova:
VUNESP - 2024 - A.C. Camargo Cancer Center - Programa de Residência Multiprofissional em Oncologia - Fonoaudiologia |
Q3303380
Estatística
O conceito de Prática Baseada em Evidência (PBE) refere-se ao uso consciente, responsável, explícito e cuidadoso da melhor evidência disponível para a tomada de
decisão relacionada com o cuidado de um indivíduo. Por
meio de indicadores de performance diagnóstica é possível investigar uma condição de saúde com instrumentos
de rastreamento ou avaliação que gerem resultados válidos e confiáveis para a tomada de decisão.
Um dos tipos de indicadores de performance diagnóstica utilizado na área da saúde é a verificação matemática de como duas ou mais variáveis se relacionam e representam um recurso útil para a tomada de decisão ao permitir a identificação dos fatores que trazem mais impacto a uma determinada questão de saúde. Esse modelo tem o intuito de realizar previsões sobre o comportamento de algum fenômeno ou determinar os efeitos sobre a variável resposta ou de interesse em decorrência de alterações introduzidas nas covariáveis.
Esse tipo de indicador refere-se
Um dos tipos de indicadores de performance diagnóstica utilizado na área da saúde é a verificação matemática de como duas ou mais variáveis se relacionam e representam um recurso útil para a tomada de decisão ao permitir a identificação dos fatores que trazem mais impacto a uma determinada questão de saúde. Esse modelo tem o intuito de realizar previsões sobre o comportamento de algum fenômeno ou determinar os efeitos sobre a variável resposta ou de interesse em decorrência de alterações introduzidas nas covariáveis.
Esse tipo de indicador refere-se