Questões de Concurso Sobre engenharia de software
Foram encontradas 14.486 questões
Acerca dos tipos de aprendizado, da inteligência artificial generativa e das redes neurais, julgue o item subsequente.
A inteligência artificial generativa inclui modelos como as redes generativas adversárias e os modelos baseados em transformadores, os quais são capazes de criar novos conteúdos, como imagens, textos ou áudios.
Acerca dos tipos de aprendizado, da inteligência artificial generativa e das redes neurais, julgue o item subsequente.
O aprendizado por reforço é utilizado principalmente em tarefas de classificação supervisionada, nas quais o agente aprende com base em dados rotulados fornecidos previamente.
Em relação a serviços de nuvem, sistemas operacionais e conceitos de DevOps, julgue o item subsequente.
DevOps é um conjunto de práticas que integra desenvolvimento e operações de software, promovendo colaboração entre equipes para entregar aplicações e serviços de forma mais rápida, visando alinhar a área de TI com a estratégia organizacional.
Em relação a serviços de nuvem, sistemas operacionais e conceitos de DevOps, julgue o item subsequente.
O AD DS (Active Directory Domain Services) do Microsoft Windows Server conta com política de senha refinada, restrita ao uso via linha de comando.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
O privacy by design fundamenta-se em princípios indivisíveis que devem ser implementados de forma integral e holística, não permitindo seleção parcial ou adaptação baseada em preferências setoriais específicas.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
O privacy by design é mais eficiente quando implementado como uma camada de segurança adicional sobre sistemas já existentes.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
Na estrutura de desenvolvimento de software seguro do NIST, o grupo de prática “Preparar a Organização” inclui a recomendação de que todos os componentes dos ambientes de desenvolvimento de software sejam fortemente protegidos contra ameaças internas e externas, a fim de prevenir comprometimentos.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
Na prática “Produzir Software Bem Protegido” do SSDF (secure software development framework), o NIST incentiva o reúso de credenciais de autenticação entre diferentes ambientes de desenvolvimento para facilitar o acesso dos desenvolvedores e agilizar o processo de integração contínua.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
Os princípios da arquitetura e da governança Zero Trust no SDL incluem a presunção de que o sistema já está comprometido, a verificação explícita da confiança e a concessão do menor privilégio necessário para cada conta de usuário, cada identidade de máquina/serviço e cada componente da aplicação.
A respeito do desenvolvimento de software seguro, julgue o item a seguir.
Uma prevenção recomendada pelo OWASP Top 10 contra quebra de controle de acesso é a implementação de verificações de autorização nos modelos de domínio que apliquem as restrições de negócios da aplicação.
A respeito da proteção de dados pessoais no Brasil, dos grandes modelos de linguagem (LLMs) e do uso de redes neurais no setor jurídico, julgue o item que se segue.
Modelos transformer superam, devido ao mecanismo de autoatenção, as redes neurais recorrentes tradicionais na captura de dependências de longo alcance em documentos jurídicos extensos, sendo esta a principal razão para a adoção dos transformers em tarefas como sumarização e busca semântica no campo jurídico.
A respeito da proteção de dados pessoais no Brasil, dos grandes modelos de linguagem (LLMs) e do uso de redes neurais no setor jurídico, julgue o item que se segue.
Os LLMs se destacaram recentemente em decorrência do aprimoramento das técnicas de treinamento com feedback humano; da maior acessibilidade via interfaces de uso simples como ChatGPT e Gemini; do avanço da potência computacional com GPUs; e da melhoria dos dados de treinamento.
A respeito da proteção de dados pessoais no Brasil, dos grandes modelos de linguagem (LLMs) e do uso de redes neurais no setor jurídico, julgue o item que se segue.
De acordo com a Lei Geral de Proteção de Dados Pessoais, no contexto de um sistema informatizado de um órgão público, é atribuição do encarregado de dados tomar decisões referentes ao tratamento de dados pessoais, a exemplo da definição das finalidades do respectivo tratamento.
Julgue o item subsequente, no que concerne ao uso da biblioteca Hugging Face Transformers com PyTorch e aos sistemas baseados na arquitetura RAG (retrieval-augmented generation).
Considerando-se que os sistemas baseados na arquitetura RAG são projetados para mitigar limitações dos grandes modelos de linguagem, como a alucinação factual e a dificuldade de atualização constante, é correto afirmar que o uso do RAG permite incorporar documentos normativos, jurisprudência ou doutrina diretamente no processo de geração de respostas, viabilizando consultas mais confiáveis, com rastreabilidade das fontes e sem a necessidade de retreinamento do modelo-base.
Julgue o item subsequente, no que concerne ao uso da biblioteca Hugging Face Transformers com PyTorch e aos sistemas baseados na arquitetura RAG (retrieval-augmented generation).
Embora a biblioteca Hugging Face ofereça suporte a múltiplos frameworks, alguns modelos específicos — especialmente os mais antigos, originalmente treinados em TensorFlow — podem apresentar dificuldades de integração em pipelines de inferência desenvolvidos em PyTorch, como os utilizados em aplicações jurídicas; nesses casos, pode ser recomendável adaptar ou reconstruir o modelo em PyTorch para assegurar compatibilidade e controle total sobre o fluxo de dados.
Acerca do processamento de linguagem natural e dos conceitos de modelos preditivos (supervisionados) e descritivos (não supervisionados), julgue o item a seguir.
Em análise preditiva, algoritmos de classificação podem ser treinados a partir de conjuntos de dados sem rótulos; sendo o processo de ajuste dos parâmetros pelo algoritmo com base nesses dados denominado aprendizado supervisionado.
Acerca do processamento de linguagem natural e dos conceitos de modelos preditivos (supervisionados) e descritivos (não supervisionados), julgue o item a seguir.
Em um pipeline de pré-processamento de linguagem natural aplicado ao domínio jurídico, a tokenização deve, necessariamente, ser precedida pela lematização, uma vez que a lematização opera sobre formas canônicas já segmentadas.
Observe o seguinte diagrama da UML.
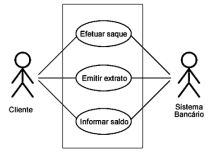
Fonte: https://ead.ifsul.edu.br/
O cenário supracitado mostra um diagrama da UML conhecido como