Questões de Concurso
Sobre data mining em banco de dados
Foram encontradas 568 questões
Uma regra de associação utilizada em mineração de dados é uma expressão de implicação no formato X → Y, onde X e Y são conjuntos disjuntos de itens, onde X ∩ Y = Ø. A força de uma regra de associação pode ser medida em termos do seu suporte (sup) e confiança (conf).
Assinale a opção que apresenta a definição formal da métrica confiança.
Leia o fragmento a seguir.
“Atualmente, no contexto do Big Data e Data Analytics, faz-se referência às características enunciadas por pesquisadores e produtores de soluções como sendo um conjunto de cinco Vs. Originalmente, a definição clássica de Big Data fez referência a três Vs fundamentais: _____, _____ e _____ de dados que demandam formas inovadoras e rentáveis de processamento da informação, para melhor percepção e tomada de decisão.”
Assinale a opção cujos itens completam corretamente as lacunas do fragmento acima, na ordem apresentada.
A mineração de dados (Data Mining) envolve um conjunto de algoritmos e ferramentas que são utilizados para a exploração de dados.
Assinale o algoritmo/método usado na extração de regras de associação.
Leia o fragmento a seguir.
“CRISP-DM é um modelo de referência não proprietário, neutro, documentado e disponível na Internet, sendo amplamente utilizado para descrever o ciclo de vida de projetos de Ciência de Dados. O modelo é composto por seis fases: 1. entendimento do negócio; 2. _____; 3. _____; 4. Modelagem; 5. _____ ; e 6. implantação”.
Assinale a opção cujos itens completam corretamente as lacunas do fragmento acima, na ordem apresentada.
No início de um processo de descoberta de conhecimento em bases de dados (KDD), o CRISP-DM recomenda, em relação ao levantamento do hardware existente, que o processo de KDD seja realizado em plataforma com arquitetura não expansível, que forneça suporte e acesso somente à base de dados homogênea.
O uso da mineração de dados permite, por exemplo, que as empresas mais bem planejem a logística de distribuição dos seus produtos, prevendo picos nas vendas.
O modelo de referência CRISP-DM, composto por quatro fases não cíclicas, permite o fluxo unidirecional, ou seja, pode ir e voltar entre as fases.
Atualmente, conforme a tecnologia evolui, novos termos vão surgindo, particularmente com o aumento da importância dos dados na criação de estratégias de crescimento e tomadas de decisão. Nesse contexto, dois termos se destacam, descritos a seguir:
I. É um repositório central de informações que podem ser analisadas para tomar decisões mais adequadas. Os dados fluem de sistemas transacionais, bancos de dados relacionais e de outras fontes. Analistas de negócios, engenheiros de dados, cientistas de dados e tomadores de decisões acessam os dados por meio de ferramentas de inteligência de negócios (BI), clientes SQL e outros aplicativos de análise.
II. É um processo analítico no qual grande quantidade de dados são explorados com o objetivo de encontrar padrões relevantes ou relação sistemática entre variáveis, os quais são validados. Todo esse processo acontece em três etapas: exploração, construção de modelo (padrão) e validação. As ferramentas empregadas analisam dados em busca de oportunidades ou problemas e fazem o diagnóstico do comportamento dos negócios. Sendo assim, cabe ao usuário utilizar o conhecimento para produzir vantagens competitivas.
Os termos descritos em I e II representam os conceitos, respectivamente, de:
I. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção aleatória ocorre selecionando de forma aleatória N registros dentro do conjunto contendo M registros.
II. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento por seleção de grupo ocorre selecionando por meio de uma técnica de agrupamento os N registros mais representativos dentro do conjunto contendo M registros.
III. Dado dois conjuntos de registros com N e M registros (onde N<<M) vinculados a duas classes, o balanceamento ocorre gerando artificialmente instâncias a partir das instâncias do conjunto contendo M registros (classe maioritária).
Quais estão INCORRETAS?
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
No modelo CRISP-DM, a modelagem é uma das fases
mais importantes do processo, consistindo no
conhecimento do domínio do negócio, ou seja, no
conhecimento e na compreensão dos objetivos do
projeto de mineração a partir da perspectiva do negócio.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
O modelo CRISP-DM é bastante utilizado graças à sua
rigidez quanto à execução de cada uma de suas fases; ele
não permite que um projeto retorne a uma etapa ou fase
anterior, pois a sequência de fases é rigorosa e deve ser
seguida.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
Compreensão dos dados e preparação dos dados são
fases do modelo CRISP-DM.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
Listagens, saídas gráficas, tabelas de resumo ou
visualizações são formatos usados na apresentação dos
resultados da mineração de dados.
Quanto à mineração de dados e ao CRISP-DM (Cross-Industry Standard Process for Data Mining), julgue o item.
A mineração de dados é uma técnica que objetiva
adquirir conhecimento a partir dos dados, por meio da
detecção de vários tipos de padrões em grandes
volumes de dados.
Como resultado, foi criado o modelo de árvore de decisão ilustrado a seguir.
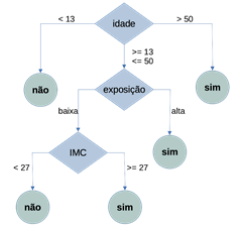
Uma evidência de que esse modelo foi construído usando o algoritmo C4.5 ou uma de suas variantes é:

Utilizando técnicas de Mineração de Dados, Maria encontrou a seguinte informação:
Se um cliente compra Cacau, a probabilidade de ele comprar chia é de 50%. Cacau => Chia, suporte = 50% e confiança = 66,7%.
Para explorar a base de dados do HortVega, Maria utilizou a técnica de Mineração de Dados:
Com relação a data warehouse e data mining, julgue o item a seguir.
A análise de cluster em data mining permite, por meio de
análise exploratória de dados, ordenar casos em clusters, de
modo que o grau de associação seja forte entre os membros
do mesmo cluster e fraco entre membros de clusters
diferentes.
A respeito de data warehouse, data mining e business intelligence, julgue o item subsequente.
Sistemas de data mining viabilizam a extração de novos
padrões significativos de informação que não seriam
necessariamente encontrados por meio de meras consultas ou
processamento de dados ou metadados no data warehouse.