Questões de Concurso
Para sebrae-nacional
Foram encontradas 944 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Assinale a opção em que é apresentado o código escrito em
Python ou em R que, se executado, gerará um scatter plot para a
visualização da relação entre quantidade de vendas e receita
gerada por determinado produto, destacando a tendência linear
entre essas variáveis.
Um profissional de dados está analisando um conjunto de
dados com informações sobre as vendas de produtos em
diferentes regiões ao longo do tempo. Seu objetivo é visualizar a
tendência das vendas para cada região de forma clara e
comparativa. Para isso, ele decidiu utilizar o  em R.
em R.
Com base nessa situação hipotética, assinale a opção que
apresenta o código que, se executado, gerará um gráfico de linhas
que mostra a tendência de vendas ao longo do tempo para cada
região, utilizando cores diferentes para cada região.
Um analista foi encarregado de criar um dashboard que mostre a evolução das vendas trimestrais de uma empresa que utiliza tanto Power BI quanto Qlik Sense e armazena seus dados em um banco de dados SQL. O analista precisa extrair os dados trimestrais de 2023 e criar um dashboard interativo que permita aos usuários filtrar por categoria de produto e região.
Nessa situação hipotética, o referido analista deverá escrever
uma consulta SQL para extrair os dados trimestrais de 2023 e
criar um dashboard no
Um cientista de dados é responsável por criar dashboards interativos para uma empresa que pretende monitorar suas vendas e seu desempenho financeiro. A empresa utiliza tanto o Power BI quanto o Qlik Sense para diferentes departamentos. O cientista de dados precisa criar um dashboard que permita aos usuários filtrar dados por região, produto e período de tempo, além de incluir gráficos de linha, barras e mapas interativos.
Considerando a situação hipotética apresentada, assinale a opção correta em relação às capacidades do Power BI e do Qlik Sense para atender aos requisitos mencionados.
Um analista está criando um dashboard no Power BI para visualizar as vendas mensais de uma empresa e necessita criar uma medida que calcule a média móvel de 3 meses de vendas.
Nessa situação, a fórmula DAX mais adequada para a tarefa
mencionada é
Texto 14A3
Em certa base de dados de e-commerce, as tabelas 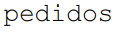 e
e 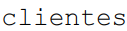 possuem as seguintes estruturas:
possuem as seguintes estruturas:

Assinale a opção em que é indicada a consulta SQL que, na base
de dados descrita no texto 14A3, retorna o nome dos clientes e o
valor total de seus pedidos, apenas para aqueles que tenham
realizado mais de 5 pedidos no ano de 2023.
Texto 14A3
Em certa base de dados de e-commerce, as tabelas e possuem as seguintes estruturas:
Um cientista de dados precisa analisar o comportamento de compra dos clientes na base de dados descrita no texto 14A3. O objetivo dessa análise é calcular o valor total gasto por cliente em pedidos feitos no mês anterior ao atual.
Com base nessa situação hipotética, assinale a opção em que
consta o comando que executará corretamente o cálculo
requerido.
Caso um cientista de dados precise extrair, transformar e
analisar grandes volumes de dados em um banco de dados
relacional, usando SQL, a prática mais recomendável para
garantir que as operações de análise sejam eficientes e precisas
consiste em
Assinale a opção correta a respeito da implantação de um modelo
de classificação de árvore de decisão em Python.

Assinale a opção que corresponde à correta execução do código
precedente, escrito em Python.

Considerando o código precedente, escrito em Python, assinale a
opção que corresponde à sua correta execução.
A respeito da linguagem R, é correto afirmar que
Em relação aos conceitos do algoritmo k-means, julgue os itens a seguir.
I É importante continuar as iterações do algoritmo k-means até que a mudança na posição dos centroides entre as iterações seja menor que um limite predefinido.
II No coeficiente de silhueta, quanto mais próximo o coeficiente estiver de 1, menor a distância entre os clusters; 0 indica que os dados podem estar no cluster errado; valores negativos sugerem que o ponto está na borda.
III Apesar de um maior número clusters sempre reduzir o SSE (sum of squared errors), isso não significa que mais clusters sempre sejam melhores, pois um número muito grande de clusters pode levar a overfitting do modelo.
Assinale a opção correta.
Em aprendizado de máquina, especialmente em algoritmos de árvores de decisão, é fundamental avaliar como os dados são organizados e classificados em diferentes níveis da árvore. Três conceitos-chave que auxiliam na construção e otimização dessas árvores são o gini impurity, a entropy e o information gain. A respeito desses conceitos, julgue os itens a seguir.
I Gini impurity mede a redução da entropy após a divisão de um conjunto de dados com base em um atributo.
II Entropy mede a quantidade de incerteza ou impureza no conjunto de dados.
III Information gain mede a probabilidade de uma nova instância ser classificada incorretamente, com base na distribuição de classes no conjunto de dados.
Assinale a opção correta.
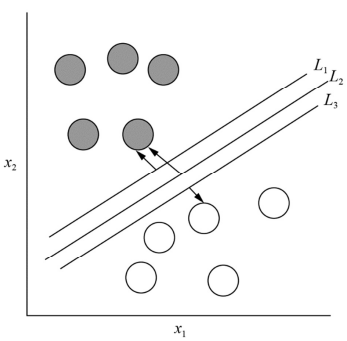
Considerando a figura precedente, assinale a opção correta em
relação ao algoritmo de SVM (support vector machine).
O seguinte código Python utiliza o algoritmo KNN
(k-nearest neighbors) para classificação, em que o parâmetro 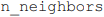 define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.
define o número de vizinhos que o classificador
KNN irá considerar para realizar a previsão.

Com base no código precedente, é correto afirmar que, caso o
valor de fosse alterado de 3 para 4, o modelo