Questões de Concurso
Para fiocruz
Foram encontradas 4.268 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331538
Noções de Informática
Sobre os impactos e riscos do uso de inteligência artificial (IA) e machine learning na saúde, é INCORRETO
afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331537
Noções de Informática
Modelos de IA que apresentam vieses podem levar a
um tratamento desigual e discriminatório contra indivíduos
e grupos específicos. Imagine um modelo usado para a
seleção de candidatos a vagas de emprego que privilegia
homens em detrimento de mulheres, mesmo que elas sejam
igualmente qualificadas. Esse tipo de viés de gênero pode
perpetuar desigualdades e prejudicar a carreira de muitas
mulheres. Dentre os possíveis elementos que podem mitigar esse efeito está:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331536
Sistemas de Informação
Modelos de IA nem sempre são transparentes sobre
quais fatores mais influenciam suas decisões. Para mitigar
esse efeito, uma abordagem é usar soluções do campo de
pesquisa chamado Inteligência Artificial Explicável, ou em
inglês: Explainable Artificial Intelligence (XAI). O objetivo
é ajudar a entender como um modelo complexo funciona,
fornecendo alguma explicabilidade e/ou interpretabilidade
sobre suas decisões. Sobre o uso de XAI, avalie se são
verdadeiras (V) ou falsas (F) as afirmativas a seguir:
I. Métodos de interpretabilidade robustos e consistentes são elementos fundamentais para a construção de confiança e para viabilizar a responsabilização (accountability) de decisões algorítmicas.
II. No campo da saúde, a busca por modelos de IA interpretáveis é fundamental não só para dar transparência para médicos e pacientes, mas para diversas outras partes interessadas, inclusive aos órgãos reguladores.
III. Na pesquisa científica, muitas aplicações utilizam modelos baseados em redes neurais profundas, que são por natureza pouco transparentes. Neste caso, a XAI pode desempenhar um papel importante ao dar acesso aos padrões identificados durante o processo de treinamento do modelo, podendo subsidiar a geração de hipóteses de pesquisa.
As afirmativas I, II e III são, respectivamente:
I. Métodos de interpretabilidade robustos e consistentes são elementos fundamentais para a construção de confiança e para viabilizar a responsabilização (accountability) de decisões algorítmicas.
II. No campo da saúde, a busca por modelos de IA interpretáveis é fundamental não só para dar transparência para médicos e pacientes, mas para diversas outras partes interessadas, inclusive aos órgãos reguladores.
III. Na pesquisa científica, muitas aplicações utilizam modelos baseados em redes neurais profundas, que são por natureza pouco transparentes. Neste caso, a XAI pode desempenhar um papel importante ao dar acesso aos padrões identificados durante o processo de treinamento do modelo, podendo subsidiar a geração de hipóteses de pesquisa.
As afirmativas I, II e III são, respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331535
Saúde Pública
Ao analisar dados do campo da saúde, é comum encontrar atributos com dados faltantes. Sobre as estratégias
para lidar com essa situação em pesquisas da saúde, avalie
se são verdadeiras (V) ou falsas (F) as afirmativas a seguir:
I. É importante compreender se os dados estão faltando de forma aleatória ou sistemática, o que pode influenciar a escolha da técnica apropriada para lidar com eles.
II. Uma abordagem comum é a imputação de dados, onde os valores faltantes são estimados com base em informações disponíveis.
III. A exclusão de observações com dados faltantes não é capaz de introduzir viés significativo.
As afirmativas I, II e III são, respectivamente:
I. É importante compreender se os dados estão faltando de forma aleatória ou sistemática, o que pode influenciar a escolha da técnica apropriada para lidar com eles.
II. Uma abordagem comum é a imputação de dados, onde os valores faltantes são estimados com base em informações disponíveis.
III. A exclusão de observações com dados faltantes não é capaz de introduzir viés significativo.
As afirmativas I, II e III são, respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331534
Programação
A análise visual de dados, por meio de gráficos e
dashboards, por exemplo, tem papel central na análise
exploratória de dados. Sobre o papel da análise visual na
descoberta de padrões em dados, é possível afirmar que
a análise visual:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331533
Sistemas de Informação
Na análise de dados textuais, é muito comum o uso de
medidas de similaridade para agrupamento de documentos.
Sobre a similaridade por cosseno, das afirmações utilizadas
abaixo está correta:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331532
Sistemas de Informação
Bases de dados desbalanceadas podem afetar os resultados de muitos algoritmos que tentam identificar padrões
nesses dados. Essa é uma realidade para muitas bases
da saúde, pois a prevalência de uma doença na população
pode ser algo raro. Sobre o processo de rebalanceamento
de bases de dados, avalie se são verdadeiras (V) ou falsas
(F) as afirmativas a seguir.
I. A técnica de oversampling envolve aumentar o número de instâncias da classe minoritária (menos frequente) para equilibrar a distribuição das classes.
II. A técnica de undersampling envolve reduzir o número de instâncias da classe majoritária (mais frequente) para equilibrar a distribuição das classes.
III. Antes de aplicar a técnica de oversampling, é importante dividir os dados em conjuntos de treino e teste. A técnica de oversampling só deve ser aplicada ao conjunto de testes.
As afirmativas I, II e III são respectivamente:
I. A técnica de oversampling envolve aumentar o número de instâncias da classe minoritária (menos frequente) para equilibrar a distribuição das classes.
II. A técnica de undersampling envolve reduzir o número de instâncias da classe majoritária (mais frequente) para equilibrar a distribuição das classes.
III. Antes de aplicar a técnica de oversampling, é importante dividir os dados em conjuntos de treino e teste. A técnica de oversampling só deve ser aplicada ao conjunto de testes.
As afirmativas I, II e III são respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331531
Programação
Atributos numéricos diferentes podem possuir enorme
discrepância de amplitude em um mesmo conjunto de dados. Por exemplo, enquanto a idade de uma pessoa tende
a estar entre 0 e 130 anos, a altura em metros costuma
variar entre 0,5 e 2,5. Em casos assim, alguns modelos
de análise podem dar uma importância muito maior para
a variável de maior amplitude (idade). Para lidar com esse
efeito, é comum o uso de métodos de feature scaling
disponíveis em pacotes Python como o Scikit Learn. Das
opções a seguir, a única que NÃO representa um método
para feature scaling é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331530
Programação
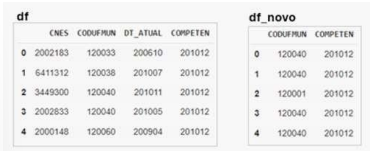
A biblioteca Pandas do Python possui diversas formas
para selecionar partes de um objeto dataframe. Utilizando
os dados disponíveis no dataframe df (imagem abaixo), um
programador deseja criar um dataframe (df_novo) contendo
somente as colunas CODUFMUN e COMPETEN. Das
opções abaixo, a única INCORRETA é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331529
Programação
No campo da saúde, é comum a adoção de métodos
para a reduzir a dimensionalidade dos dados, como a
segmentação de idades em faixas etárias. O comando
Python, com o uso da biblioteca Pandas (pd), que pode ser
utilizado para segmentar os valores de uma lista de idades
(tipo inteiro) em 10 faixas etárias, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331528
Programação
Para reproduzir a transformação ilustrada na figura
abaixo, o código Python que faz uso da bilblioteca Pandas
(pd) e pode ser utilizado para para unir dois dataframes
(df1 e df2), criando o dataframe (df3), é:

Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331527
Programação
Dataframes da biblioteca Pandas no Python são muito
versáteis. Com eles é possível ler, processar, transformar e
exportar dados tabulares com grande eficiência. Considere
um dataframe criado a partir da leitura de um arquivo do tipo
csv (comma separated value). Só devem ser carregadas
as primeiras mil linhas das colunas A, B e C. Além disso,
todos os valores devem ser convertidos para o tipo string.
Os parâmetros e valores do método read_csv() que possibilitam isso são:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331526
Saúde Pública
Um grupo de pesquisadores deseja acompanhar o
histórico de internações hospitalares de mães nascidas
após o ano 1997 e que tiveram filhos com baixo peso ao
nascer. A ideia central é identificar agravos de saúde que
podem contribuir para o baixo peso das crianças no momento do parto. Para isso, os pesquisadores pretendem
utilizar duas bases de dados disponíveis para download no
DATASUS em acesso aberto: o Sistema de Informações sobre Nascidos Vivos (SINASC) e o Sistema de Informações
Hospitalares (SIH/SUS). A pesquisa analisará os dados de
nascimentos e internações hospitalar entre 2012 e 2022.
Das opções abaixo, o real motivo que impede o desenvolvimento desse projeto é:
Das opções abaixo, o real motivo que impede o desenvolvimento desse projeto é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331525
Direito Sanitário
Sobre o direito à saúde previsto na Lei Orgânica da
Saúde (Lei nº 8080/1990) e na Constituição Federal (1988),
avalie se são verdadeiras (V) ou falsas (F) as afirmativas
a seguir:
I. A saúde é um direito fundamental do ser humano, devendo o Estado, sempre que possível, prover as condições indispensáveis ao seu pleno exercício.
II. O dever do Estado não exclui o das pessoas, da família, das empresas e da sociedade.
III. A saúde é direito de todos e dever do Estado, garantido mediante políticas sociais e econômicas que visem à redução do risco de doença.
As afirmativas I, II e III são, respectivamente:
I. A saúde é um direito fundamental do ser humano, devendo o Estado, sempre que possível, prover as condições indispensáveis ao seu pleno exercício.
II. O dever do Estado não exclui o das pessoas, da família, das empresas e da sociedade.
III. A saúde é direito de todos e dever do Estado, garantido mediante políticas sociais e econômicas que visem à redução do risco de doença.
As afirmativas I, II e III são, respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331524
Direito Sanitário
Segundo a Lei Orgânica da Saúde (Lei nº 8080/1990),
os serviços públicos de saúde e os serviços privados
contratados ou conveniados que integram o Sistema Único
de Saúde (SUS) devem obedecer aos princípios abaixo,
EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331523
Saúde Pública
Considerando a definição, pilares e objetivos da Saúde
Coletiva, avalie se são verdadeiras (V) ou falsas (F) as
afirmativas a seguir:
I. A saúde é definida como ausência de doenças.
II. Tem como característica ações isoladas da Vigilância Epidemiológica e Sanitária.
II. É considerada a influência de fatores sociais, econômicos e culturais na saúde das comunidades.
As afirmativas I, II e III são, respectivamente:
I. A saúde é definida como ausência de doenças.
II. Tem como característica ações isoladas da Vigilância Epidemiológica e Sanitária.
II. É considerada a influência de fatores sociais, econômicos e culturais na saúde das comunidades.
As afirmativas I, II e III são, respectivamente:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331522
Noções de Informática
Disseminados pelo DATASUS para download (ftp.datasus.gov.br), os dados desagregados sobre a declaração de
óbito do Sistema de Informação sobre Mortalidade (SIM)
estão disponíveis com a extensão:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331521
Saúde Pública
O Departamento de Informática do Sistema Único de
Saúde (DATASUS) disponibiliza inúmeros arquivos para
o enriquecimento das bases de dados disponíveis para
download. Alguns atributos são preenchidos com informações da classificação estatística internacional de doenças
e problemas relacionados com a Saúde (CID-10). São
disponibilizados pelo DATASUS arquivos que permitem a
agregação das doenças em:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331520
Sistemas de Informação
Você é um cientista de dados incumbido de desenvolver
uma aplicação de perguntas e respostas para facilitar a
extração de informações de documentos PDF contendo
artigos científicos na área da saúde. Para construir essa
aplicação, as seguintes estratégias foram apresentadas.
I. Utilizar a técnica de embeddings de texto para converter documentos PDF em vetores e armazená-los em um vectorstore, como ChromaDb ou Pinecone, permitindo buscas semânticas rápidas e eficientes baseadas no conteúdo dos artigos.
II. Desenvolver um sistema de indexação baseado em metadados extraídos dos documentos PDF, como autor, data de publicação e palavras-chave, para facilitar a filtragem e a busca por documentos específicos.
III. Implementar uma abordagem de processamento de linguagem natural (PLN) que empregue a API do modelo de linguagem para gerar respostas precisas às perguntas, utilizando os vetores e metadados armazenados para recuperar informações relevantes dos documentos e inseri-las no contexto do prompt.
IV. Realizar o fine-tuning do modelo de linguagem através de um dataset que contenha o conhecimento do domínio que se quer adicionar ao modelo, utilizando frameworks como LoRA ou QLoRA para fazer o merge desse dataset adicional treinado.
V. Criar uma hierarquia de documentos baseada na classificação dos artigos científicos por tópicos e subtópicos, utilizando algoritmos de clustering para organizar automaticamente os documentos em categorias relevantes.
Das estratégias acima:
I. Utilizar a técnica de embeddings de texto para converter documentos PDF em vetores e armazená-los em um vectorstore, como ChromaDb ou Pinecone, permitindo buscas semânticas rápidas e eficientes baseadas no conteúdo dos artigos.
II. Desenvolver um sistema de indexação baseado em metadados extraídos dos documentos PDF, como autor, data de publicação e palavras-chave, para facilitar a filtragem e a busca por documentos específicos.
III. Implementar uma abordagem de processamento de linguagem natural (PLN) que empregue a API do modelo de linguagem para gerar respostas precisas às perguntas, utilizando os vetores e metadados armazenados para recuperar informações relevantes dos documentos e inseri-las no contexto do prompt.
IV. Realizar o fine-tuning do modelo de linguagem através de um dataset que contenha o conhecimento do domínio que se quer adicionar ao modelo, utilizando frameworks como LoRA ou QLoRA para fazer o merge desse dataset adicional treinado.
V. Criar uma hierarquia de documentos baseada na classificação dos artigos científicos por tópicos e subtópicos, utilizando algoritmos de clustering para organizar automaticamente os documentos em categorias relevantes.
Das estratégias acima:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - TE56 - Cientista de Dados em Saúde |
Q3331519
Engenharia de Software
Acerca dos frameworks LangChain e Llamaindex, amplamente utilizados atualmente para construir aplicação
integradas a Large Language Models (LLMs), a opção que
apresenta uma observação correta é: