Questões de Concurso
Sobre análise multivariada em estatística
Foram encontradas 221 questões
Como a pesquisa ainda não tem uma variável-alvo definida, o objetivo inicial é identificar grupos latentes de usuários com padrões semelhantes de comportamento, considerando variáveis como frequência de participação, região e faixa etária. Após essa etapa, a equipe pretende avaliar os fatores que contribuem para o engajamento cultural em regiões com baixa participação e, por fim, recomendar estratégias de ampliação de acesso.
Considerando os modelos multivariados, a natureza da base de dados e os objetivos e etapas propostos para a pesquisa, a equipe responsável deveria:
• Categóricas: faixa etária (≤ 30, 31–50, > 50 anos), gênero (masculino/feminino), diagnóstico de hipertensão (sim/não);
• Numéricas: horas semanais de atividade física, média de pressão arterial.
Considerando a técnica estatística mais adequada para cada objetivo específico da análise, é correto afirmar que se deve usar
I.Os métodos de agrupamento hierárquico, como o de Ward ou o da ligação completa (complete linkage), não exigem a pré-especificação do número de clusters e o resultado é tipicamente visualizado em um dendrograma, que mostra a sequência de fusões ou divisões dos grupos.
II.O método não hierárquico K-médias (K-means) é ideal para dados que contêm variáveis categóricas e outliers, pois o algoritmo é robusto a esses fatores e utiliza a distância de Manhattan como padrão.
III.No método de agrupamento hierárquico de ligação simples (single linkage), a distância entre dois clusters é definida pela distância entre os dois pontos mais distantes de cada cluster, o que tende a formar grupos esféricos e compactos.
Está correto o que se afirma em:
(__)Tanto a Análise Fatorial quanto a Análise de Componentes Principais são modelos matemáticos idênticos que buscam explicar a variância total das variáveis observadas, sendo os termos "fator" e "componente principal" sinônimos.
(__)Na Análise de Componentes Principais (ACP), os componentes são combinações lineares das variáveis originais e são assumidos como as causas latentes que geram as correlações entre essas variáveis.
(__)A Análise Fatorial é uma técnica mais indicada quando o objetivo é apenas a redução de dados para uso em análises subsequentes, sem a necessidade de uma interpretação teórica das dimensões subjacentes.
(__)Na Análise de Componentes Principais (ACP), os componentes principais são calculados de forma a serem ortogonais (não correlacionados) entre si, e o primeiro componente principal é a combinação linear das variáveis originais que captura a maior quantidade possível da variância total dos dados.
Após análise, assinale a alternativa que apresenta a sequência correta dos itens acima, de cima para baixo:
( ) A detecção de valor discrepante corresponde à identificação de uma observação, evento ou ponto de dados que representa um espaço vetorial multidimensional convexo e fixo, tornando-o inconsistente em relação ao resto do conjunto de dados.
( ) O aprendizado de máquina e a inteligência artificial são empregados para identificar automaticamente alterações inesperadas no comportamento normal de um conjunto de dados.
( ) As anomalias costumam ser raras e as características do comportamento normal podem ser complexas e dinâmicas, o que torna a detecção desafiadora.
As afirmativas são, respectivamente,
O algoritmo k-means é um método de clusterização do tipo particional que requer a definição prévia do número de clusters e utiliza a média dos elementos como critério para a atualização dos centroides.
O texto a seguir é referência para a questão.
Em uma aplicação de análise fatorial, baseada na matriz de covariâncias, p = 4 variáveis (y1, y2, y3 e y4) foram reduzidas a m = 2 fatores comuns (F1 e F2). Adicionalmente, considere a solução com m = 2 fatores, e as seguintes matrizes de cargas fatoriais (L) e matriz diagonal de variâncias específicas ψ:
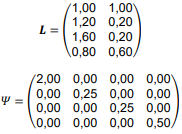
em que Lij representa a carga da variável i no fator j, e ψij é a variância específica de yi, i, j = 1, 2, 3, 4.
O texto a seguir é referência para a questão.
Em uma aplicação de análise fatorial, baseada na matriz de covariâncias, p = 4 variáveis (y1, y2, y3 e y4) foram reduzidas a m = 2 fatores comuns (F1 e F2). Adicionalmente, considere a solução com m = 2 fatores, e as seguintes matrizes de cargas fatoriais (L) e matriz diagonal de variâncias específicas ψ:
em que Lij representa a carga da variável i no fator j, e ψij é a variância específica de yi, i, j = 1, 2, 3, 4.
Com base nessa situação e nos princípios dos métodos de multicritério, é CORRETO afirmar que:
Para organizar melhor essas informações, ele precisa agrupar os beneficiários conforme seus perfis, permitindo uma análise mais precisa e a implementação de políticas específicas para cada grupo.
Assinale a opção que contém o algoritmo mais apropriado para realizar a tarefa acima.
Acerca de técnicas utilizadas na ciência de dados, julgue o item a seguir.
O K-means exige a definição do número de clusters como parâmetro de entrada e tem um desempenho eficiente em grandes conjuntos de dados, mas é sensível a outliers e só funciona bem para clusters esféricos e de densidade semelhante.
Acerca de técnicas utilizadas na ciência de dados, julgue o item a seguir.
A PCA (análise de componentes principais) é uma técnica que transforma variáveis correlacionadas em componentes principais ortogonais, o que permite a redução da dimensionalidade dos dados; a seleção dos componentes principais é realizada com base na variância explicada por cada componente.
Com relação a imagens térmicas, tratamento e análise de sinais, processamento de imagens e espectroscopia de emissão por plasma induzido por laser (LIBS), julgue o próximo item.
Métodos como a análise de componentes principais (PCA) ou a análise de componentes independentes (ICA) são usados para reduzir a dimensionalidade de grandes conjuntos de dados espectrais, facilitar a visualização e identificar padrões ocultos para a caracterização de substâncias.
Modelos multivariados são essenciais para a análise de dados fotométricos em grandes amostras, o que permite a separação de variáveis correlacionadas.
Julgue o item a seguir, em relação a técnicas de agrupamento, a técnicas de redução de dimensionalidade, e a processamento de linguagem natural.
A análise de componentes principais (PCA) é uma técnica usada para enfatizar a variação e trazer os padrões fortes em um conjunto de dados, e pode ser utilizada para facilitar a exploração e visualização dos dados, pois permite a redução do número de dimensões de um sistema.