Questões de Concurso
Para estatística
Foram encontradas 14.154 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
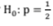 contra
contra 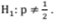
A probabilidade do erro tipo I I se
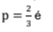
Dado: Utilize Z0.90 = 1,64
Apresenta os conceitos corretos sobre as medidas de risco em finanças conhecidas como Desvio-padrão e Coeficiente de Variação a afirmação de que(,)
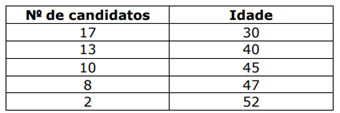
Considerando as informações apresentadas, é correto afirmar que a idade média dos candidatos desse concurso é de:
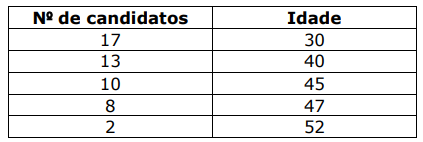
Considerando as informações apresentadas, é correto afirmar que a idade média dos candidatos desse concurso é de:
Relacione abaixo os Conceitos (Coluna 1) com suas respectivas Definições (Coluna 2).
Coluna 1 Conceitos
1. Regressão simples 2. Série temporal 3. Estatística descritiva
Coluna 2 Definições
( ) Resumo de medidas de centralidade e dispersão. ( ) Modelagem da relação entre duas variáveis. ( ) Análise de padrões ao longo do tempo.
Assinale a alternativa que indica a sequência correta, de cima para baixo.
1. A presença de heterocedasticidade torna os estimadores obtidos pelo método dos mínimos quadrados ordinários viesados e inconsistentes.
2. Na presença de heterocedasticidade, os estimadores obtidos pelo método dos mínimos quadrados ordinários permanecem não viesados, porém deixam de ser eficientes.
3. A heterocedasticidade compromete a validade dos testes estatísticos usuais, caso não sejam utilizados erros-padrão robustos.
Assinale a alternativa que indica todas as afirmativas corretas.
(__)A probabilidade de o pesquisador escolhido dominar também programação é igual a 50%.
(__)O cálculo correto envolve a probabilidade condicional, obtida pela razão entre 3 e 6.
(__)A probabilidade pedida é de 40%, pois há 4 pesquisadores que dominam programação.
(__)O total de pesquisadores que dominam estatística considerado no cálculo é igual a 10.
A sequência CORRETA, de cima para baixo, é:
Considere um grupo formado por 10 pesquisadores, dos quais 6 dominam estatística e 4 dominam programação. Sabe-se ainda que 3 pesquisadores dominam simultaneamente estatística e programação. Um pesquisador é escolhido ao acaso entre aqueles que dominam estatística. Analise as assertivas e classifique como verdadeira (V) ou falsa (F).
(__) A probabilidade de o pesquisador escolhido dominar também programação é igual a 50%.
(__) O cálculo correto envolve a probabilidade condicional, obtida pela razão entre 3 e 6.
(__) A probabilidade pedida é de 40%, pois há 4 pesquisadores que dominam programação.
(__) O total de pesquisadores que dominam estatística considerado no cálculo é igual a 10.
A sequência CORRETA, de cima para baixo, é:
(__)A probabilidade de o pesquisador escolhido dominar também programação é igual a 50%.
(__)O cálculo correto envolve a probabilidade condicional, obtida pela razão entre 3 e 6.
(__)A probabilidade pedida é de 40%, pois há 4 pesquisadores que dominam programação.
(__)O total de pesquisadores que dominam estatística considerado no cálculo é igual a 10.
A sequência CORRETA, de cima para baixo, é:
(__)A probabilidade de o pesquisador escolhido dominar também programação é igual a 50%.
(__)O cálculo correto envolve a probabilidade condicional, obtida pela razão entre 3 e 6.
(__)A probabilidade pedida é de 40%, pois há 4 pesquisadores que dominam programação.
(__)O total de pesquisadores que dominam estatística considerado no cálculo é igual a 10.
A sequência CORRETA, de cima para baixo, é: