Questões de Concurso Sobre estatística
Foram encontradas 14.322 questões
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382972
Estatística
Considere o texto sobre economias de aglomeração no
Brasil.
Quanto maior a escala da urbanização, maiores tendem a ser os ganhos de produtividade das firmas. Do mesmo modo, a maior diversidade de bens e serviços ofertados, de interações sociais e econômicas e de serviços públicos disponíveis para consumo da coletividade torna-se um diferencial de grande significado para a localização empresarial. Para o Brasil, no processo de desconcentração produtiva, mostrou-se que a localização de firmas industriais adquiriu um comportamento fortemente associado a economias de aglomeração dadas pelo estoque de infraestrutura e mão de obra qualificada: o tecido industrial tornou-se concentrado — e desconcentrou concentradamente — em uma grande porção do território entre o Sul e o Sudeste. Consideradas, de um lado, as motivações e lógicas do setor privado e os estímulos do mercado mundial e do território inercial do desenvolvimento brasileiro e, de outro lado, as motivações e os esforços governamentais, em sentido amplo, para atuação sobre novas geografias econômicas nacionais, identificam-se cinco tipos preferenciais de territórios predominantemente impactados e redefinidos pela potência das forças em atuação.
MONTEIRO NETO, A.; SILVA, R.; SEVERIAN, D. O território das atividades industriais no Brasil: a força das economias de aglomeração e urbanização. In: MONTEIRO NETO, A. (org.). Brasil, Brasis: reconfigurações territoriais da indústria no século XXI. Brasília, DF: Ipea, 2021, p. 256-258. Adaptado.
Na tipologia mencionada acima, encontram-se rearranjos territoriais que se prestam à análise das formas de aglomeração e os que concorrem para a desaglomeração.
Considerando-se especificamente os vetores que levam à concentração produtiva, identificam-se territórios predominantemente impactados e (re)definidos por
Quanto maior a escala da urbanização, maiores tendem a ser os ganhos de produtividade das firmas. Do mesmo modo, a maior diversidade de bens e serviços ofertados, de interações sociais e econômicas e de serviços públicos disponíveis para consumo da coletividade torna-se um diferencial de grande significado para a localização empresarial. Para o Brasil, no processo de desconcentração produtiva, mostrou-se que a localização de firmas industriais adquiriu um comportamento fortemente associado a economias de aglomeração dadas pelo estoque de infraestrutura e mão de obra qualificada: o tecido industrial tornou-se concentrado — e desconcentrou concentradamente — em uma grande porção do território entre o Sul e o Sudeste. Consideradas, de um lado, as motivações e lógicas do setor privado e os estímulos do mercado mundial e do território inercial do desenvolvimento brasileiro e, de outro lado, as motivações e os esforços governamentais, em sentido amplo, para atuação sobre novas geografias econômicas nacionais, identificam-se cinco tipos preferenciais de territórios predominantemente impactados e redefinidos pela potência das forças em atuação.
MONTEIRO NETO, A.; SILVA, R.; SEVERIAN, D. O território das atividades industriais no Brasil: a força das economias de aglomeração e urbanização. In: MONTEIRO NETO, A. (org.). Brasil, Brasis: reconfigurações territoriais da indústria no século XXI. Brasília, DF: Ipea, 2021, p. 256-258. Adaptado.
Na tipologia mencionada acima, encontram-se rearranjos territoriais que se prestam à análise das formas de aglomeração e os que concorrem para a desaglomeração.
Considerando-se especificamente os vetores que levam à concentração produtiva, identificam-se territórios predominantemente impactados e (re)definidos por
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382935
Estatística
Em estudos sobre os diferenciais de salários entre homens e mulheres, há uma preocupação em entender o efeito do
tempo dedicado aos afazeres domésticos (Td). Sabe-se que as mulheres dedicam a maior parte da sua jornada para essas
atividades, dedicação maior do que a dos homens, e isso impacta no esforço dedicado ao trabalho.
Uma forma de calcular esse efeito é usar um banco de dados dos trabalhadores em painel balanceado e especificar a seguinte equação a ser estimada para homens e mulheres, separadamente:
In Wit = Xitβ + Tditδ + εit
Nessa equação, In Wit é o logaritmo neperiano do salário-hora do trabalhador i no tempo t, Xit é uma matriz de variáveis explicativas observadas determinantes do salário, Td é o tempo dedicado aos afazeres domésticos. β é o vetor de parâmetros associados a X e d o parâmetro associado a Td, ambos a serem estimados pelo modelo. εit é o termo de erro aleatório não observado.
Existem várias formas de estimar esse efeito, e, sobre elas, conclui-se o seguinte:
Uma forma de calcular esse efeito é usar um banco de dados dos trabalhadores em painel balanceado e especificar a seguinte equação a ser estimada para homens e mulheres, separadamente:
In Wit = Xitβ + Tditδ + εit
Nessa equação, In Wit é o logaritmo neperiano do salário-hora do trabalhador i no tempo t, Xit é uma matriz de variáveis explicativas observadas determinantes do salário, Td é o tempo dedicado aos afazeres domésticos. β é o vetor de parâmetros associados a X e d o parâmetro associado a Td, ambos a serem estimados pelo modelo. εit é o termo de erro aleatório não observado.
Existem várias formas de estimar esse efeito, e, sobre elas, conclui-se o seguinte:
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382934
Estatística
Para fenômenos cujo resultado é um indicativo da ocorrência ou não de um fato ou escolha, utiliza-se a modelagem de
variáveis discretas. Um exemplo é o estudo da participação ou não da mulher no mercado de trabalho. A variável dependente a ser modelada é derivada de um processo de escolha, realizada com base na comparação das opções disponíveis,
em que o indivíduo escolhe a opção com maior utilidade/benefício. O modelo é construído a partir de uma variável auxiliar
chamada latente y*. A variável y* não é observada e reflete esta utilidade/benefício, definindo o processo de escolha. Se
temos uma escolha y binária
y = 1 se y* > 0
y = 0 se y* ≤ 0,
a variável latente é escrita como:
y* = x*β + ε,
onde x e β são vetores de variáveis explicativas e de parâmetros, respectivamente, e ε é o termo de erro não observado.
Dessa forma, conclui-se que
y = 1 se y* > 0
y = 0 se y* ≤ 0,
a variável latente é escrita como:
y* = x*β + ε,
onde x e β são vetores de variáveis explicativas e de parâmetros, respectivamente, e ε é o termo de erro não observado.
Dessa forma, conclui-se que
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382932
Estatística
Uma forma de analisar os gastos domiciliares em saúde
e suas relações com o envelhecimento da população é
estimar um modelo Tobit, considerando variáveis explicativas, tais como a idade e o sexo da pessoa de referência
da família, o tamanho da família, a presença de idosos no
domicílio, dentre outras.
Nesse caso, a justificativa para o uso do modelo Tobit decorreria do fato de ele
Nesse caso, a justificativa para o uso do modelo Tobit decorreria do fato de ele
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382931
Estatística
Um cientista mediu uma grandeza y para tempos t = 0,1,2,3,
obtendo os seguintes valores:
y(0) ≅ 1,2, y(1) ≅ 1,4, y(2) ≅ 1,8, y(3) ≅ 2,0.
Usando mínimos quadrados, o cientista obtém a função afim y = at+b que melhor aproxima suas medidas.
Usando essa função, que valor de y ele prevê para t=4?
y(0) ≅ 1,2, y(1) ≅ 1,4, y(2) ≅ 1,8, y(3) ≅ 2,0.
Usando mínimos quadrados, o cientista obtém a função afim y = at+b que melhor aproxima suas medidas.
Usando essa função, que valor de y ele prevê para t=4?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382930
Estatística
Um biólogo estuda a distribuição de animais de uma determinada espécie. Ele verifica que, se divide a região
estudada em quadrados disjuntos de 100 m de lado, o
número de animais por quadrado é descrito por uma variável aleatória X. Assim, dado um quadrado na região e
um inteiro não negativo n, a probabilidade de que haja
exatamente n animais da espécie estudada no quadrado
é dada pela fórmula Prob(X = n) = n/2(n+1).
Quanto vale o valor esperado E(X), ou seja, qual é o número médio de animais da espécie estudada por quadrado de lado 100m?
Quanto vale o valor esperado E(X), ou seja, qual é o número médio de animais da espécie estudada por quadrado de lado 100m?
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382929
Estatística
Um economista analisou duas séries mensais que tratavam, respectivamente, do preço do combustível de aviação (yt) e do número de passageiros do transporte aéreo
(xt), no período de 1980 a 2019, estabelecendo o seguinte
modelo de regressão:
yt = β0 + β1 xt + et ,
em que et é o erro. No entanto, observou-se que as variáveis yt e xt não eram estacionárias e não eram cointegradas.
A estratégia a ser empregada para se tentar resolver esse problema é
yt = β0 + β1 xt + et ,
em que et é o erro. No entanto, observou-se que as variáveis yt e xt não eram estacionárias e não eram cointegradas.
A estratégia a ser empregada para se tentar resolver esse problema é
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382928
Estatística
Um analista de planejamento está estudando a evolução
dos preços de vendas de imóveis. Dessa forma, ajustou
aos dados um modelo de séries temporais de modo a prever os preços de venda para os próximos anos. Nesse
modelo, observou-se que sua Função de Autocorrelação
tinha valores significativos até a segunda defasagem e
que a Função de Autocorrelação Parcial tinha um decaimento exponencial.
Com base nessas informações, identifica-se que o modelo ajustado pelo analista foi o de
Com base nessas informações, identifica-se que o modelo ajustado pelo analista foi o de
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382927
Estatística
Um analista de planejamento utilizou um modelo
ARMA(1,1) para estimar a safra de grãos (w) anual para
determinada cidade no interior do Mato Grosso do Sul.
O modelo usado é escrito da seguinte forma:
wt = awt-1 + βet-1 + et ,
em que et é um ruído branco com média zero e variância σ2.
Desse modo, esse modelo é estacionário de segunda ordem se, e somente se,
wt = awt-1 + βet-1 + et ,
em que et é um ruído branco com média zero e variância σ2.
Desse modo, esse modelo é estacionário de segunda ordem se, e somente se,
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382926
Estatística
O site do Ipeadata traz dados sobre a evolução da estimativa mensal do PIB do Brasil realizada pelo Bacen. A Figura a
seguir mostra um extrato dessa série.
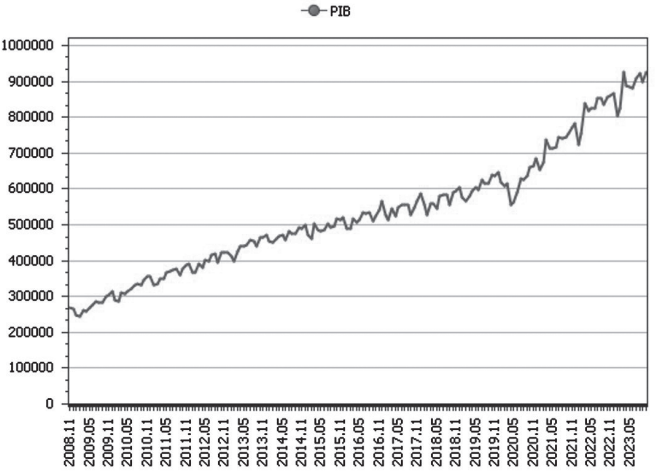
Disponível em: http://www.ipeadata.gov.br/ExibeSerie.aspx?serid=521274780&module=M. Acesso em: 17 dez. 2023. Adaptado.
Um pesquisador deseja modelar essa série, a partir de um modelo ARMA(p,q).
Esse modelo
Disponível em: http://www.ipeadata.gov.br/ExibeSerie.aspx?serid=521274780&module=M. Acesso em: 17 dez. 2023. Adaptado.
Um pesquisador deseja modelar essa série, a partir de um modelo ARMA(p,q).
Esse modelo
Ano: 2024
Banca:
CESGRANRIO
Órgão:
IPEA
Prova:
CESGRANRIO - 2024 - IPEA - Técnico de Planejamento e Pesquisa - Políticas Públicas e Desenvolvimento |
Q2382908
Estatística
Classicamente é possível, de forma geral, definir os tipos de pesquisa científica, considerando três categorias.
Associe as categorias às suas características específicas apresentadas a seguir.
I - Pesquisa descritiva
II - Pesquisa de associação sem interferência entre as variáveis
III - Pesquisa de associação com interferência entre as variáveis
P - Testa hipótese de descrição
Q - Testa hipótese de associação
R - Testa hipótese de causa e efeito
S - Não apresenta hipótese
A associação correta é:
I - Pesquisa descritiva
II - Pesquisa de associação sem interferência entre as variáveis
III - Pesquisa de associação com interferência entre as variáveis
P - Testa hipótese de descrição
Q - Testa hipótese de associação
R - Testa hipótese de causa e efeito
S - Não apresenta hipótese
A associação correta é:
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382836
Estatística
No campo da estatística descritiva, as medidas que quantificam a dispersão dos dados são
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382835
Estatística
Acerca de medidas de posição e de dispersão, no âmbito da estatística descritiva, julgue os itens seguintes.
I A média é a medida de tendência central mais representativa para qualquer conjunto de dados, enquanto a mediana e a moda raramente fornecem informações úteis.
II A mediana, a média e a moda são medidas intercambiáveis e produzem o mesmo valor em qualquer conjunto de dados, independentemente de sua distribuição ou de suas características.
III Para um conjunto de dados numéricos com uma quantidade ímpar de elementos, a média determina o valor que divide o conjunto em duas partes iguais e a moda identifica o valor médio dos dados.
IV Para um conjunto de dados numéricos com uma quantidade ímpar de elementos, a mediana corresponde ao valor central que divide o conjunto em duas partes com a mesma quantidade de elementos, e a moda identifica o valor mais frequente.
Assinale a opção correta.
I A média é a medida de tendência central mais representativa para qualquer conjunto de dados, enquanto a mediana e a moda raramente fornecem informações úteis.
II A mediana, a média e a moda são medidas intercambiáveis e produzem o mesmo valor em qualquer conjunto de dados, independentemente de sua distribuição ou de suas características.
III Para um conjunto de dados numéricos com uma quantidade ímpar de elementos, a média determina o valor que divide o conjunto em duas partes iguais e a moda identifica o valor médio dos dados.
IV Para um conjunto de dados numéricos com uma quantidade ímpar de elementos, a mediana corresponde ao valor central que divide o conjunto em duas partes com a mesma quantidade de elementos, e a moda identifica o valor mais frequente.
Assinale a opção correta.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382834
Estatística
Definida no âmbito da estatística descritiva, a moda é
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382833
Estatística
Com relação a medidas de posição e a medidas de dispersão, conceitos da estatística descritiva, assinale a opção correta.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382832
Estatística
Definida no âmbito da estatística descritiva, a mediana é
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Geógrafo |
Q2382831
Estatística
Com relação a estatística descritiva, a média aritmética é
I uma medida de tendência central que não é afetada por valores discrepantes nos dados, fato que a torna inutilizável em distribuições simétricas.
II a única medida de tendência central que sempre produz resultados inteiros, mesmo quando aplicada a variáveis discretas.
III calculada como sendo a soma de todos os valores integrantes de um conjunto de dados, dividida pela quantidade de elementos desse conjunto.
Assinale a opção correta.
I uma medida de tendência central que não é afetada por valores discrepantes nos dados, fato que a torna inutilizável em distribuições simétricas.
II a única medida de tendência central que sempre produz resultados inteiros, mesmo quando aplicada a variáveis discretas.
III calculada como sendo a soma de todos os valores integrantes de um conjunto de dados, dividida pela quantidade de elementos desse conjunto.
Assinale a opção correta.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Engenheiro Eletrônico |
Q2381475
Estatística
Suponha que a resistência, em MPa, de certo tipo de material estrutural sob determinada condição de operação possa ser descrita por uma distribuição normal com média μ desconhecida e desvio padrão σ conhecido. Considere, também, que um estudo experimental tenha sido realizado para se estimar a média μ por meio de uma amostra aleatória simples de tamanho n = 9, obtendo-se a seguinte estimativa intervalar com 95% de confiança: 40 ± 0,5 MPa.
Com respeito a essa situação hipotética, assinale a opção correta.
Com respeito a essa situação hipotética, assinale a opção correta.
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Engenheiro Eletricista (Turno de Revezamento) |
Q2381426
Estatística
Considerando que a durabilidade D, em meses, de uma peça mecânica siga uma distribuição exponencial com média igual a 4 e que e-1 = 0,37, então a probabilidade P (D ≤ 4)será igual a
Ano: 2024
Banca:
CESPE / CEBRASPE
Órgão:
ITAIPU BINACIONAL
Prova:
CESPE / CEBRASPE - 2024 - ITAIPU BINACIONAL - Profissional de Nível Universitário Júnior - Função: Engenheiro Eletricista (Turno de Revezamento) |
Q2381425
Estatística
Considere que o número diário de falhas apresentadas por certo sistema mecânico seja descrito por uma variável aleatória X que segue uma distribuição de Poisson. Nessa situação, se P(X = 0) = P (X = 1) > 0 então o desvio padrão de X será igual a