Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 758 questões
Com relação à Low/No Code e robot process automation (RPA), julgue o próximo item.
A tecnologia RPA é caracterizada por plataformas de
desenvolvimento que possuem interfaces gráficas e robóticas
e tem o objetivo de possibilitar que o desenvolvedor construa
seu projeto com a ajuda de robôs.
Julgue o item a seguir, a respeito de inteligência artificial (IA) e machine learning.
Nos algoritmos de aprendizado por reforço, o agente recebe
uma recompensa atrasada na próxima etapa de tempo para
avaliar sua ação anterior; seu objetivo, então, é maximizar a
recompensa.
Em aprendizado de máquina, as características de entrada e saída são definidas, respectivamente, como atributos previsores e atributos alvo ou meta.
A matriz de confusão permite avaliar o desempenho de um modelo de classificação a partir da frequência de erros e acertos.
Sobra algaritmos de clusterização, analise as afirmativas a seguir.
I. Os resultados de um algoritmo de clusterização baseados em grafo são normalmente mostrados como um dendrograma.
II. Os métodos baseados em densidade são adequados para descobrir clusters com forma arbitrária, tais como elíptica, cilíndrica ou espiralada.
III. K-Means e K-Medaids são algoritmos de clusterização aglomerativa que dividen a base de dados em k-grupos, onde o número k é dado pelo usuário.
Está correto o que se afirma em
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
I. É um classificador ingênuo que assume que a presença ou ausência de uma característica particular de uma classe não está relacionada com a presença ou ausência de outras características.
II. As variáveis de entrada são geralmente categóricas, mas variações do algoritmo podem aceitar variáveis contínuas. Também existem maneiras de converter variáveis contínuas em categóricas. Esse processo é denominado discretização de variáveis contínuas.
III. A filtragem de spam é um exemplo clássico do uso de Naïve Bayes para distinguir e-mail de spam de e-mail legítimo. Muitos clientes de e-mail modernos implementam variantes de filtragem bayesiana de spam.
Quais estão corretas?
Assinale a alternativa que preenche, correta e respectivamente, as lacunas do trecho acima.
Após transformar cada mensagem em uma string, um dos passos importantes nessa técnica é a tokenização, que consiste em
Os três níveis dessa hierarquia, listados, respectivamente, da base para o nível mais alto, são:
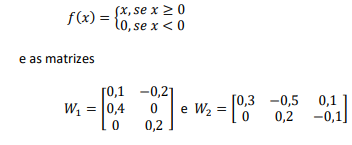
representam os pesos entre a camada de entrada e a camada oculta e entre a camada oculta e a camada de saída, respectivamente.
Considerando um vetor de entrada
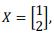 o vetor de saída
será:
o vetor de saída
será: Assinale a técnica de NLP adequada nesse tipo de desenvolvimento.