Questões de Concurso
Sobre análise multivariada em estatística
Foram encontradas 221 questões
I. Na análise de componentes principais, quando a distribuição de probabilidade do vetor em estudo é normal multivariada, as componentes principais além de não correlacionadas são também independentes e têm distribuição normal.
II.
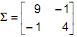 é a matriz de covariâncias do vetor aleatório X de dimensão (2X1), então a matriz de correlações de X é P =
é a matriz de covariâncias do vetor aleatório X de dimensão (2X1), então a matriz de correlações de X é P = 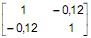
III. Na análise fatorial, quando a suposição de ortogonalidade dos fatores não puder ser considerada, pode-se utilizar o recurso da transformação ortogonal dos fatores originais na tentativa de se obter uma estrutura mais simples de ser interpretada.
IV. A análise de agrupamentos trabalha com medidas de similaridade e dissimilaridade, não comportando por isso o uso de variáveis qualitativas.
Está correto o que se afirma APENAS em
Dado um determinado modelo de regressão logística com função de ligação logit, em que:
_
_
_
Qual a probabilidade de Y=1, dado que X1=5 e X2=0 ?
Selecionou-se uma amostra aleatória simples, de tamanho 16, Y1 , Y2 , ..., Y16 , para se estudar uma característica tal que:

Sabe-se que ocorreram 10 sucessos.
A variância dessa amostra é
I. Na análise fatorial nenhuma variável é definida como dependente ou independente.
II. Na análise de agrupamentos deve haver bastante homogeneidade interna (dentro do agrupamento) em cada um dos agrupamentos resultantes.
III. Na análise de correlação canônica o princípio subjacente é desenvolver uma combinação linear de cada conjunto de variáveis dependentes e independentes para minimizar a correlação entre esses dois conjuntos.
IV. O escalamento multidimensional é uma técnica multivariada apropriada para representar n elementos em um espaço dimensional menor que o original, levando em consideração a similaridade que os elementos têm entre si.
Está correto o que consta APENAS em
I. O estimador de intensidade é útil para nos fornecer uma visão geral da distribuição em primeira ordem dos eventos.
II. O kernel é dependente do raio e pode ser utilizado na avaliação da distribuição de eventos pontuais.
III. Akrigagem é um método de interpolação aplicado apenas para análises de dados quantitativos.
Está(ão) correta(s) a(s) afirmativa(s):
I. análise do nível de fusão;
II. análise do nível de similaridade;
III. análise do coeficiente R2 ;
IV. estatística pseudo F.
Para auxiliar na decisão do número final de grupos que define a partição dos dados, pode-se utilizar os critérios apresentados nas alternativas
I. A análise de regressão múltipla é uma técnica estatística para analisar a relação entre uma única variável independente e várias variáveis dependentes.
II. Uma das medidas de similaridade usadas na Análise de Agrupamentos é a distância de Minkowsky, que tem como caso particular a distância Euclidiana.
III. Na análise discriminante a variável dependente é métrica e a independente é categórica.
IV. Na análise de correlação canônica a ideia básica é resumir a informação de um conjunto de variáveis-resposta em uma combinação linear, sendo que a escolha dos coeficientes dessa combinação é feita tendo como critério a minimização da correlação entre os conjuntos de variáveis respostas.
Está correto o que consta APENAS em
I. Seja X uma variável aleatória normal univariada com média µ1 e variância σ21 e Y uma variável aleatória normal univariada com média µ2 e variância σ22 . Nessas condições, o vetor
 tem distribuição normal bivariada.
tem distribuição normal bivariada.II. Se Σ é a matriz de covariâncias de um determinado vetor aleatório, então Σ é uma matriz positiva definida.
III. A variância total de um vetor aleatório é dada pelo traço de sua matriz de covariâncias.
IV. Se
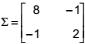 é a matriz de covariâncias do vetor aleatório X de dimensão (2X1), então a matriz de correlações de X é
é a matriz de covariâncias do vetor aleatório X de dimensão (2X1), então a matriz de correlações de X é 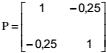
Está correto o que consta APENAS em
I. A análise de correspondência permite estudar associação entre variáveis qualitativas.
II. Na análise discriminante a variável dependente deve ser métrica.
III. Na análise de regressão múltipla uma forma de identificar colinearidade entre as variáveis independentes é examinar as correlações entre essas variáveis.
IV. Na análise de conglomerados, as técnicas hierárquicas exigem que o usuário identifique previamente o número de grupos desejado, mas essa exigência não prevalece nas técnicas não hierárquicas.
Está correto o que se afirma APENAS em
Em uma aplicação de Análise dos Componentes Principais é possível extrair:
Os dados a seguir referem-se às questões de 26 a 29.
Para analisar o consumo de combustível de um automóvel foram efetuadas 7 viagens, tendo-se registrado a distância percorrida (km) e o consumo (l), obtendo-se, então, os 7 pares de valores seguintes:
As variáveis de agrupamento usadas numa Análise de Conglomerados pelos métodos k-means (quick cluster) e hierárquico são:
A respeito das medidas de similaridade e dissimilaridade no âmbito da teoria de análise de agrupamentos (cluster), considere as seguintes afirmativas:
1. A distância de Minkowsky entre dois pontos Xl e Xk é muito mais afetada pela presença de valores discrepantes na amostra do que a distância euclidiana. Para λ = 1, a distância de Minkowsky é conhecida como city-block ou Manhattan.
2. O coeficiente de concordância positiva é definido como o número de pares realmente concordantes em relação ao número total de pares. Quanto maior o seu valor, maior é a concordância entre os elementos comparados, razão pela qual é um índice de similaridade.
3. A distância euclidiana média revela que, quanto menor o valor da distância, maior será a similaridade dos elementos comparados; portanto é um índice de discordância ou de dissimilaridade.
4. O coeficiente de Jaccard tem o mesmo objetivo que o coeficiente de concordância positiva. A diferença é que a proporção de pares concordantes é calculada em relação ao número total de pares, excluindo-se os pares do tipo (0 0).
Assinale a alternativa correta.
I. A análise fatorial é, geralmente, aplicada sobre variáveis métricas, apesar de existirem métodos especiais para o emprego dessa técnica a variáveis dicotômicas. II. Na análise discriminante, a variável dependente deve ser não métrica e as variáveis independentes devem indicar diferenças entre, pelo menos, dois grupos. III. A análise de correspondência não é adequada para pesquisa aleatória e não é sensível a observações atípicas. IV. Na análise de agrupamentos, as medidas de similaridade mais utilizadas são as correlacionais.
Está correto o que consta APENAS em
No que se refere aos métodos estatísticos de análise multivariada empregados na situação descrita acima, julgue o seguinte item.
Empregando-se a análise discriminante, é possível separar estatisticamente os usuários insatisfeitos daqueles que se consideram satisfeitos, com base nas características do usuário. Essa técnica é uma forma especializada de regressão em que se ajusta a probabilidade de um indivíduo pertencer a um grupo ou a outro grupo com base no seu perfil (como, por exemplo, idade, gênero, renda e escolaridade).
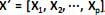 , através de poucas variáveis não observáveis F´ = [
, através de poucas variáveis não observáveis F´ = [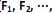
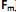 ] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz
] também conhecidas como fatores, construtos ou fatores comuns. Sendo E(X) = µ e V(X) = S, o modelo fatorial é expresso por X – µ = LF + e. A matriz 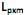 é conhecida como matriz das cargas fatoriais e seus elementos,
é conhecida como matriz das cargas fatoriais e seus elementos,  , carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas.
, carga da variável i no fator j e as variáveis aleatórias F e em + p são não observáveis. Analise as afirmativas, marque V para as verdadeiras e F para as falsas. ( ) No modelo fatorial ortogonal, as variáveis não observáveis F e e são independentes, E(F) = 0, V(F) = E(F´F) = I, E(e) = 0, V(e) = E(e´e) = ?. A matriz ? é não diagonal, V(X) = S = L´L + ? e Cov (X, F) = L.
( ) Um método de estimação para as cargas do modelo fatorial ortogonal é através de componentes principais, onde se utiliza a decomposição espectral da matriz S.
( ) Para se utilizar o método de máxima verossimilhança para estimar as cargas, é acrescida a suposição de que F e e têm distribuição normal multivariada. As comunalidades (elementos da diagonal LL´) têm como estimadores a proporção da variância total estimada pelo particular fator.
( ) Para melhorar a explicação do modelo fatorial, sem alterar a ortogonalidade dos fatores, muitas vezes, usa- se uma transformação ortogonal das cargas fatoriais, que, consequentemente, transforma os fatores. Esse procedimento é conhecido como rotação fatorial.
( ) Dependendo da natureza dos dados, os fatores não precisam ser ortogonais. Assim, para melhorar a explicação do modelo fatorial, pode-se utilizar a rotação oblíqua, onde cada variável é expressa em termos de um número máximo de fatores.
A sequência está correta em
Considere que, na análise discriminante por meio do escore quadrático, o vetor x seja classificado na população k se
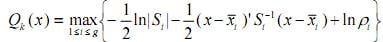 Nesse caso, se existirem apenas 2 populações (g = 2), e se S = S1 = S2, então a expressão de Qk(x) não dependerá de x, mas apenas de
Nesse caso, se existirem apenas 2 populações (g = 2), e se S = S1 = S2, então a expressão de Qk(x) não dependerá de x, mas apenas de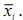
Na análise discriminante por meio do escore de Fisher, convencionou-se que os dados seguem distribuição normal.