Questões de Concurso
Sobre estatística descritiva (análise exploratória de dados) em estatística
Foram encontradas 5.223 questões

Se (x — y) é igual a 5, então com relação às medidas de posição verifica-se que a
- Média: 350 consultas por mês
- Mediana: 300 consultas por mês
- Desvio padrão: 80 consultas
- Coeficiente de variação (CV): 22,86%
Com base nesses valores,
 Se a covariância de X e Y apresenta um valor igual a 24,
então o respectivo coeficiente de correlação é igual a
Se a covariância de X e Y apresenta um valor igual a 24,
então o respectivo coeficiente de correlação é igual a Assinale a alternativa correta:

Nesse estudo, foi aplicado um teste t para duas amostras dependentes (amostras pareadas) com as seguintes hipóteses:
H0: µ2020 = µ2024 versus H1: µ2020 < µ2024,
em que µ2020 e µ2024 representam as médias populacionais em 2020 e 2024, respectivamente. Considerando que a estatística do teste t foi igual a 2,36, e que o p-valor foi igual a 1,2%, julgue o próximo item.
O coeficiente de variação da produtividade em 2020 foi maior do que o de 2024, o que indica que a variabilidade relativa em relação à média foi maior em 2020.

Com base no gráfico precedente, julgue o item seguinte, considerando que, para essa sequência de dados, a média é 1,92 e a variância é 0,025.
Para a sequência de dados apresentada, a média é superior à mediana.
Com base no gráfico precedente, julgue o item seguinte, considerando que, para essa sequência de dados, a média é 1,92 e a variância é 0,025.
O desvio padrão dos dados do gráfico é inferior a 0,13.
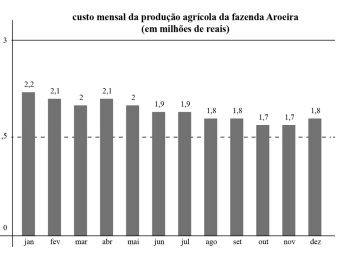
Com base no gráfico precedente, julgue o item seguinte, considerando que, para essa sequência de dados, a média é 1,92 e a variância é 0,025.
Para a sequência de dados apresentada, a média é superior a 110% do valor da moda.
Julgue o item a seguir, no que se refere à ciência de dados e à inteligência artificial.
A EDA (exploratory data analysis) utiliza ferramentas como gráficos de dispersão, correlações e histogramas para descobrir padrões, relações ocultas e tendências importantes nos dados, como sazonalidade e correlação entre variáveis.
Julgue o item a seguir, no que se refere à ciência de dados e à inteligência artificial.
Em um conjunto de dados sobre renda familiar, um valor extremamente alto pode representar uma pessoa com renda muito superior à média, e, portanto, deve sempre ser removido, independentemente de sua relevância para a análise.
Na tabela a seguir, são registradas as estatísticas descritivas relacionadas a uma amostra aleatória de 100 indivíduos em estudo sobre a altura média de plantas de determinada cultura em um terreno com um total de 10.000 plantas.

Com base nas informações apresentadas, julgue o próximo item.
A amplitude interquartil é inferior a 43.
Na tabela a seguir, são registradas as estatísticas descritivas relacionadas a uma amostra aleatória de 100 indivíduos em estudo sobre a altura média de plantas de determinada cultura em um terreno com um total de 10.000 plantas.

Com base nas informações apresentadas, julgue o próximo item.
As medidas de posição mostradas na tabela sugerem que a distribuição das alturas apresenta assimetria negativa.
Na tabela a seguir, são registradas as estatísticas descritivas relacionadas a uma amostra aleatória de 100 indivíduos em estudo sobre a altura média de plantas de determinada cultura em um terreno com um total de 10.000 plantas.
Com base nas informações apresentadas, julgue o próximo item.
O coeficiente de variação tem valor entre 10 cm e 50 cm.
Em relação ao data warehouse, ao data lake e ao tratamento de dados, julgue o item seguinte.
A imputação de valores ausentes com a média ou mediana é uma técnica comum para lidar com dados ausentes em análise de dados. Entretanto, ela pode distorcer a distribuição dos dados se a quantidade de dados ausentes for grande.

Com base nas informações apresentadas no gráfico, assinale a afirmativa correta.