Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 568 questões
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
Em um modelo para um aprendizado supervisionado dos
dados no formato de uma árvore de decisão, um algoritmo de
construção da árvore busca minimizar a informação
necessária para classificar os dados nas partições da árvore.
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
No aprendizado não supervisionado dos dados, usa-se uma
amostra para treinamento, e os registros são colocados em
agrupamentos semelhantes entre si quanto aos seus padrões.
Com referência aos conceitos e técnicas de mineração de dados, julgue o item seguinte.
Para encontrar regras de associação negativas de interesse,
como a identificação de padrões nos dados de um arquivo, a
hierarquia é uma técnica usada com base no conhecimento
prévio sobre um conjunto de atributos do arquivo.
A respeito de inteligência do negócio, julgue o item a seguir.
Os conceitos de data warehouse (DW) e data mining (DM)
são relacionados à inteligência de negócios; a principal
diferença entre eles é que o DW atua na análise dos eventos
do passado, enquanto o DM limita-se na predição dos
eventos futuros.
Com respeito a análise de componentes principais, mistura de gaussianas e agrupamento k-means, julgue o item que se segue.
Considere que, em uma análise de agrupamentos por meio de
mistura de gaussianas, três distribuições normais com médias 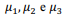 se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média
se referem, respectivamente, aos clusters 1, 2 e 3.
Nessa situação, pelo modelo de mistura de gaussianas, o
cluster 1 é constituído pelas observações mais próximas da
média 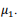
O ensemble denominado bagging tem como foco principal a redução do viés e não da variância, treinando-se os modelos em sequência, tal que os erros dos primeiros modelos treinados são utilizados para o ajuste nos pesos matemáticos dos próximos modelos.
Uma árvore de decisão representa um determinado número de caminhos possíveis de decisão e os resultados de cada um deles, apresentando muitos pontos positivos, ou seja, são fáceis de entender e interpretar. Elas têm processo de previsão completamente transparente e lidam facilmente com diversos atributos numéricos, assim como atributos categóricos, podendo até mesmo classificar dados sem atributos definidos.
De acordo com os aspectos construtivos de uma árvore de decisão, julgue o item a seguir.
Se o processo adotado para a construção de árvores de
decisão for determinístico, uma forma de obtenção de
árvores aleatórias, que compõem as florestas aleatórias, pode
ser realizada por meio do bootstrap dos dados, em que cada
árvore é treinada com base no resultado de bootstrap_sample
(inputs).
A partição que apresenta o menor erro de classificação quando feita na raiz (primeiro nível) de uma árvore de decisão é:
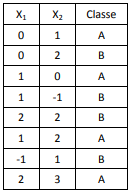
Esse analista gostaria de prever a classe dos pontos (1,1), (0,0) e (-1,2) usando o algoritmo de k-vizinhos mais próximos com k=3 e usando a distância euclidiana usual.
Suas classes previstas são, respectivamente:
Com relação a data warehouse e data mining, julgue o item subsequente.
A análise de data mining por padrão sequencial visa à
identificação de fatos que geram outros fatos, sempre
ocorrendo causa e consequência em momentos adjacentes.
Com relação a data warehouse e data mining, julgue o item subsequente.
A etapa de estratificação da técnica de árvore de decisão é
responsável por determinar as regras para a designação dos
casos identificados a uma categoria existente mais adequada
no data mining.
Utilize a figura a seguir (Fig3), que representa uma sequência de comandos em SQL, para resolver as questões de número 54 e 55.
Fig3
create table cliente
{
seq VARCHAR2(6) not null,
nome VARCHAR2(50) not null,
cpf VARÇHAR2(11) not null,
data nasc date,
dependentes numeric(2),
estcivil VARCHAR2(1)
);
arter table cliente
ADD CONSTRAINT cliente pk PRIMARY KEY (cpf)
ADD CONSTRAINT seq un unique (seq) enable
ADD CONSTRAIKT est ck check (estcivil in ('C','S','D','V')) enable
ADD CONSTRAINT cpf ch check (REGEXP LIKE(cpf, '^[[digit: ]]{11}$')) enable;
Como se chama o processo de explorar grandes quantidades de dados à procura de anomalias, padrões e correlações consistentes, tais como regras de associação ou sequências temporais, para detectar relacionamentos sistemáticos entre variáveis, detectando assim novos subconjuntos de dados?