Questões de Concurso Sobre algoritmos e estrutura de dados
Foram encontradas 3.780 questões
( ) A notação empregada para representar o melhor caso de um determinado algoritmo é Ω (Omega).
( ) A notação empregada para representar o pior caso em casos gerais de um determinado algoritmo é Θ (Theta).
( ) O(1) – tempo de execução constante, que não varia conforme o tamanho da entrada do algoritmo.
( ) Quanto à complexidade de tempo, O(n) – tempo quadrático, cresce proporcionalmente ao tamanho da entrada.
O texto seguinte servirá de base para responder à questão.
Analise o seguinte algoritmo.
inicio
inteiro num
escreva ("Digite um número:")
leia (num) inteiro cont = 0
inteiro ant = 1
inteiro atual = 1
enquanto (cont < num)
{
inteiro prox = ant + atual
ant = atual
atual = prox cont =
cont + 1
}
fim
Fonte: Menendez, 2023
Supondo que você digitou 1 e o algoritmo iniciou, o valor de "cont", "prox" e "atual" quando o algoritmo terminar são, respectivamente:
A figura (a) mostra um trecho de algoritmo, cujo código emprega a estrutura de controle "enquanto ... fimenquanto", e em (b), outra mostra a série de números gerada como resultado da execução.

Para gerar o mesmo resultado, pode-se utilizar um código que usa a estrutura de controle "para ... fimpara", em substituição à "enquanto ... fimenquanto", mostrada em (a) acima.
O código com a estrutura de controle "para ... fimpara", está indicada na seguinte opção:
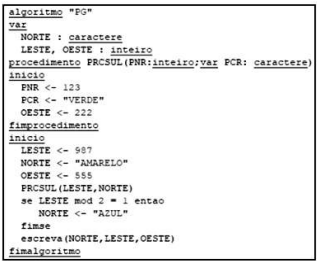
Após a execução desse algoritmo, os valores finais das variáveis NORTE, LESTE e OESTE são, respectivamente:

Após a execução, serão mostrados para as variáveis CT, NR e BL, respectivamente, os seguintes valores
Analise o seguinte algoritmo escrito em pseudocódigo no formato do VisuAlg:

Assinale a alternativa que corresponde ao valor da variável C exibido na tela ao final da execução desse algoritmo.

Na execução, dois outros códigos equivalentes, que geram a mesma sequência de números como saída, mas que utilizam as estruturas de controle enquanto... fimenquanto e repita... ate... fimrepita, estão indicados na seguinte opção:
O trecho de pseudocódigo abaixo foi utilizado por um profissional para testar o comportamento de estruturas de repetição:

Após três iterações completas, qual será o valor exibido?
I. As pilhas (stacks) operam segundo o princípio LIFO, permitindo inserções e remoções no topo com excelente desempenho, sendo úteis em chamadas de função.
II. Árvores binárias de busca garantem tempo constante O(1) para inserção e busca em qualquer cenário, independentemente da ordem de inserção dos dados.
III. Filas (queues) seguem o princípio FIFO, sendo amplamente utilizadas em sistemas de agendamento, buffers e comunicação assíncrona.
A sequência correta é:
Qual das habilidades a seguir integra o raciocínio computacional?
Qual elemento é essencial na construção de um algoritmo eficiente?
Sobre técnicas de indexação utilizando hashing, assinale a opção correta.