Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 4.268 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331328
Engenharia de Software
Sobre as redes neurais convolucionais, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331327
Engenharia de Software
Sobre os autoencoders, podemos dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331326
Noções de Informática
O ChatGPT é um modelo de linguagem desenvolvido
pela OpenAI, baseado na arquitetura GPT (Generative
Pre-trained Transformer). Sobre o Chat-GPT, é correto
afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331325
Engenharia de Software
São desafios do processo de agrupamento de dados,
EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331324
Estatística
Uma das dificuldades de se realizar agrupamentos de
dados é a definição do número de grupos. É correto afirmar
que contém apenas técnicas ou métricas que podem ser
úteis para automatizar a decisão do número K de grupos:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331323
Estatística
Sobre o algoritmo K-médias, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331322
Estatística
Dentre as seguintes listas, NÃO contêm apenas algoritmos que podem ser usados para realizar uma regressão, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331321
Engenharia de Software
Recentemente muito tem sido discutido em relação à
interpretabilidade dos modelos de aprendizado de máquina.
Eles têm sido comparados a caixas-pretas,pois, embora
venham apresentando resultados impressionantes com
sua acurácia, não se tem muitas vezes ideia do que acontece dentro deles. Em outras palavras, as previsões são
úteis e precisas, mas não se sabe como elas foram feitas
e quais atributos ou fatores podem ter maior influência nos
resultados.
Trata-se de modelos complexos que absorvem relações não lineares e não triviais nos dados. É preciso que o analista de dados tenha uma visão crítica e entendimento dos algoritmos. Suponha que você tenha sido contratado para criar um sistema que utilize modelos de aprendizado de máquina para classificar pacientes segundo a propensão a apresentar uma determinada doença, mas um requisito essencial do sistema é que seja possível explicar claramente como se chegou a essa previsão. Dentre os seguintes algoritmos, é correto afirmar o que se utilizaria é:
Trata-se de modelos complexos que absorvem relações não lineares e não triviais nos dados. É preciso que o analista de dados tenha uma visão crítica e entendimento dos algoritmos. Suponha que você tenha sido contratado para criar um sistema que utilize modelos de aprendizado de máquina para classificar pacientes segundo a propensão a apresentar uma determinada doença, mas um requisito essencial do sistema é que seja possível explicar claramente como se chegou a essa previsão. Dentre os seguintes algoritmos, é correto afirmar o que se utilizaria é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331320
Algoritmos e Estrutura de Dados
Sobre o algoritmo KNN (K-Vizinhos mais próximos)
tradicional, podemos afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331319
Engenharia de Software
Todos podem cometer erros, inclusive os algoritmos
de aprendizado de máquina. Existem técnicas que podem
ser usadas para aumentar nossa confiança de que eles
farão previsões confiáveis. A ideia é usar uma coleção de
classificadores treinados em dados levemente diferentes
e usar todos para avaliar cada instância de entrada. Cada
um deles realiza a classificação e escolhemos a classe
mais votada como resultado. É correto afirmar que contém
apenas técnicas que podem ser usadas para aumentar a
confiabilidade nas previsões segundo essa ideia:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331318
Engenharia de Software
“Sua estrutura básica é organizada em camadas.
Neurônios em cada camada podem se comunicar com os
neurônios da camada anterior e da próxima. É o formato
desta estrutura que resulta no nome aprendizado profundo.”
(Andrew Glassner)
Segundo Glassner, o que caracteriza uma rede de aprendizado profundo são:
Segundo Glassner, o que caracteriza uma rede de aprendizado profundo são:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331317
Sistemas de Informação
Os sistemas computacionais com ou sem o uso de
técnicas de aprendizado são apresentados na Coluna I.
Estabeleça a correta correspondência com as definições
ou exemplos da Coluna II.
Coluna I
1. Sistema especialista. 2. Aprendizado supervisionado. 3. Aprendizado não supervisionado. 4. Aprendizado por reforço.
Coluna II
( ) o sistema recebe um conjunto de registros médicos eletrônicos de pacientes e os agrupa de acordo com as similaridades entre as características presentes nos registros.
( ) o sistema recebe um conjunto de imagens de lâminas referentes a exames de pacientes e assinala com base em sua experiência prévia a patologia associada ou se se trata de um paciente sadio. Um especialista humano então avalia a decisão do sistema retornando para o mesmo uma pontuação que mede o seu desempenho. O sistema evolui de acordo com essa pontuação.
( ) o sistema é programado com regras pré-definidas por alguém treinado no problema.
( ) o sistema recebe um conjunto de imagens de lâminas referentes a exames de pacientes com rótulos indicando a patologia associada ou um paciente sadio.
A sequência correta, de cima para baixo, é:
Coluna I
1. Sistema especialista. 2. Aprendizado supervisionado. 3. Aprendizado não supervisionado. 4. Aprendizado por reforço.
Coluna II
( ) o sistema recebe um conjunto de registros médicos eletrônicos de pacientes e os agrupa de acordo com as similaridades entre as características presentes nos registros.
( ) o sistema recebe um conjunto de imagens de lâminas referentes a exames de pacientes e assinala com base em sua experiência prévia a patologia associada ou se se trata de um paciente sadio. Um especialista humano então avalia a decisão do sistema retornando para o mesmo uma pontuação que mede o seu desempenho. O sistema evolui de acordo com essa pontuação.
( ) o sistema é programado com regras pré-definidas por alguém treinado no problema.
( ) o sistema recebe um conjunto de imagens de lâminas referentes a exames de pacientes com rótulos indicando a patologia associada ou um paciente sadio.
A sequência correta, de cima para baixo, é:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331316
Engenharia de Software
Sobre a função de ativação de redes neurais, é CORRETO afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331315
Estatística
São algoritmos de classificação, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331314
Engenharia de Software
Observe as afirmativas a seguir, em relação a seleção
de atributos para algoritmos de aprendizado de máquina:
I. Se temos atributos na base de dados que sejam redundantes, irrelevantes ou inúteis, devemos eliminá-los.
II. Podemos eliminar atributos que contribuem muito pouco na construção de um modelo como os que tem um mesmo valor na grande maioria das instâncias.
III. Os atributos removidos do conjunto de treinamento devem ser também removidos do conjunto de testes.
Sobre as afirmativas acima, pode-se dizer que:
I. Se temos atributos na base de dados que sejam redundantes, irrelevantes ou inúteis, devemos eliminá-los.
II. Podemos eliminar atributos que contribuem muito pouco na construção de um modelo como os que tem um mesmo valor na grande maioria das instâncias.
III. Os atributos removidos do conjunto de treinamento devem ser também removidos do conjunto de testes.
Sobre as afirmativas acima, pode-se dizer que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331313
Estatística
Considere o problema de calcular agrupamentos dos
objetos apresentados na figura abaixo:
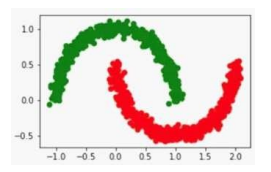
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Considerando a distribuição dos objetos no espaço de acordo com seus atributos ilustrada na figura, o algoritmo de agrupamento indicado para diferenciar os dois grupos seria:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331312
Sistemas de Informação
Quando realizamos o agrupamento de objetos de acordo
com seus atributos, ou seja, uma tarefa de aprendizado
não supervisionado, precisamos avaliar a qualidade deste
agrupamento sem informação de supervisão. Como não se
tem as classes ou rótulos das instâncias, é preciso avaliar
a qualidade dos grupos apenas através de aferições estatísticas de similaridade intra e inter-grupos. Dentre estes
índices, podemos citar, EXCETO:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331311
Algoritmos e Estrutura de Dados
Sobre o algoritmo Apriori para mineração de regras de
associação, é correto afirmar que:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331310
Medicina
A bioética aborda temas delicados, alguns considerados
tabus. Dentre os temas abaixo,o que NÃO é relacionado
à bioética:
Ano: 2024
Banca:
FIOCRUZ
Órgão:
FIOCRUZ
Prova:
FIOCRUZ - 2024 - FIOCRUZ - Tecnologista em Saúde Pública - Ciência de dados em saúde |
Q3331309
Medicina
São princípios da ética biomédica, EXCETO: