Questões de Concurso Sobre banco de dados
Foram encontradas 18.739 questões
Observe a inserção dos registros pelo seguinte script SQL.
INSERT INTO Parte (ParteID, idade)
VALUES (1 ,17);
INSERT INTO Parte (ParteID, idade)
VALUES (2 ,16);
INSERT INTO Processo (processoID, data_audiencia,
valor_causa)
VALUES (1 ,'2025-02-05',1000);
INSERT INTO Processo (processoID, data_audiencia,
valor_causa)
VALUES (2 ,'2025-10-05',2000);
INSERT INTO ProcessoParte (processoID, parteid)
VALUES (1 ,1);
INSERT INTO ProcessoParte (processoID, parteid)
VALUES (2 ,2);
No PostgreSQL, para consultar os Processos (Processos) que envolvem partes menores que 18 anos, por ordem de maior Valor de Causa (valor_causa), cuja Audiência (data_audiencia) está agendada para os próximos 30 dias, deve-se executar o comando SQL:
A partir do observado, Otávio concluiu que o banco de dados era um:
Observe a transação SQL a seguir.

No PostgreSQL, após a execução da transação SQL, o(s) registro(s) da tabela Parte é(são):
Observe os registros incluídos na tabela Processo pelo seguinte script SQL:

Para consultar apenas os Processos (Processo) que possuem o termo “trabalhista” no campo descrição (descricao), deve-se complementar a consulta com a cláusula where e a seguinte condição:
O administrador de banco de dados Pedro criou o papel dadosadm para cadastrar os funcionários do MPU que desempenham a função de Administrador de Dados usando o seguinte comando SQL no PostgreSQL:
CREATE ROLE dadosadm WITH LOGIN PASSWORD 'admin';
Para que o papel dadosadm possa alterar a estrutura, bem como adicionar e remover linhas e colunas da tabela processo com controle total, Pedro deve usar o seguinte comando SQL:
Observe o modelo de dados, que utiliza a Notação Crow's Foot (Pé de Galinha), onde PK representa a Chave Primária:
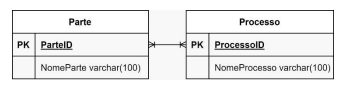
Após a normalização, no PostgreSQL, para implementar o modelo de dados físico com as integridades referenciais, deve-se executar o seguinte script SQL:
A analista de Business Intelligence Lúcia está elaborando o modelo multidimensional do Data Mart Processos Judiciais (DMProcJ). Durante sua análise, ela observou que o número do processo judicial (num_processo) não é uma métrica, mas sim um atributo importante, pois representa o menor grão do DMProcJ e pode ser usado para navegar até o sistema transacional de origem para analisar outras informações de um processo específico.
Para modelar o atributo num_processo, Lúcia deve implementar um(a):
O gestor de qualidade do MPU solicitou à analista de Business Intelligence Maria um Dashboard para monitorar o desempenho da tramitação dos processos ao longo do tempo.
O programador Pedro havia implementado o banco de dados MongoProc, no MongoDB, para armazenar os dados do sistema de tramitação de processos judiciais. Então, Maria solicitou a ele a consulta ao MongoProc para alimentar as tabelas: fato_proc (quantidade), dim_data, dim_estado. Pedro respondeu que não poderia fornecer apenas uma consulta, pois seria necessário transformar os dados NoSQL em relacional. Para implementar a solução, Maria poderá utilizar apenas as ferramentas disponíveis no MPU: MongoDB, PostgreSQL, MySQL, Flyway, Pentaho, QlikView e MicroStrategy.
Para transformar os dados NoSQL visando a alimentar as tabelas e construir o Dashboard, Maria deve:
João está aprendendo banco de dados orientado a documento. Para começar, João buscou a correspondência com a sua área de conhecimento, que é a álgebra relacional e o banco de dados relacional.
Em seu estudo, João identificou que uma relação (relation) da álgebra relacional corresponde, no MySQL e no MongoDB, respectivamente, a:
A álgebra relacional é uma linguagem de consulta formal, composta por diversas operações sobre conjuntos de dados, que fornece uma base teórica sólida para a otimização de consultas SQL em bancos de dados relacionais.
A operação “seleção” da álgebra relacional é realizada pela cláusula SQL:

Na álgebra relacional, a expressão correspondente que João deve escrever é:
Para apoiar suas perícias, Flávio deve usar uma ferramenta:
I. Em um SGBD, os serviços de reparos são essenciais para garantir a integridade dos dados, especialmente após falhas no sistema, como quedas de energia ou corrupção de arquivos.
II. Um SGBD oferece mecanismos de recuperação automática, como logs de transações e pontos de restauração (checkpoints), que permitem restaurar o banco de dados para um estado consistente após uma falha.
III. Os serviços de reparos em um SGBD envolvem a correção de dados e a recuperação de transações para garantir a consistência do banco de dados.
Estão corretas as afirmativas
A computação científica consiste em um conjunto de técnicas, ferramentas e teorias que englobam inteligência artificial, matemática, estatística, física e computação e que abrangem conhecimentos específicos de subáreas tais como estatística aplicada, econometria, matemática aplicada, inteligência computacional, visualização científica e biometria, sendo cada vez mais utilizada no desenvolvimento de novas tecnologias agrícolas, agora no contexto da emergente agricultura digital. Nas últimas décadas, inclusive, a computação científica tem sido apontada como o terceiro pilar da pesquisa científica, junto com a experimentação e a teoria.
Agricultura de Precisão: Um Novo Olhar na Era Digital. EMBRAPA, 2024 (com adaptações).
Considerando as ideias do texto precedente, julgue o próximo item.
Os data lakes proporcionam a possibilidade de se investigar relações de causa e efeito entre variáveis, utilizando-se técnicas de análise de dados observacionais, como técnicas de redes bayesianas e modelos de equações estruturais. Esse grupo de técnicas de análise de dados propicia resultados de análises sem intervenção no sistema, para não ocorrer alterações nos resultados.
Com relação a processos de banco de dados ETL (extração, transformação e carga), julgue o item subsequente.
Na extração incremental, apenas os dados alterados desde a última carga são extraídos, tornando o processo mais eficiente que a extração full, que recupera todos os dados da fonte.
Com relação a processos de banco de dados ETL (extração, transformação e carga), julgue o item subsequente.
Na modelagem de data warehouses, a abordagem top-down torna o processo ETL mais flexível e adaptável a mudanças nos requisitos de negócio, enquanto a abordagem bottom-up exige um ETL rígido e pouco adaptável a novas necessidades.
Com referência à matemática computacional e à ciência da computação aplicadas, julgue o item a seguir.
A convolução é uma operação matemática que combina duas funções para produzir uma terceira, modificando a forma de uma função com base em outra.