Questões de Concurso
Para if-sp
Foram encontradas 3.453 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q3977010
Estatuto da Pessoa com Deficiência - Lei nº 13.146 de 2015
O artigo 28 da Lei Brasileira de Inclusão da
pessoa com deficiência elenca as incumbências do
dever público referentes ao direito à educação da
pessoa com deficiência. Qual item a seguir não é
uma dessas incumbências?
Q3977009
Pedagogia
“O respeito pela dignidade inerente, a autonomia individual, inclusive a liberdade de fazer as
próprias escolhas, e a independência das pessoas”
e “a plena e efetiva participação e inclusão na sociedade” são dois dos princípios gerais que constam no decreto nº 6.949 de 25 de agosto de 2009.
O referido decreto refere-se:
Q3977008
Pedagogia
O Documento Base do Programa Nacional
de Integração da Educação Profissional com a
Educação Básica na Modalidade de Educação de
Jovens e Adultos – PROEJA dedica um capítulo para a avaliação. Neste capítulo, o documento
apresenta as múltiplas dimensões da avaliação:
diagnóstica, processual, formativa e somativa.
Com base nas definições do documento, asso cie as duas colunas de acordo com as definições apresentadas aos conceitos de avaliação citados no texto e, depois, escolha a alternativa que apresenta a sequência correta.
1 – Diagnóstica 2 – Processual 3 – Formativa 4 – Somativa
( ) Caracteriza o desenvolvimento do aluno no pro cesso de ensino-aprendizagem, visualizando avanços e dificuldades e realizando ajustes e tomando decisões necessárias às estratégias de ensino e ao desempenho dos sujeitos do processo.
( ) O sujeito tem consciência da atividade que desenvolve, dos objetivos da aprendizagem, podendo participar na regulação da atividade de forma consciente, expressando seus erros, como hipóteses de aprendizagem.
( ) Reconhece que a aprendizagem acontece em diferentes tempos, por processos singulares, têm ritmos próprios e lógicas diversas, em função de experiências anteriores mediadas por necessidades múltiplas e por vivências individuais.
( ) Expressa o resultado referente ao desempenho do estudante no bimestre/se mestre através de menções, relatórios ou notas.
Com base nas definições do documento, asso cie as duas colunas de acordo com as definições apresentadas aos conceitos de avaliação citados no texto e, depois, escolha a alternativa que apresenta a sequência correta.
1 – Diagnóstica 2 – Processual 3 – Formativa 4 – Somativa
( ) Caracteriza o desenvolvimento do aluno no pro cesso de ensino-aprendizagem, visualizando avanços e dificuldades e realizando ajustes e tomando decisões necessárias às estratégias de ensino e ao desempenho dos sujeitos do processo.
( ) O sujeito tem consciência da atividade que desenvolve, dos objetivos da aprendizagem, podendo participar na regulação da atividade de forma consciente, expressando seus erros, como hipóteses de aprendizagem.
( ) Reconhece que a aprendizagem acontece em diferentes tempos, por processos singulares, têm ritmos próprios e lógicas diversas, em função de experiências anteriores mediadas por necessidades múltiplas e por vivências individuais.
( ) Expressa o resultado referente ao desempenho do estudante no bimestre/se mestre através de menções, relatórios ou notas.
Q3977007
Pedagogia
Pacheco (2015), em seu livro Fundamentos
político-pedagógicos dos institutos federais: dire
trizes para uma educação profissional e tecnológica
transformadora, afirma que os Institutos Federais
de Educação, Ciência e Tecnologia têm como
princípio, em sua proposta político-pedagógica,
ofertar diferentes níveis e modalidades da educação
profissional e tecnológica, tomando para si a res
ponsabilidade de possibilidades diversas de escola
rização como forma de efetivar o seu compromisso
com todos.
Diante do exposto, assinale com V (verdadeiro) ou com F (falso) as seguintes afirmações sobre os diferentes níveis e modalidades da educação profissional e tecnológica que podem ser ofertados pelos institutos federais.
[ ] educação básica, principalmente em cursos de ensino médio integrado à educação profissional técnica de nível médio.
[ ] ensino técnico em geral.
[ ] graduações tecnológicas, licenciatura e bacharelado em áreas em que a ciência e a tecnologia são componentes determinantes, em particular as engenharias.
[ ] programas de pós-graduação apenas stricto sensu.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é:
Diante do exposto, assinale com V (verdadeiro) ou com F (falso) as seguintes afirmações sobre os diferentes níveis e modalidades da educação profissional e tecnológica que podem ser ofertados pelos institutos federais.
[ ] educação básica, principalmente em cursos de ensino médio integrado à educação profissional técnica de nível médio.
[ ] ensino técnico em geral.
[ ] graduações tecnológicas, licenciatura e bacharelado em áreas em que a ciência e a tecnologia são componentes determinantes, em particular as engenharias.
[ ] programas de pós-graduação apenas stricto sensu.
A sequência correta de preenchimento dos parênteses, de cima para baixo, é:
Q3977006
Pedagogia
De acordo com o decreto nº 6.949, de 25
de agosto de 2009, pessoas com deficiência são
aquelas que têm impedimentos de _________ prazo de natureza física, _________, intelectual ou
_________, os quais, em interação com diversas
barreiras, podem obstruir sua participação plena e
efetiva na sociedade em igualdades de condições
com as demais pessoas.
As palavras que completam a definição acima são, respectivamente,
As palavras que completam a definição acima são, respectivamente,
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976965
Programação
Considere o seguinte código em linguagem
Python e selecione a alternativa que apresenta a
saída do programa.
w = [];
for i in range(0, x, 1) :
z = [];
for j in range(0, y, 1) :
z.append(i*y+j);
w.append(z);
print(w);
w = [];
for i in range(0, x, 1) :
z = [];
for j in range(0, y, 1) :
z.append(i*y+j);
w.append(z);
print(w);
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976964
Programação
A biblioteca NLTK (Natural Language Toolkit) engloba ferramentas para processamento de
linguagem natural, tais como funções de tokenização e radicalização. Dessa forma, considerando o
código apresentado:
frase = “Não esqueçam a lista de materiais: 1 lápis e 2 canetas!”
from nltk.tokenize import RegexpTokenizer
tokenizador = RegexpTokenizer(r’\w+’)
tokens = tokenizador.tokenize(frase)
print(tokens)
Qual o resultado correto?
frase = “Não esqueçam a lista de materiais: 1 lápis e 2 canetas!”
from nltk.tokenize import RegexpTokenizer
tokenizador = RegexpTokenizer(r’\w+’)
tokens = tokenizador.tokenize(frase)
print(tokens)
Qual o resultado correto?
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976963
Engenharia de Software
Uma rede neural é um modelo preditivo motivado pela forma como o cérebro funciona. Redes
neurais artificiais são formadas por neurônios artificiais, que desenvolvem cálculos similares sobre
suas entradas. Elas podem resolver uma variedade
de problemas, tais como o reconhecimento de caligrafia e a detecção facial, entre outros. São geralmente representadas por meio de um grafo orientado, onde os vértices representam os neurônios
e as arestas representam as sinapses. Podem ser
classificadas em três categorias específicas: Redes Neurais Feed-Forward, Redes Recorrentes e
Redes Conectadas Simetricamente. Dentro dessas
categorias, existem diversos tipos de arquiteturas.
Assinale a alternativa que define corretamente uma Rede Neural Perceptron Multicamadas.
Assinale a alternativa que define corretamente uma Rede Neural Perceptron Multicamadas.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976962
Programação
a = {1,2,3}
b = (1,2,3)
c = [1,2,3]
d = {“a”: 1,”b”: 2,”c”: 3}
print(type(a))
print(type(b))
print(type(c))
print(type(d))
Assinale a alternativa que corresponde à saída gerada pelo algoritmo acima:
b = (1,2,3)
c = [1,2,3]
d = {“a”: 1,”b”: 2,”c”: 3}
print(type(a))
print(type(b))
print(type(c))
print(type(d))
Assinale a alternativa que corresponde à saída gerada pelo algoritmo acima:
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976961
Engenharia de Software
O Processamento de Linguagem Natural
(PLN) é a subárea da Inteligência Artificial responsável por estudar a capacidade e as limitações
de uma máquina de entender a linguagem dos seres humanos. Para poder realizar essa modelagem,
são necessários pré-processamentos que abstraem
e estruturam a língua, deixando apenas aquilo que
representa uma informação relevante. Uma das
etapas desse processo compreende a normalização. Uma tarefa que pode ser realizada dentro do
processo de normalização é denominada de tokenização lexical. Considere a seguinte sentença:
A área de Ciência de Dados é muito interessante!
Assinale a alternativa correta que representa o resultado da tokenização lexical para essa sentença.
A área de Ciência de Dados é muito interessante!
Assinale a alternativa correta que representa o resultado da tokenização lexical para essa sentença.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976960
Banco de Dados
A linguagem SQL (Structured Query Language, ou Linguagem de Consulta Estruturada) é a linguagem padrão para se trabalhar com bancos de dados relacionais. Por meio de sua utilização, podemos gerar
diversos tipos de relatórios, como por exemplo, o relatório exibido pela Tabela 1.
Tabela 1 – Relatório dos dados da tabela COMPRAS
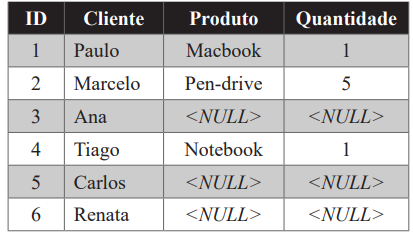
Tabela 2 – Resultado desejado pelo usuário
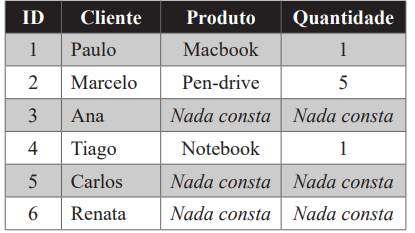
A Tabela 1 contém as informações de um relatório sobre as compras que foram realizadas por alguns clientes. Esses dados correspondem aos valores armazenados em uma tabela denominada COMPRAS. Analisando as informações exibidas, um usuário percebe que alguns clientes não compraram nenhum produto. Para esses casos, ele deseja que o trecho <NULL> seja substituído por “Nada consta”, conforme exibe a Tabela 2.
Assinale a alternativa correta que apresenta o código em linguagem SQL, que deve ser utilizado para realizar essa tarefa.
Tabela 1 – Relatório dos dados da tabela COMPRAS
Tabela 2 – Resultado desejado pelo usuário
A Tabela 1 contém as informações de um relatório sobre as compras que foram realizadas por alguns clientes. Esses dados correspondem aos valores armazenados em uma tabela denominada COMPRAS. Analisando as informações exibidas, um usuário percebe que alguns clientes não compraram nenhum produto. Para esses casos, ele deseja que o trecho <NULL> seja substituído por “Nada consta”, conforme exibe a Tabela 2.
Assinale a alternativa correta que apresenta o código em linguagem SQL, que deve ser utilizado para realizar essa tarefa.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976959
Estatística
from scipy import stats
…
Y, Z = stats.normaltest(X)
Considerando o trecho do algoritmo acima, assinale a alternativa que corresponde ao significado do valor de Z.
…
Y, Z = stats.normaltest(X)
Considerando o trecho do algoritmo acima, assinale a alternativa que corresponde ao significado do valor de Z.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976958
Banco de Dados
Quando se inicia os trabalhos de aprendizado em bases de dados é comum identificar problemas na base de dados. Por isso, na etapa de pré-
-processamento, os dados passam por recursos de
limpeza, integração de bases de dados, redução na
quantidade de atributos ou dados, transformação
nos formatos dos dados ou discretização de alguns.
Considerando esses recursos, indique a alternativa
incorreta que os define.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976957
Banco de Dados
ETL (Extract, Transform and Load) consiste num conjunto de técnicas com o objetivo de integração
a fim de combinar dados de diversas fontes. Por meio do ETL, é possível definir a qualidade dos dados e
a forma como eles são manipulados, a fim de transformá-los em uma informação inteligível e confiável.
Nesse contexto, associe a técnica de ETL com a caracterização mais adequada.
1 - SQL (Standard Query Language)
2 – Web Services
3 - Processamento em lote
4 – Mapeamento de dados
A - Fornece instruções detalhadas para uma aplicação sobre como obter os dados necessários para processar. Ele também descreve qual campo de origem é correspondente ao campo de destino. Por exemplo, associar um atributo de uma tabela do banco de dados com outro atributo de outra tabela de outro banco de dados.
B - É o método mais comum de acessar e transformar os dados de um banco de dados relacional.
C - Refere-se a uma operação que envolve a movimentação de grandes volumes de dados entre dois sistemas durante o que é chamado de “janela”. Nesse período determinado, nenhuma ação pode ocorrer com o sistema-fonte, enquanto os dados são sincronizados.
D – É um método baseado na internet para fornecer dados ou funcionalidades a várias aplicações em tempo quase real. Esse método simplifica os processos de integração de dados e pode entregar, rapidamente, mais valor a partir dos dados.
1 - SQL (Standard Query Language)
2 – Web Services
3 - Processamento em lote
4 – Mapeamento de dados
A - Fornece instruções detalhadas para uma aplicação sobre como obter os dados necessários para processar. Ele também descreve qual campo de origem é correspondente ao campo de destino. Por exemplo, associar um atributo de uma tabela do banco de dados com outro atributo de outra tabela de outro banco de dados.
B - É o método mais comum de acessar e transformar os dados de um banco de dados relacional.
C - Refere-se a uma operação que envolve a movimentação de grandes volumes de dados entre dois sistemas durante o que é chamado de “janela”. Nesse período determinado, nenhuma ação pode ocorrer com o sistema-fonte, enquanto os dados são sincronizados.
D – É um método baseado na internet para fornecer dados ou funcionalidades a várias aplicações em tempo quase real. Esse método simplifica os processos de integração de dados e pode entregar, rapidamente, mais valor a partir dos dados.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976956
Programação
Uma tarefa muito comum durante a etapa de pré-processamento de dados é o tratamento de valores
ausentes. Na linguagem R, os valores ausentes são representados por NA (Not Avaliable). Considere os
dados exibidos pela figura abaixo:
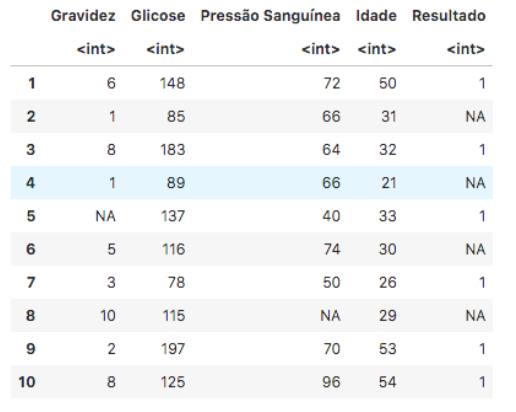
Fonte: IFSP, 2022.
Esses dados correspondem aos valores que foram carregados e armazenados em um dataframe da linguagem R. A linguagem R, assim como a linguagem Python, é muito utilizada na área de Ciência de Dados. Ela oferece diversas bibliotecas que podem ser empregadas para auxiliar nas etapas de pré-processamento e transformação dos dados. Ao analisar as informações exibidas pela figura, o cientista de dados percebe a existência de diversos valores ausentes e decide substituí-los da seguinte forma:
• Gravidez: substituir NA pelo valor 0;
• Pressão Sanguínea: substituir NA pela média dos valores da coluna;
• Resultado: substituir NA pelo valor 0.
Assinale a alternativa correta, que indica o trecho de código escrito em linguagem R, que pode ser utilizado para realizar essa tarefa.
Fonte: IFSP, 2022.
Esses dados correspondem aos valores que foram carregados e armazenados em um dataframe da linguagem R. A linguagem R, assim como a linguagem Python, é muito utilizada na área de Ciência de Dados. Ela oferece diversas bibliotecas que podem ser empregadas para auxiliar nas etapas de pré-processamento e transformação dos dados. Ao analisar as informações exibidas pela figura, o cientista de dados percebe a existência de diversos valores ausentes e decide substituí-los da seguinte forma:
• Gravidez: substituir NA pelo valor 0;
• Pressão Sanguínea: substituir NA pela média dos valores da coluna;
• Resultado: substituir NA pelo valor 0.
Assinale a alternativa correta, que indica o trecho de código escrito em linguagem R, que pode ser utilizado para realizar essa tarefa.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976955
Algoritmos e Estrutura de Dados
Entre os modelos de aprendizado de máquina mais comuns, estão as árvores de decisão. Elas
são métodos de aprendizado de máquinas muito
utilizados em tarefas de classificação e regressão.
Em problemas de classificação, os modelos em
árvore são designados de árvore de decisão. Para
resolver um problema de decisão, esse tipo de método utiliza a estratégia de dividir para conquistar.
Uma proposta natural é rotular cada conjunto da
divisão por sua classe mais frequente e escolher
a divisão que tem menores erros. O conceito fundamental nessa proposta é denominado de entropia. Considerando as árvores de decisão, assinale
a alternativa que define corretamente o conceito de
entropia.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976954
Programação
A variedade de recursos para a visualização
de dados é um dos diferenciais que atraem o interesse sobre a linguagem de programação Python.
Para isso, existem diferentes bibliotecas disponíveis na Internet, com destaque a biblioteca Matplotlib. Dentre os inúmeros recursos dessa biblioteca, o método plot disponibiliza recursos para a
visualização bidimensional de dados, como o do
gráfico a seguir.
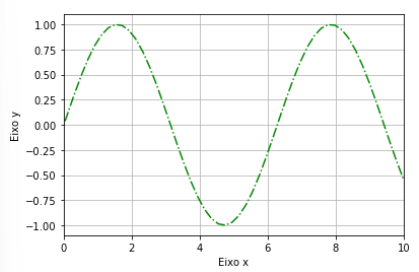
Fonte: IFSP, 2022.
Considerando esse gráfico gerado utilizando programação Python, selecione a opção que possibilita gerá-lo corretamente de acordo com a visualização apresentada nesta imagem. Para isso, considerar que a curva é uma senoide gerada pelo trecho de código a seguir:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
y = np.sin(x)
Fonte: IFSP, 2022.
Considerando esse gráfico gerado utilizando programação Python, selecione a opção que possibilita gerá-lo corretamente de acordo com a visualização apresentada nesta imagem. Para isso, considerar que a curva é uma senoide gerada pelo trecho de código a seguir:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-10, 10, 100)
y = np.sin(x)
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976953
Programação
A biblioteca Matplotlib é usada para plotagem de gráficos 2D em Python. A função subplot dessa
biblioteca é usada para criação de uma figura com subplotagens.
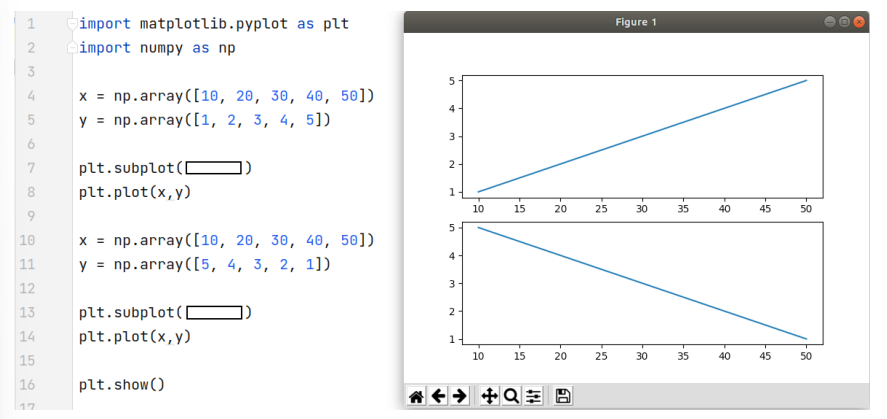
Considerando a imagem apresentada, assinale a alternativa que representa qual das sequências deveria ser usada na função subplot nas linhas 7 e 13, respectivamente, para geração dos gráficos apresentados ao lado do código.
Considerando a imagem apresentada, assinale a alternativa que representa qual das sequências deveria ser usada na função subplot nas linhas 7 e 13, respectivamente, para geração dos gráficos apresentados ao lado do código.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976952
Estatística
Uma amostra é um subconjunto da população em estudo. Ela representa a população maior e é usada
para fazer inferências sobre essa população. A amostragem probabilística é uma técnica de amostragem;
nela, as amostras são recolhidas em um processo que dá a todos os indivíduos da população as mesmas
chances de serem selecionados. Nesse contexto, associe a técnica de amostragem probabilística com o
exemplo apresentado e selecione a alternativa mais apropriada.
1 - Amostra aleatória simples
2 - Amostra sistemática
3 - Amostra Estratificada
4 - Amostra por aglomerados
A - Para obter uma amostra de estudantes universitários, o pesquisador precisaria dividir em classes de amostras. Primeiro organizaria a população por semestre de graduação e, então, selecionaria determinado número de representantes de calouros, pessoas que estão no meio do curso e formandos. Isso garantiria que o pesquisador tivesse quantidades adequadas de indivíduos de cada classe na amostra final.
B - Numa população de 1000 pessoas, você gostaria de escolher uma amostra aleatória de 50 pessoas. Primeiro, cada pessoa é numerada de 1 até 1000. Então, você gera uma lista de 50 números aleatórios e os números dessa lista serão os únicos que você incluirá na amostra.
C - Uma população de estudo contém 2000 estudantes do ensino fundamental e o pesquisador quer uma amostra de 100 estudantes. Os estudantes poderiam ser colocados em uma lista e cada 20º estudante seria selecionado para inclusão na amostra. A fim de evitar o viés humano nesse método, o pesquisador deve selecionar o primeiro elemento aleatoriamente.
D - Suponha que a população-alvo em um estudo seja membros de igrejas nos EUA. Não há uma lista de todos os membros de igrejas no país. O pesquisador poderia, nesse caso, criar uma lista de igrejas nos EUA, escolher uma amostra de igrejas e, então, obter listas de membros dessas igrejas.
1 - Amostra aleatória simples
2 - Amostra sistemática
3 - Amostra Estratificada
4 - Amostra por aglomerados
A - Para obter uma amostra de estudantes universitários, o pesquisador precisaria dividir em classes de amostras. Primeiro organizaria a população por semestre de graduação e, então, selecionaria determinado número de representantes de calouros, pessoas que estão no meio do curso e formandos. Isso garantiria que o pesquisador tivesse quantidades adequadas de indivíduos de cada classe na amostra final.
B - Numa população de 1000 pessoas, você gostaria de escolher uma amostra aleatória de 50 pessoas. Primeiro, cada pessoa é numerada de 1 até 1000. Então, você gera uma lista de 50 números aleatórios e os números dessa lista serão os únicos que você incluirá na amostra.
C - Uma população de estudo contém 2000 estudantes do ensino fundamental e o pesquisador quer uma amostra de 100 estudantes. Os estudantes poderiam ser colocados em uma lista e cada 20º estudante seria selecionado para inclusão na amostra. A fim de evitar o viés humano nesse método, o pesquisador deve selecionar o primeiro elemento aleatoriamente.
D - Suponha que a população-alvo em um estudo seja membros de igrejas nos EUA. Não há uma lista de todos os membros de igrejas no país. O pesquisador poderia, nesse caso, criar uma lista de igrejas nos EUA, escolher uma amostra de igrejas e, então, obter listas de membros dessas igrejas.
Ano: 2022
Banca:
IF-SP
Órgão:
IF-SP
Prova:
IF-SP - 2022 - IF-SP - Analista de Tecnologia da Informação - Ciência de Dados |
Q3976951
Banco de Dados
select payment_id, case when not exists (select 1 from customer where customer_id=1
limit 1) then 0 else payment_id end as payment from payment;
Com base no comando SQL, considere as
afirmativas:
I – Trata-se de uma consulta que utiliza duas tabelas;
II – Serão retornadas duas colunas, ambas nomeadas ‘payment_id’;
III – O comando retornará, no máximo, um registro;
IV – O comando contém erro de sintaxe.
Assinale a alternativa correta.
I – Trata-se de uma consulta que utiliza duas tabelas;
II – Serão retornadas duas colunas, ambas nomeadas ‘payment_id’;
III – O comando retornará, no máximo, um registro;
IV – O comando contém erro de sintaxe.
Assinale a alternativa correta.