Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 3.598 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964472
Engenharia Mecânica
As normas de segurança do trabalho estabelecem que as
medidas de proteção devem priorizar a eliminação ou redução
do risco na fonte, recorrendo-se, quando necessário, a
Equipamentos de Proteção Coletiva (EPCs) ou Equipamentos
de Proteção Individual (EPIs). Assinale a alternativa que
corresponde a um EPC aplicável à operação de máquinas
rotativas.
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964471
Engenharia Mecânica
Os ferros fundidos são amplamente empregados na indústria
mecânica e apresentam, em geral, melhor comportamento
durante operações de usinagem quando comparados a
muitos aços, em função de características próprias de sua
microestrutura. Os ferros fundidos são considerados mais
usináveis porque
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964470
Engenharia Mecânica
Os materiais metálicos, como o aço, reagem às forças
externas aplicadas, apresentando comportamentos
mecânicos que determinam sua aplicação em estruturas,
máquinas e componentes industriais. Essas características
são conhecidas como propriedades mecânicas. Uma
propriedade mecânica do aço é a
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964469
Mecânica
O goniômetro representado a seguir tem resolução de 5’.
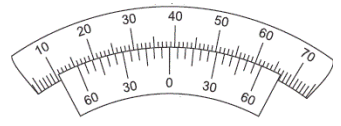
Do modo como apresentado na figura, a leitura correta do goniômetro é de:
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964468
Mecânica
O paquímetro ilustrado a seguir foi utilizado para medir a
dimensão de uma peça, devidamente ajustado a ela e sem
erro de zero.
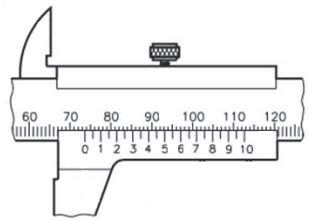
A leitura correta da dimensão da peça medida, apresentada nesse paquímetro é:
A leitura correta da dimensão da peça medida, apresentada nesse paquímetro é:
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964467
Mecânica
O paquímetro é um instrumento de medidas, amplamente
utilizado em medições lineares para obter dimensões
externas, internas e profundidades com precisão elevada. Considerando um paquímetro típico, a menor leitura ou
sensibilidade usual é de:
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964466
Engenharia Mecânica
No processo de Eletroerosão por Penetração (EDM), o fluido
dielétrico desempenha papel essencial para a eficiência,
precisão e segurança do corte, influenciando diretamente a
qualidade do acabamento e a vida útil do eletrodo. A principal
função do dielétrico é
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964465
Engenharia Mecânica
No processo de eletroerosão a fio, a remoção de material
ocorre por descargas elétricas controladas entre um fio
metálico e a peça condutora, permitindo cortes precisos de
contornos complexos em materiais duros. A correta
compreensão da função do fio é essencial para garantir a
precisão dimensional, o acabamento superficial e a eficiência
do processo. Na eletroerosão a fio, o fio utilizado é
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964464
Engenharia Mecânica
No processo de eletroerosão por penetração, a remoção de
material ocorre por descargas elétricas controladas entre o
eletrodo e a peça, imersos em um fluido dielétrico. O
entendimento correto do mecanismo de desgaste é
fundamental para determinar a geometria da peça e do
eletrodo e otimizar a produtividade do processo. Nesse
contexto, o desgaste ocorre
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964463
Engenharia Mecânica
No Desenho Técnico Mecânico, cotas funcionais são aquelas
que indicam e definem a forma, a dimensão e a posição de
partes da peça essenciais para o seu correto funcionamento.
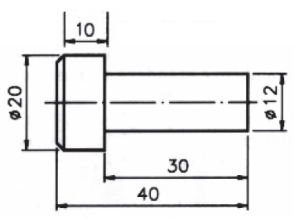
No desenho apresentado, a cota que deve ser considerada funcional é:
No desenho apresentado, a cota que deve ser considerada funcional é:
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964462
Mecânica
No âmbito do Desenho Técnico Mecânico, o procedimento
normatizado que estabelece a forma de indicar medidas
lineares, angulares e seus respectivos símbolos em um
desenho recebe o nome de
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964461
Engenharia Mecânica
Para assegurar a funcionalidade e a intercambialidade de
componentes, o sistema de ajustes ISO prevê três classes de
ajustes entre o furo e eixo: os ajustes móveis (ou deslizantes),
os ajustes indeterminados (ou de transição) e os ajustes
prensados (ou por interferência). Os ajustes móveis são
aqueles que
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964460
Engenharia Mecânica
Pelo sistema ISO, é possível acoplar livremente distintos furos
e eixos. Contudo, na sua aplicação, é conveniente a utilização
de somente um sistema: ou furo-base ou eixo-base. No
sistema furo-base, a linha zero é
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964459
Engenharia Mecânica
No sistema ISO de tolerância e ajustes, as dimensões são
definidas a partir da linha zero. A posição das zonas toleradas
com relação a essa linha é indicada por letras, cuja grafia
distingue o tipo de elemento dimensionado, permitindo a
correta especificação de eixos e furos. Neste sistema, letras
minúsculas e maiúsculas são empregadas, respectivamente,
para indicar zonas toleradas de
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964458
Mecânica
No Desenho Técnico Mecânico, a tolerância é um conceito
fundamental para garantir a intercambialidade e a
funcionalidade das peças fabricadas. De acordo com as
normas técnicas, a tolerância é definida como
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964457
Engenharia Mecânica
No torno CNC, a correta preparação da máquina envolve a
definição adequada dos offsets de ferramenta, que permitem
ao comando numérico compensar diferenças geométricas
entre as ferramentas montadas no porta-ferramentas. Esses
offsets têm como principal finalidade
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964456
Engenharia Mecânica
Segundo o padrão ISO de programação, linguagem G, em
modo de coordenadas incrementais, e considerando que o
eixo X adota a orientação positiva para a direita, a
interpretação correta do comando X–5 é
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964455
Matemática
No plano cartesiano formado pelos eixos X e Z, está inserido
o esboço de uma peça cujas coordenadas dos vértices estão
nos pontos A, B, C, D e E, conforme indicados.
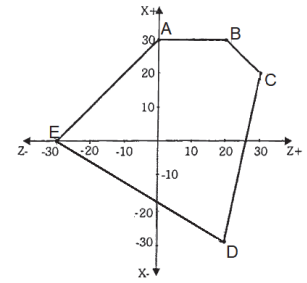
O par ordenado está corretamente apresentado em:
O par ordenado está corretamente apresentado em:
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964454
Mecânica
No Desenho Técnico Mecânico, os cortes são empregados
para representar, com exatidão, detalhes ou perfis não
revelados claramente em outras vistas.
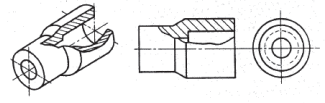
O tipo de corte mostrado na peça da figura é chamado de
O tipo de corte mostrado na peça da figura é chamado de
Ano: 2026
Banca:
FUVEST
Órgão:
USP
Prova:
FUVEST - 2026 - USP - Técnico de Laboratório (Especialidade: Mecânica) |
Q3964453
Mecânica
De acordo com as normas adotadas pela ABNT aplicáveis ao
Desenho Técnico, a projeção ortogonal de um objeto é obtida
a partir de planos perpendiculares entre si. Nesse sistema, a
projeção realizada sobre o plano vertical corresponde à vista