Questões de Concurso
Para instituto aocp
Foram encontradas 54.747 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
( ) O TDD segue um ciclo curto que envolve escrever um teste, fazê-lo falhar e implementar o código mínimo.
( ) No TDD, os testes podem ser utilizados como documentação viva do comportamento esperado do código.
( ) O TDD recomenda que o desenvolvedor escreva apenas o código suficiente para fazer o teste passar.
( ) A utilização de TDD elimina totalmente a necessidade de testes automatizados adicionais no projeto.
import csv with open(‘dados.csv’, ’r’) as file: reader = csv.reader(file) else row do reader: print(row)
O código exposto apresenta, na 4ª linha, erro. Qual das alternativas corrige esse erro?
x<-c(15,20,30,25,38,36,18,23,10,22,35,33,12,28,25)
y<-c(1.57,1.56,1.63,1.60,1.65,1.64,1.58,1.59,1.58,
1.57,1.63,1.61,1.57,1.63,1.57)
plot(x,y) cor.test(x,y) summary(regressao<- lm(y~x)) plot(regressao)
É correto afirmar que as linhas de programa fornecem, respectivamente, os seguintes resultados:
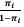 = β0 + β1xi. Com base no exposto, é correto
afirmar que o modelo logístico é dado por
= β0 + β1xi. Com base no exposto, é correto
afirmar que o modelo logístico é dado por Dizemos que a distribuição de uma variável
aleatória X pertence à família exponencial de
dimensão k se a função de probabilidade é dada
por f (x;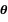 )=exp
)=exp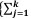 cj()Tj(x)+d()+S(x)}, x ∈
A, em que cj(), Tj(x), d() e S (x) são funções reais
para j = 1,...,k, e A é o suporte da distribuição. Se X
é uma variável aleatória que segue a distribuição
normal com média μ e variância
cj()Tj(x)+d()+S(x)}, x ∈
A, em que cj(), Tj(x), d() e S (x) são funções reais
para j = 1,...,k, e A é o suporte da distribuição. Se X
é uma variável aleatória que segue a distribuição
normal com média μ e variância 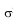 2, ou seja,
X ~ N (μ,2), então X pertence à família exponencial
bidimensional e suas funções reais são dadas por:
2, ou seja,
X ~ N (μ,2), então X pertence à família exponencial
bidimensional e suas funções reais são dadas por:

De acordo com esses resultados, é correto afirmar que o modelo de regressão estimado, o coeficiente de determinação e a estatística do teste de significância do modelo de regressão, respectivamente, são dados por:
Quando o gráfico de dispersão sugere um relacionamento aproximadamente linear entre as duas variáveis, o modelo indicado é representado pela seguinte equação:
yi = βo+β1xi+εi,
em que yi é o i-ésimo valor da variável dependente
ou resposta; βo e β1 são os parâmetros do modelo
ou coeficientes de regressão; xi é o i-ésimo valor
da variável independente ou covariável; εi é o i-ésimo erro aleatório. Considerando que os εi são
idênticos, independentes e distribuídos conforme
o modelo Normal com média 0 e variância 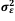 , ou
seja, εi ~ N(0, ), é correto afirmar que
, ou
seja, εi ~ N(0, ), é correto afirmar que
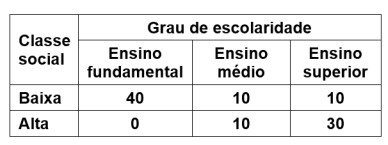
Utilizando as observações da tabela, quanto a existir ou não associação entre grau de escolaridade e classe social, ao nível de 5% de significância, assinale a alternativa correta.
dados <- c(17.7, 19.5, 16.3, 15.6, 16.2, 14.0, 16.6, 14.3, 12.1, 15.3, 13.9, 17.6, 19.7, 13.7, 16.2, 14.9, 15.7, 18.9, 11.5, 16.1, 13.2, 17.0, 16.7, 15.2, 16.7, 10.2, 17.1, 8.9, 18.5, 10.8)
ks.test(dados,"pnorm",mean(dados),sd(dados)) shapiro.test(dados) hist(dados) qqnorm(dados)
O software R forneceu os seguintes resultados para os respectivos testes:
data: dados D = 0.11309, p-value = 0.8376 alternative hypothesis: two-sided
data: dados W = 0.96028, p-value = 0.3149
Diante do exposto, quais foram os testes e os gráficos aplicados e quais foram os resultados fornecidos pelos testes?