Questões de Concurso
Para analista judiciário - estatística
Foram encontradas 4.080 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349765
Estatística
Em relação à característica de estacionariedade de uma série
temporal, avalie as afirmativas a seguir.
I. Uma série temporal é estacionária quando suas características estatísticas (média, variância, autocorrelação) são constantes ao longo do tempo.
II. Uma série é estacionária quando se desenvolve aleatoriamente no tempo em torno de uma média constante, refletindo algum equilíbrio estatístico, de modo que as leis de probabilidade que atuam no processo não mudam com o tempo.
III. Métodos de previsão usam transformações matemáticas para estacionarizar uma série; a seguir, são feitas previsões nessa série estável para, posteriormente, se inverter as transformações e obter as previsões para a série original.
Estão corretas as afirmativas
I. Uma série temporal é estacionária quando suas características estatísticas (média, variância, autocorrelação) são constantes ao longo do tempo.
II. Uma série é estacionária quando se desenvolve aleatoriamente no tempo em torno de uma média constante, refletindo algum equilíbrio estatístico, de modo que as leis de probabilidade que atuam no processo não mudam com o tempo.
III. Métodos de previsão usam transformações matemáticas para estacionarizar uma série; a seguir, são feitas previsões nessa série estável para, posteriormente, se inverter as transformações e obter as previsões para a série original.
Estão corretas as afirmativas
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349764
Estatística
Se X tem distribuição normal p-variada com vetor de médias μ e matriz de covariâncias Σ então Z = DX, em que D é uma matriz q xp de posto q ≤ p tem distribuição normal com vetor de médias_____ e matriz de covariâncias _____.
Se D’ é a transposta de D, as lacunas ficam corretamentepreenchidas respectivamente por
Se D’ é a transposta de D, as lacunas ficam corretamentepreenchidas respectivamente por
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349763
Estatística
Uma amostra aleatória simples de tamanho n será observada para
fazermos inferências acerca de uma proporção de “sucessos”
populacional p. Não temos informações prévias acerca do valor de
p, de modo que teremos de trabalhar no pior caso.
O tamanho da amostra necessário para que possamos garantir, com 95% de confiança, que o valor da proporção de “sucessos” na amostra não diferirá da proporção de “sucessos” populacional por mais de 5% é, no mínimo, aproximadamente igual a
O tamanho da amostra necessário para que possamos garantir, com 95% de confiança, que o valor da proporção de “sucessos” na amostra não diferirá da proporção de “sucessos” populacional por mais de 5% é, no mínimo, aproximadamente igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349762
Estatística
Suponha que uma amostra aleatória X1, X2, ..., X10, de tamanho n =10 será obtida de uma distribuição Bernoulli (θ), θ desconhecido.
Pretende-se usar uma densidade a priori Beta com parâmetros α = 2 e β = 2 e que será usada uma função de perda quadrática L(θ, a) = (θ – a)2, com 0 < θ < 1 e 0 < a < 1.
Nesse caso, se forem observados 5 “sucessos”, a estimativa de Bayes para θ será igual a
Pretende-se usar uma densidade a priori Beta com parâmetros α = 2 e β = 2 e que será usada uma função de perda quadrática L(θ, a) = (θ – a)2, com 0 < θ < 1 e 0 < a < 1.
Nesse caso, se forem observados 5 “sucessos”, a estimativa de Bayes para θ será igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349761
Estatística
Suponha um modelo de regressão linear p-variado dado por:
Y = Xβ + ε
em que Y é um vetor (n x 1), X é uma matriz (n x p) conhecida, β é um vetor de parâmetros (p x 1) e ε é um vetor de erros tal que E[ ε ] = 0, V[ε ] = Iσ2, de modo que os elementos de ε são não correlacionados, I é a matriz identidade.
Nesse caso, se X’ é a matriz transposta da matriz X, a solução das equações normais é dada por
Y = Xβ + ε
em que Y é um vetor (n x 1), X é uma matriz (n x p) conhecida, β é um vetor de parâmetros (p x 1) e ε é um vetor de erros tal que E[ ε ] = 0, V[ε ] = Iσ2, de modo que os elementos de ε são não correlacionados, I é a matriz identidade.
Nesse caso, se X’ é a matriz transposta da matriz X, a solução das equações normais é dada por
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349760
Estatística
Uma aproximação para os possíveis valores assumidos por uma
variável aleatória uniforme no intervalo (0,1) pode ser obtida
usando-se o método congruencial multiplicativo (MCM).
Avalie se o MCM apresenta as seguintes características:
I. É um método simples e de uso extensivo.
II. O MCM gera uma sequência de números pseudoaleatórios.
III. O MCM parte de um valor inicial x0 e calcula recursivamente os valores sucessivos xn, n ≥ 1.
Está correto o que se afirma em
Avalie se o MCM apresenta as seguintes características:
I. É um método simples e de uso extensivo.
II. O MCM gera uma sequência de números pseudoaleatórios.
III. O MCM parte de um valor inicial x0 e calcula recursivamente os valores sucessivos xn, n ≥ 1.
Está correto o que se afirma em
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349759
Estatística
Considere que no ajuste de uma reta de regressão linear
Y = β0 + β1X + ε,
a seguinte tabela de Análise da Variância (com dados parcialmente omitidos) foi obtida:
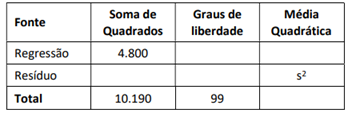
O valor de s2 é igual a
Y = β0 + β1X + ε,
a seguinte tabela de Análise da Variância (com dados parcialmente omitidos) foi obtida:
O valor de s2 é igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349758
Estatística
A tabela a seguir mostra os dados de temperatura de 10 indivíduos
obtidos antes e depois da aplicação de um determinado
tratamento. O problema é testar a hipótese de que não há efeito
de tratamento na mediana das temperaturas.
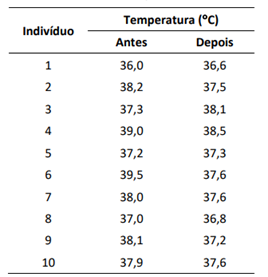
Um valor da estatística de teste de Wilcoxon para esses dados é igual a
Um valor da estatística de teste de Wilcoxon para esses dados é igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349757
Estatística
Se uma densidade pertence à família exponencial, então ela podeser escrita como
f(x) = a(θ)b(x) exp{c(θ)d(x)}, sendo a, b, c e d funções.
Lembremos que se uma amostra aleatória X1, X2, ..., Xn é obtida de uma densidade que pertence à família exponencial, então, pelo critério de fatorização, uma estatística suficiente é dada por
f(x) = a(θ)b(x) exp{c(θ)d(x)}, sendo a, b, c e d funções.
Lembremos que se uma amostra aleatória X1, X2, ..., Xn é obtida de uma densidade que pertence à família exponencial, então, pelo critério de fatorização, uma estatística suficiente é dada por
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349756
Estatística
Para testar a hipótese nula de independência entre dois atributos
A e B a seguinte tabela de contingências 2x2 foi obtida:
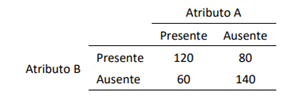
O valor da estatística qui-quadrado usual para esses dados é aproximadamente igual a
O valor da estatística qui-quadrado usual para esses dados é aproximadamente igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349755
Estatística
Para testar H0: p = 0,5 versus H1: p = 0,8, em que p é o parâmetro
de uma densidade Bernoulli (p), uma amostra X1, X2, X3, X4, de
tamanho 4, será obtida e será usado o critério de decisão que
rejeitará H0 se X1 + X2 + X3 + X4 ≥ 3.
Nesse caso, a soma das probabilidades de erro tipo I e tipo II desse critério é aproximadamente igual a
Nesse caso, a soma das probabilidades de erro tipo I e tipo II desse critério é aproximadamente igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349754
Estatística
Deseja-se testar H0: μ ≥ 50 versus H1: μ < 50 em que μ é a média populacional de uma variável aleatória contínua suposta normalmente distribuída com variância conhecida σ2 = 100.
Se uma amostra aleatória simples de tamanho n = 36 for obtida, e se x̄ é o valor observado da média amostral, então o critério uniformemente mais poderoso de tamanho α = 5% rejeitará H0 se
Se uma amostra aleatória simples de tamanho n = 36 for obtida, e se x̄ é o valor observado da média amostral, então o critério uniformemente mais poderoso de tamanho α = 5% rejeitará H0 se
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349753
Estatística
Se uma amostra aleatória simples X1, X2, ..., Xn, de tamanho n, for obtida de uma densidade exponencial com parâmetro θ, e se é a média amostral, então 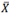 tem distribuição
tem distribuição
tem distribuição
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349752
Estatística
Considere uma amostra aleatória simples X1, X2, ..., Xn, de tamanho n, e as seguintes afirmativas acerca da estimação por máxima verossimilhança.
I. Se a variável aleatória populacional tem distribuição Bernoulli parâmetro p, o estimador de máxima verossimilhança de p é a média amostral.
II. Se a variável aleatória populacional tem distribuição exponencial parâmetro λ, o estimador de máxima verossimilhança de λ é a média amostral.
III. Se a variável aleatória populacional tem distribuição Poissonparâmetro λ, o estimador de máxima verossimilhança de λ é a média amostral.
Está correto o que se afirma em
I. Se a variável aleatória populacional tem distribuição Bernoulli parâmetro p, o estimador de máxima verossimilhança de p é a média amostral.
II. Se a variável aleatória populacional tem distribuição exponencial parâmetro λ, o estimador de máxima verossimilhança de λ é a média amostral.
III. Se a variável aleatória populacional tem distribuição Poissonparâmetro λ, o estimador de máxima verossimilhança de λ é a média amostral.
Está correto o que se afirma em
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349751
Estatística
Uma amostra aleatória simples de tamanho 25 de uma densidade normalmente distribuída com média μ e variância δ2 desconhecidas foi obtida e mostrou os seguintes resultados:
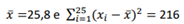
Um intervalo de 99% de confiança para μ será então dadoaproximadamente por
Um intervalo de 99% de confiança para μ será então dadoaproximadamente por
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349750
Estatística
Se X1, X2, ..., Xn é uma amostra aleatória simples de tamanho n de uma função de densidade de probabilidade f com função de distribuição acumulada F e se Y1 ≤ Y2 ≤ ... ≤ Yn são as estatísticas de ordem correspondentes, então a função de densidade de probabilidade da α-ésima estatística de ordem será dada por
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349749
Estatística
Suponha que uma amostra aleatória simples X1, X2, X3, X4 seráobtida de uma variável aleatória populacional com média μ.
Considere os seguintes possíveis estimadores de μ:
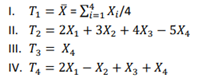
São estimadores não tendenciosos de μ:
Considere os seguintes possíveis estimadores de μ:
São estimadores não tendenciosos de μ:
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349748
Estatística
Uma variável aleatória X tem função geradora de momentos dada por mX(t, θ) = θ/ (θ - t), t < θ.
Nesse caso, X tem distribuição
Nesse caso, X tem distribuição
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349747
Estatística
Em uma população, 10% das pessoas têm problemas auditivos.
Se 144 pessoas dessa população forem aleatoriamente sorteadas para compor uma amostra aleatória simples, então a probabilidade de que ao menos 20 tenham problemas auditivos é aproximadamente igual a
Se 144 pessoas dessa população forem aleatoriamente sorteadas para compor uma amostra aleatória simples, então a probabilidade de que ao menos 20 tenham problemas auditivos é aproximadamente igual a
Ano: 2025
Banca:
FGV
Órgão:
TRT - 24ª REGIÃO (MS)
Prova:
FGV - 2025 - TRT - 24ª REGIÃO (MS) - Analista Judiciário - Área Apoio Especializado - Estatística (Reaplicação) |
Q3349746
Estatística
Suponha que os diâmetros com que determinadas esferas sejam
produzidas num processo industrial sejam normalmente
distribuídas com média de 10 mm e desvio padrão de 0,2 mm.
Nesse caso, a probabilidade de que uma esfera tenha diâmetro menor do que 10,3 mm é aproximadamente igual a
Nesse caso, a probabilidade de que uma esfera tenha diâmetro menor do que 10,3 mm é aproximadamente igual a