Questões de Concurso
Sobre análise multivariada em estatística
Foram encontradas 226 questões
No âmbito da análise de produtos entregues por consultorias contratadas pela INFRA S.A. para a caracterização de solos ferroviários, o fiscal deve validar a redução de dimensionalidade de dados multivariados. Acerca de métodos estatísticos e suas análises nesse contexto, julgue o item a seguir.
Caso a consultoria apresente PCA em que os dois primeiros componentes explicam 85% da variância total, o fiscal poderá atestar a conformidade técnica com o critério de Kaiser, mesmo que o autovalor do segundo componente seja inferior a 1,0, uma vez que a variância acumulada é o parâmetro soberano nesse método.
Em relação às diferenças conceituais e aplicações da Análise de Componentes Principais (PCA) e da Análise Fatorial (AF), julgue os itens a seguir:
I. A PCA busca combinações lineares (componentes principais) que retêm a máxima variância total dos dados observados, sem postular um modelo de erros ou fatores latentes; já a Análise Fatorial assume que as variáveis observadas são funções lineares de fatores latentes comuns acrescidos de erros únicos (especificidades).
II. Na PCA, os componentes são ortogonais e ordenados por variância explicada; na Análise Fatorial, os fatores podem ser rotacionados (ex.: varimax) para facilitar a interpretação, e a comunalidade representa a proporção da variância de cada variável explicada pelos fatores comuns.
III. Uma diferença prática importante é que a PCA é frequentemente usada para redução de dimensionalidade quando o interesse é reter a maior parte da informação, enquanto a Análise Fatorial é mais adequada para identificar estruturas latentes subjacentes (ex.: traços de personalidade, construtos socioeconômicos).
IV. A PCA é invariante a rotações ortogonais dos componentes, ou seja, qualquer rotação dos eixos principais produz a mesma solução; já na Análise Fatorial, a rotação é essencial para tornar os fatores interpretáveis, e diferentes métodos de rotação podem levar a diferentes soluções fatoriais.
V. A PCA pressupõe que os dados seguem uma distribuição normal multivariada e que não há outliers, caso contrário os resultados são sempre inválidos; a Análise Fatorial, por outro lado, é robusta a qualquer tipo de distribuição e não requer normalidade.
Assinale a alternativa com a sequência CORRETA (V/F):
Um pesquisador dispõe de uma matriz de dados com 100 observações e 50 variáveis socioeconômicas. Ele aplica as seguintes técnicas: análise fatorial por máxima verossimilhança (AF), análise discriminante linear (LDA) e clusterização hierárquica. Em relação às propriedades e diferenças entre esses métodos, julgue os itens a seguir:
I. Na análise fatorial (método de máxima verossimilhança), assume-se que as variáveis observadas são combinações lineares de poucos fatores latentes comuns mais termos de erro únicos (especificidades), não correlacionados entre si. A solução dos loadings não é única, podendo ser rotacionada (ex.: varimax) sem alterar a comunalidade total.
II. A análise discriminante linear (LDA) para classificação assume que as covariâncias dentro dos grupos são homogêneas e que os dados seguem distribuição normal multivariada. Quando essas suposições são violadas, a LDA ainda é robusta e geralmente supera a regressão logística em termos de acurácia.
III. A clusterização hierárquica aglomerativa com ligação simples (single linkage) define a distância entre dois clusters como a distância mínima entre qualquer ponto de um cluster e qualquer ponto do outro. Esse método tende a produzir clusters alongados e é sensível a outliers, podendo gerar o efeito de "cadeia".
IV. Diferentemente da LDA, a análise fatorial não utiliza informação sobre grupos predefinidos; ela é uma técnica não supervisionada. No entanto, os escores fatoriais obtidos podem ser usados posteriormente como variáveis de entrada em uma LDA para classificação.
V. A clusterização hierárquica com ligação completa (complete linkage) é monotônica (não produz inversões no dendrograma) e tende a formar clusters compactos. Se os dados contiverem outliers, a ligação completa é mais afetada do que a ligação simples porque um outlier isolado forma um cluster de tamanho 1 a uma distância muito grande dos demais. Assinale a alternativa com a sequência CORRETA (V/F):
Uma universidade pública deseja criar um modelo para classificar candidatos ao curso de Estatística em três categorias: "baixo risco de evasão", "médio risco" e "alto risco", com base em variáveis preditoras contínuas (nota no ENEM, coeficiente de rendimento no ensino médio, horas de estudo semanais, renda familiar per capita). O estatístico da instituição opta pela Análise Discriminante Linear (ADL) como técnica de classificação supervisionada.
Assinale a alternativa que apresenta corretamente uma premissa fundamental da ADL e um procedimento de validação apropriado.

Com base nesses dados, tem-se que
I. K-Means, DBSCAN e Gaussian Mixture Models (GMM) são métodos amplamente empregados para tarefas de clusterização, embora se baseiem em pressupostos estatísticos e geométricos distintos.
II. DBSCAN e Mean-Shift são algoritmos que não exigem a definição prévia do número de clusters, pois os identificam implicitamente, a partir da densidade dos dados ou da estimação de modos da distribuição.
III. Critérios de informação como Akaike Information Criterion (AIC) e Bayesian Information Criterion (BIC), bem como heurísticas como o método do Elbow, são utilizados como técnicas auxiliares para apoiar a escolha do número adequado de clusters em determinados algoritmos.
É (são) verdadeira(s) a(s) alternativa(s):
A técnica mais adequada para essa tarefa é:
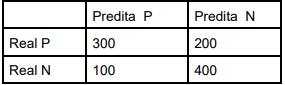
Os valores de precisão e recall para a classe P, nessa ordem, são
No que se refere aos processos de ETL (extract, transform, load) e a técnicas de pré-processamento de dados para classificação e visualização de dados, julgue o próximo item.
A análise PCA (análise de componentes principais) é utilizada para simplificar os dados e reduzir o ruído, pois tende a equilibrar as dimensões que têm valores mais extremos (outliers).
A partir da situação anterior, assinale a opção em que é corretamente descrita a técnica mais adequada para a finalidade pretendida pelos analistas de dados em questão.