Questões de Concurso
Sobre estrutura de dados em algoritmos e estrutura de dados
Foram encontradas 1.657 questões
Julgue o próximo item, a respeito de computação e estrutura de dados.
Se os elementos A, B, C e D forem inseridos em uma pilha, nessa ordem, eles serão excluídos na ordem A, B, C e D, um elemento de cada vez.
I. As tabelas de dispersão permitem a busca por uma chave de forma eficiente, no entanto elas não são usadas na prática, pois consomem muita memória.
II. As árvores binárias balanceadas de busca mantêm uma coleção de itens de forma ordenada e permitem a busca, a inserção e a remoção de itens de forma eficiente.
III. A busca linear, apesar de não ser eficiente, pode ser a única opção, por exemplo, para listas encadeadas.
IV. A busca binária permite buscar por valores em arranjos de forma eficiente, mas requer que os valores estejam ordenados.
Estão corretas
I. Um arranjo é caracterizado por alocação contígua e acesso indexado em tempo constante.
II. Uma lista com encadeamento simples permite a inserção e a remoção de itens em qualquer posição de forma eficiente.
III. As formas mais comuns para tratamento de colisões em tabelas de dispersão são o encadeamento separado e o endereçamento aberto.
IV. Os arranjos e as listas encadeadas são exemplos de estruturas de dados lineares, em que cada elemento tem, no máximo, um predecessor e um sucessor.
Estão corretas
Analise a seguinte figura com a representação de uma árvore:
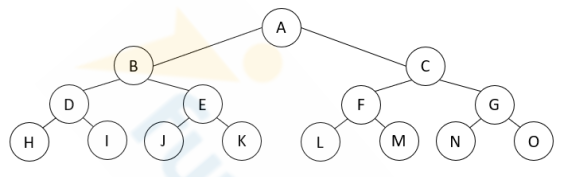
Ao fazer o caminhamento pós-ordem, a ordem dos elementos exibidos será:

Com base nesse algoritmo, desenvolvido em pseudocódigo, assinale a opção que apresenta corretamente o resultado de “escreva(vetor)”.
Uma ___________ é uma estrutura de dados que segue o princípio LIFO (Last In, First Out). Os elementos são inseridos no topo (push) e removidos do topo (pop). Um(a) ___________ é uma coleção de vértices (ou nós) e arestas que conectam esses vértices. Pode ser dirigido(a) (as arestas têm uma direção) ou não dirigido(a).
( ) Lista é uma estrutura na qual as operações “inserir”, “retirar” e “localizar” são definidas. São estruturas muito flexíveis porque podem crescer ou diminuir de tamanho durante a execução de um programa, de acordo com a demanda.
( ) Listas são adequadas para aplicações em que não é possível prever a demanda por memória, permitindo a manipulação de quantidades imprevisíveis de dados, de formato também imprevisível.
( ) Uma pilha é uma lista linear em que todas as inserções, retiradas e geralmente todos os acessos são feitos em apenas um extremo da lista.
( ) Uma fila é uma lista linear em que todas as inserções são realizadas em um extremo da lista, e todas as retiradas e geralmente os acessos são realizados no outro extremo da lista.
Para gerenciar a ordem de execução de chamadas de função em um programa recursivo, a estrutura de dados mais adequada é a pilha (stack), pois sua característica LIFO (last-in, first-out) espelha o fluxo de execução em que a última função chamada é a primeira a finalizar sua execução e retornar.
class No: def __init__(self, dado): self.dado = dado self.proximo = None
Considere ainda o trecho de código em Python que manipula a Lista Simplesmente Encadeada e que está declarado dentro da classe ListaEncadeada:

A classe ListaEncadeada contém outros métodos que permitem a sua completa manipulação, como inserir elemento no início, inserir elemento no final, exibir conteúdo da lista e remover elementos. Assinale a alternativa que apresenta o conteúdo retornado pelo metodoZ, quando for enviado como parâmetro a seguinte Lista Ligada: [15, 28, 2, 10, 50, 14, 77]
Considere o seguinte trecho de pseudocódigo, que utiliza uma pilha:
inicialize pilha vazia
para i de 1 até 4:
empilhar(i)
enquanto pilha não estiver vazia:
x < desempilhar ()
imprimir (x)
A esse respeito, qual será a saída do programa, considerando-se o comportamento padrão de uma pilha?
Considere que os códigos apresentados a seguir estão implementados na linguagem de programação Java. Além disso, considere o construtor da classe Node, representando o nó, e o trecho inicial da classe Lista, conforme descritos nas figuras 1 e 2, respectivamente.

Diante do exposto, marque a opção que contém, na linguagem Java, o método para adicionar um novo nó (Node) ao final da Lista (método da classe Lista).