Questões de Concurso Sobre banco de dados
Foram encontradas 18.739 questões
Após a importação de um lote digitado manualmente, a chefia identifica inconsistências pontuais que podem gerar efeitos administrativos indevidos, como divergência entre campos correlatos, duplicidade de registros vinculados ao mesmo identificador e erros de digitação em campos numéricos (por exemplo, datas e números de documentos).
O sistema possui validações automáticas básicas, mas não impede todas as inconformidades, e o setor exige que a correção preserve rastreabilidade e evite “ajustes por suposição”.
Considerando conferência, validação e correção de dados digitados, aponte a alternativa CORRETA.
Assinale a alternativa que corresponde ao nome do arquivo de configuração principal do banco de dados MySQL em sistemas operacionais Microsoft Windows.
I. CREATE TABLE
II. INSERT
III. UPDATE
IV. DROP TABLE
V. GRANT
Quais são comandos do subconjunto da linguagem de manipulação de dados (DML – Data Manipulation Language) da SQL?
No que se refere a Big Data, julgue o seguinte item.
Value, pilar fundamental do Big Data, está relacionado à qualidade, à confiabilidade e à precisão dos dados, assim como à garantia de que esses dados não se tornem ruído.
I. Uma chave primária (Primary Key) é um campo, ou conjunto de campos, que identifica de forma única cada registro em uma tabela, não permitindo valores nulos ou repetidos.
II. Uma chave estrangeira (Foreign Key) é utilizada para estabelecer um vínculo entre os dados de duas tabelas, referenciando a chave primária de outra tabela.
III. A normalização é um processo de design de banco de dados que visa aumentar a redundância de dados para garantir que as consultas sejam executadas mais rapidamente.
Está correto o que se afirma em:
I. Uma chave primária (Primary Key) é um campo, ou conjunto de campos, que identifica de forma única cada registro em uma tabela, não permitindo valores nulos ou repetidos.
II. Uma chave estrangeira (Foreign Key) é utilizada para estabelecer um vínculo entre os dados de duas tabelas, referenciando a chave primária de outra tabela.
III. A normalização é um processo de design de banco de dados que visa aumentar a redundância de dados para garantir que as consultas sejam executadas mais rapidamente.
Está correto o que se afirma em:
Julgue o próximo item, a respeito de visualização e análise exploratória de dados, de linguagens e ferramentas de apoio à análise de dados e de técnicas e tarefas de mineração de dados.
O boxplot (diagrama de caixa) é uma ferramenta de visualização que possibilita identificar a mediana, a dispersão dos dados e a presença de valores atípicos (outliers) em uma distribuição.
Acerca de modelagem dimensional, do CRISP-DM e do uso de banco de dados relacionais na análise de dados, julgue o item a seguir.
O esquema estrela é caracterizado por uma tabela de fatos central conectada a múltiplas tabelas de dimensão altamente normalizadas, e visa otimizar o uso de espaço de armazenamento.
Acerca de modelagem dimensional, do CRISP-DM e do uso de banco de dados relacionais na análise de dados, julgue o item a seguir.
No modelo de referência CRISP-DM, a fase de preparação de dados ocorre estritamente após a conclusão da fase de modelagem, com o objetivo de formatar as saídas preditivas geradas.
Acerca de modelagem dimensional, do CRISP-DM e do uso de banco de dados relacionais na análise de dados, julgue o item a seguir.
A junção externa (LEFT, RIGHT ou FULL OUTER JOIN) garante que todos os registros de pelo menos uma das tabelas sejam preservados no resultado de uma consulta, mesmo na ausência de correspondência na outra tabela.
No contexto de arquiteturas de dados modernas para auditoria e inteligência, a implementação de CDC integrada a um modelo ELT permite que os eventos de alteração de dados (DML) sejam ingeridos e persistidos no repositório central em seus formatos semiestruturados originais.
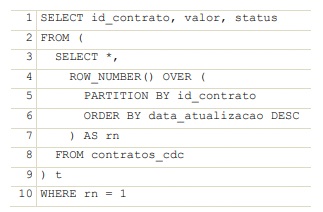
A partir das informações apresentadas e do trecho de código SQL precedente, julgue o item a seguir.
No que concerne à manipulação de dados em larga escala e à organização de consultas SQL, a utilização da CTE (common table expression) apresentada a seguir para encapsular a lógica de ranking é semanticamente equivalente à consulta SQL apresentada, pois ambas as abordagens produzem o mesmo resultado lógico ao isolar a versão mais recente de cada contrato, sob a premissa de que a coluna data_atualizacao permita uma ordenação unívoca para cada id_contrato.

A partir das informações apresentadas e do trecho de código SQL precedente, julgue o item a seguir.
No contexto de uma arquitetura de inteligência da informação para auditoria de dados, a consulta SQL apresentada utiliza a função de janela ROW_NUMBER() para segmentar os registros por contrato e ordená-los cronologicamente de forma decrescente; essa abordagem é eficaz para identificar a versão mais recente de cada contrato em uma tabela de CDC, sob a condição de que a coluna data_atualizacao tenha granularidade suficiente para garantir uma ordenação unívoca, evitando que registros distintos de um mesmo contrato apresentem o exato mesmo marcador temporal.
A respeito de dados estruturados e não estruturados, de banco de dados NoSQL, de modelagem e normalização de dados e de Big Data, julgue o item a seguir.
Sabendo-se que, no contexto da implementação de uma arquitetura de Big Data, o uso de um data lake distribuído para o armazenamento de dados brutos favorece a escalabilidade horizontal e a flexibilidade de esquemas, a adoção de formatos de arquivo colunares, como o Apache Parquet, é uma prática recomendada para otimizar a performance de leitura e reduzir o consumo de armazenamento por meio de técnicas de compressão e codificação eficientes.
A respeito de dados estruturados e não estruturados, de banco de dados NoSQL, de modelagem e normalização de dados e de Big Data, julgue o item a seguir.
No que se refere à tipologia de dados, documentos em HTML são classificados como dados estruturados, uma vez que a utilização de tags de marcação define rigidamente a organização e o esquema dos dados, de forma equivalente à estrutura de tabelas em bancos de dados relacionais.