Questões de Concurso Sobre algoritmos e estrutura de dados
Foram encontradas 3.780 questões
Cenário de navegação:
Um usuário realizou a seguinte sequência complexa de ações:
visitou: home.com;
navegou para: noticias.com;
navegou para: esportes.com;
navegou para: tecnologia.com;
clicou "Voltar" (retornou para esportes.com);
clicou "Voltar" (retornou para noticias.com); e
navegou para uma nova página: educacao.com.
Considerando o comportamento das pilhas de histórico, a situação atual do navegador é
Julgue o próximo item, a respeito de computação e estrutura de dados.
Ao se utilizar o método de ordenação por seleção, sempre serão necessárias 10 comparações para ordenar um conjunto com cinco elementos.
Julgue o próximo item, a respeito de computação e estrutura de dados.
Se os elementos A, B, C e D forem inseridos em uma pilha, nessa ordem, eles serão excluídos na ordem A, B, C e D, um elemento de cada vez.
Considere o pseudocódigo a seguir, que utiliza uma função recursiva para manipular uma variável global.

Após a execução completa da chamada Calcular(3), o valor final da variável global X será
FIGURA 2
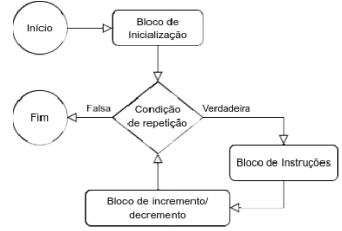
I. Uma repetição infinita não é possível nesse tipo de estrutura. II. Se a condição de repetição for executada 10 vezes, o bloco de instruções será executado 10 vezes. III. O bloco de inicialização só é executado uma única vez pela estrutura. IV. O bloco de incremento / decremento pode realizar incrementos multiplicativos.
Assinale a alternativa que contenha APENAS as afirmações corretas.
FIGURA 2
É correto afirmar que o diagrama de fluxo ilustrado na Figura 2 representa uma estrutura de controle de fluxo conhecida como
Considere o algoritmo a seguir:

O resultado da execução do algoritmo é
Considere o algoritmo a seguir:
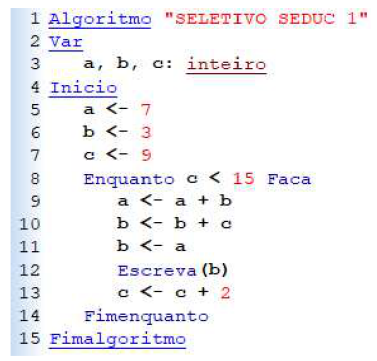
O resultado da execução do algoritmo é

Marque a alternativa CORRETA.
I. Apesar de não ser consensual e considerando a correlação existente entre a teoria e a prática, o estudo de algoritmos é fortemente dependente da linguagem de programação, bem como da tecnologia do processador, pois os construtores das linguagens podem facilitar ou dificultar a implementação e o tipo do processador pode prover melhor ou pior desempenho.
II. A linguagem “Português Estruturado”, utilizada no processo de ensino/aprendizagem de algoritmos, disponibiliza ao aprendiz comandos e estruturas de controle, de decisão e de repetição, além de outras, que permitem expressar a lógica e as ações algorítmicas desejadas, de acordo com o raciocínio humano. Entretanto, considerando-se as características tecnológicas, tais recursos funcionam de forma diferente dos recursos similares existentes nas linguagens de programação comerciais, gerando dificuldades adicionais ao aluno na aplicação das técnicas algorítmicas estudadas.
III. No estudo e na análise da complexidade algorítmica a análise assintótica pode ser utilizada para mensurar o custo algorítmico quando as entradas do problema são muito grandes. Uma forma de medir tal custo é usar a notação big-O. Considerando-se o uso de tal notação, os custos da complexidade de certos algoritmos podem crescer do menor ao maior na seguinte forma: O(1), O(n), O(log de n), O(n log de n), O(n ao quadrado) e O(2 elevado a n).
IV) Algoritmo pode ser definido, de forma simplificada, como uma sequência de ações que pode ser executada para resolver uma tarefa ou solucionar um problema. Sob outra ótica, também podemos dizer que um algoritmo transforma um ou mais dados de entrada em um ou mais dados de saída.
Está(ão) correta(s)
I. As tabelas de dispersão permitem a busca por uma chave de forma eficiente, no entanto elas não são usadas na prática, pois consomem muita memória.
II. As árvores binárias balanceadas de busca mantêm uma coleção de itens de forma ordenada e permitem a busca, a inserção e a remoção de itens de forma eficiente.
III. A busca linear, apesar de não ser eficiente, pode ser a única opção, por exemplo, para listas encadeadas.
IV. A busca binária permite buscar por valores em arranjos de forma eficiente, mas requer que os valores estejam ordenados.
Estão corretas
I. Um arranjo é caracterizado por alocação contígua e acesso indexado em tempo constante.
II. Uma lista com encadeamento simples permite a inserção e a remoção de itens em qualquer posição de forma eficiente.
III. As formas mais comuns para tratamento de colisões em tabelas de dispersão são o encadeamento separado e o endereçamento aberto.
IV. Os arranjos e as listas encadeadas são exemplos de estruturas de dados lineares, em que cada elemento tem, no máximo, um predecessor e um sucessor.
Estão corretas
Considere o seguinte algoritmo, em que a e b são arranjos com n elementos indexados a partir de 1:
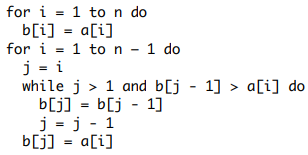
Se n = 5 e a = [3, 1, 8, 4, 7], então, após a execução do algoritmo, o arranjo b será