Questões de Concurso Sobre programação
Foram encontradas 14.684 questões
Análise o código e responda a questão.


Sabendo que o botão 1 (BT1) foi pressionado 12 vezes, o que acontecerá após o botão 2 (BT2) ser pressionado?
Assinale a alternativa que mostra a matriz M preenchida pelo seguinte código em Java:

Assinale a alternativa que descreve corretamente a função do método construtor.
Sobre o encapsulamento, existem diferentes níveis de acesso a atributos e métodos por outras classes, este recurso facilita tanto no uso da classe quanto na manutenção do código. Assinale a alternativa incorreta sobre encapsulamento.
O HTML (HyperText Markup Language) é uma linguagem de marcação e é usada na construção de páginas para a visualização de informação. O principal recurso dessa linguagem é a tag (marcação) no qual determina como a informação deve ser apresentada.
A entrada de dados em formulários pode ser feita de diferentes formas sendo usado diferentes tags para isso. Assinale a alternativa que descreve corretamente a tag para entrada de dados com sua funcionalidade.

Seja o seguinte código Python, que utiliza a biblioteca gensim e um modelo hipotético de word embeddings denominado modelo_saude.bin especializado em termos médicos em português:
import numpy as np from gensim.models import KeyedVectors
def calcular_similaridade(vetor_a, vetor_b): numerador = np.dot(vetor_a, vetor_b) denominador = np.linalg.norm(vetor_a) *
np.linalg.norm(vetor_b) similaridade = numerador / denominador return similaridade
mo del = Ke yed Vectors. load_ word 2vec _ format(‘modelo_saude.bin’, binary=True) vetor_diabetes = model[‘diabetes’] vetor_hipertensao = model[‘hipertensão’] vetor_insulina = model[‘insulina’]
vetor_diabetes_ajustado = vetor_diabetes + vetor_insulina vetor_hipertensao_ajustado = vetor_hipertensao + vetor_insulina
similaridade = calcular_similaridade(vetor_ diabetes_ajustado, vetor_hipertensao_ajustado) print(f”Similaridade: {similaridade}”)
Utilizando o modelo hipotético model_saude.bin, o resultado mostrado pelo código foi de 0.7036085724830627. Baseado no cenário descrito, no código fornecido e no resultado mostrado, a opção que melhor descreve o que está sendo calculado e o significado do resultado é:
import nltk nltk.download(‘punkt’) from nltk.tokenize import word_tokenize
texto = “Fundação Oswaldo Cruz (Fiocruz): Ciência e tecnologia em saúde para a população brasileira.” tokens = word_tokenize(texto)
contador = 0 resultado = 0 while contador < len(tokens): for letra in tokens[contador]: if letra.upper() in ‘FIOCRUZ’: resultado += 1 contador += 1
O valor da variável resultado, ao final da execução do código, é:
Entre as opções abaixo, a que apresenta corretamente a combinação de classes e funções do scikit-learn usadas para implementar regressão do tipo polinomial e classificação com árvores de decisão é:
Considere o sumário exibido abaixo, saída do comando summary(df) da linguagem R:

Com base nesta informação, a opção que contém uma observação INCORRETA é:
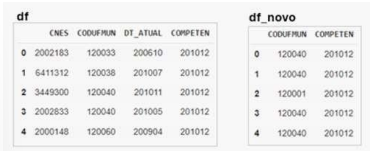
Seja o dataframe Pandas df carregado da tabela Financiamento e um extrato de seus dados mostrado abaixo.

E seja o seguinte código NumPy, que transforma df em matriz e manipula suas linhas e colunas.
import numpy as np matriz = df.values subconjunto = matriz[matriz[:, 1] == 1, 4:6]
Das opções abaixo, a que apresenta corretamente o array extraído pela operação NumPy é:
I. Empregar categorias para dados textuais repetitivos ao invés de strings.
II. Segmentar os dados em chunks menores durante a leitura de arquivos grandes, utilizando o parâmetro chunksize no read_csv.
III. Fazer uso intensivo de operações inplace.
Sobre as afirmativas acima, pode-se dizer que:
