Questões de Concurso
Sobre inteligencia artificial em engenharia de software
Foram encontradas 758 questões
A respeito de redes neurais artificiais, redes neurais convolucionais e processamento de linguagem natural, julgue o item a seguir.
Umas das principais diferenças entre o backpropagation e o
SGD (stochastic gradient descent) é a forma como os pesos
são atualizados, visto que o SGD utiliza o gradiente
calculado para todos os dados de treinamento, ao passo que o
backpropagation usa o gradiente calculado apenas para um
mini-batch de dados de treinamento.
Julgue o próximo item, em relação a aprendizado supervisionado e não supervisionado.
Ocorre sobreajuste quando um modelo de dados é incapaz de
capturar o relacionamento entre as variáveis de entrada e
saída com precisão, o que gera uma alta taxa de erro tanto no
conjunto de treinamento quanto nos dados não exibidos.
Julgue o próximo item, em relação a aprendizado supervisionado e não supervisionado.
No aprendizado supervisionado, os algoritmos de
Naive Bayes e o de máquinas de vetores de suporte são
utilizados tanto na classificação quanto na regressão.
Julgue o próximo item, em relação a aprendizado supervisionado e não supervisionado.
A regressão logística é usada para fazer uma previsão sobre
uma variável categórica comparada a uma contínua; assim
como a regressão linear, a regressão logística também pode
ser usada para estimar o relacionamento entre uma variável
dependente e uma ou mais variáveis independentes.
Nesse contexto, o problema observado por João, do modelo ajustar-se excessivamente aos dados de treinamento, é denominado:
1. IA fraca
2. IA forte
3. IA generativa
4. Teste de Turing
( ) É capaz de resolver uma única tarefa, pode automatizar tarefas demoradas e analisar dados de maneiras que os humanos às vezes não podem.
( ) É uma categoria de algoritmos de IA que gera novos resultados com base nos dados em que foram treinados.
( ) É capaz de resolver uma gama extensa e arbitrária de tarefas, incluindo aquelas que são novas, e executá-las com eficácia comparável à de um ser humano.
( ) É uma medida de inteligência de uma máquina, onde se a máquina pode se passar por um humano em uma conversa de texto, ela passa no teste.
Assinale a opção que indica a relação correta, segundo a ordem apresentada.
( ) Aprendizado supervisionado é um tipo de aprendizado de máquina em que o modelo é treinado em um dataset rotulado.
( ) Aprendizado não supervisionado é um tipo de aprendizado de máquina em que o modelo é treinado em um dataset não rotulado e a estrutura subjacente dos dados é descoberta pelo algoritmo.
( ) Aprendizado por reforço é um tipo de aprendizado de máquina em que o modelo é treinado para prever o resultado de uma variável dependente com base em variáveis independentes.
As afirmativas são, respectivamente,
A respeito das inovações que apontam para o desenvolvimento na área de ciência da computação, Internet e inteligência artificial, julgue o item.
A inteligência artificial tem se desenvolvido a ponto
de criar chatbot que leva jovens a fazerem terapia de
ajuda às dificuldades da vida.
Acerca dos tipos de computadores, do Microsoft Word 2016 e do aprendizado de máquina, julgue o item.
O aprendizado de máquina pode ser definido como
uma técnica de ciência de dados que permite que os
computadores usem os dados existentes para prever
futuros comportamentos, resultados e tendências.
Acerca dos tipos de computadores, do Microsoft Word 2016 e do aprendizado de máquina, julgue o item.
O aprendizado não supervisionado é uma área da
inteligência artificial que envolve o uso de algoritmos
para encontrar padrões ocultos em conjuntos de
dados rotulados.
Nesse cenário, qual é o algoritmo mais apropriado para fazer o agrupamento desejado?
Nesse contexto, considere a construção de uma árvore de regressão usando a classe DecisionTreeRegressor do ScikitLearn e seu treinamento em um conjunto de dados quadrático com max_depth=2, conforme mostrado a seguir:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X, y)
A árvore resultante é representada na Figura a seguir.
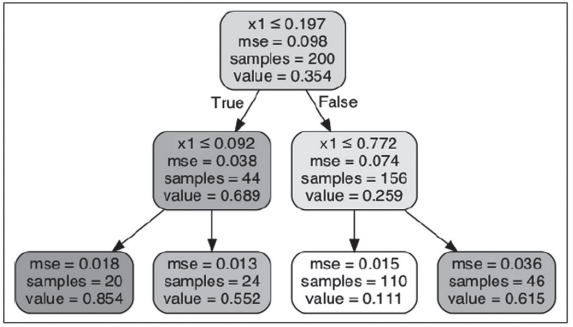
GÉRON, A. Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniquesto Build Intelligent Systems. 2 ed. Sebastopol, CA: O’Reilly Media, Inc.: 2019, p. 183.
Considerando-se o cenário apresentado e que se deseja fazer uma predição para uma nova instância, com x1 = 0.6, qual será o valor predito?
A construção de um modelo preditivo a partir dos dados dessas bases, usando árvores aleatórias, Random Forests,
Qual das seguintes técnicas auxilia a prevenir o overfitting em SVM?
Com base nessas informações e considerando-se apenas a parte inteira da porcentagem, qual é o F1 Score desse modelo?
Nesse contexto, qual função do SciKit-learn ele deve utilizar para realizar essa divisão de maneira eficiente e adequada?