Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 755 questões
Ao implementar a função ReLU, um pesquisador deve seguir a fórmula:
O treinamento do modelo Skip-Gram destaca-se de outras técnicas, como o Continuous Bag of Words (CBOW), por ter a seguinte característica:
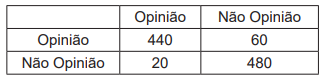
Considerando-se que, nessa matriz, as linhas indicam a resposta correta e as colunas indicam a previsão, a acurácia é de
Em preparação para análise de um conjunto de dados, o tratamento de outliers
Qual das palavras a seguir apresenta o maior valor da similaridade de Jaccard, quando comparada com a palavra “computador”?
Considerando-se a intenção de lidar com dados não linearmente separáveis por meio do uso de um kernel, qual é o algoritmo mais adequado para essa tarefa?
É um exemplo de tarefa de regressão em aprendizado de máquina a
Avalie se as três etapas básicas envolvidas nesse processo são as seguintes:
I. Aquisição da imagem.
II. Processamento da imagem.
III. Segmentação da imagem.
Está correto o que se apresenta em
Julgue o item subsequente, com relação a aprendizado de máquina, que é uma forma de inteligência artificial com vasta aplicação na área de diagnóstico por imagem.
No aprendizado não supervisionado, o modelo é treinado
com base em um conjunto de entradas (por exemplo, dados
extraídos de imagens médicas de vários pacientes) e de
saídas corretas associadas a cada uma dessas entradas (por
exemplo, o diagnóstico de cada paciente).
Acerca do desenvolvimento de pipelines e do processamento distribuído para aprendizado de máquina, julgue o seguinte item.
MLflow é uma ferramenta exclusiva para uma única tarefa, como treinamento ou implantação de modelos, proporcionando
funcionalidades para experimentação, rastreamento de parâmetros e métricas, reprodução de modelos, empacotamento e
implantação.
Julgue o próximo item, relativos a linguagens, ferramentas e bibliotecas que facilitam a criação, o treinamento e a implantação de modelos de software com aprendizado de máquina.
Bibliotecas como TensorFlow e PyTorch são exclusivas para
algoritmos de aprendizado profundo e não são adequadas
para tarefas de aprendizado de máquina tradicionais.
A respeito de ontologia, julgue o próximo item.
Ontologias podem ser entendidas como aplicações criadas
para simular a ação de especialistas humanos, com o
propósito de solucionar problemas específicos em um dado
domínio.
A respeito de ontologia, julgue o próximo item.
A representação formal de ontologias é utilizada para que
estas sejam consumidas por computadores, enquanto a
representação gráfica é utilizada para compreensão humana.
Julgue o item a seguir, a respeito de algoritmos e técnicas supervisionadas e não supervisionadas de aprendizado de máquina e aprendizagem profunda.
As redes neurais permitem construir modelos que sejam
padronizados de acordo com o funcionamento do cérebro
humano.
Julgue o item a seguir, a respeito de algoritmos e técnicas supervisionadas e não supervisionadas de aprendizado de máquina e aprendizagem profunda.
O algoritmo Apriori emprega busca em profundidade e gera
conjuntos de itens candidatos (padrões) de k elementos a
partir de conjuntos de itens de k − 1 elementos, sendo os
padrões não frequentes eliminados.
Julgue o item a seguir, a respeito de algoritmos e técnicas supervisionadas e não supervisionadas de aprendizado de máquina e aprendizagem profunda.
Os algoritmos baseados em árvore de decisão definem modelos com uma técnica para estimar a probabilidade de um evento ocorrer sob determinada circunstância, usando-se uma estimativa a priori da probabilidade de sua ocorrência.
Com relação a ciência de dados e inteligência artificial, julgue o próximo item.
Na inteligência artificial, o agente inteligente deve ser capaz
de ter autonomia, isto é, deve ter a capacidade de acumular
conhecimento que seja útil em suas ações.