Questões de Concurso
Comentadas para analista de banco de dados
Foram encontradas 1.633 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457913
Algoritmos e Estrutura de Dados
Uma das métricas mais comumente utilizadas para
comparar resultados de algoritmos de clusterização é
obtida por meio da fórmula (b-a)/ max(a,b), em que:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
a é a distância média entre os pontos dentro de cada cluster (distância média intra-cluster) e
b é a distância média para o cluster mais próximo (distância média para os pontos do cluster mais próximo).
A métrica descrita recebe o nome de:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457910
Algoritmos e Estrutura de Dados
Para classificar os processos tramitados no TJ-AC em
duas categorias (deferidos e indeferidos), um analista
escolheu um algoritmo que divide os dados de entrada em
duas regiões separadas por uma linha e resulta em uma
simetria na classificação, de forma que o ponto mais
próximo de cada classe está a uma distância d do ponto
médio entre os dois grupos de classe (hiperplano). O
algoritmo descrito é denominado:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457909
Algoritmos e Estrutura de Dados
O ecossistema Hadoop se refere aos vários componentes
da biblioteca de software Apache Hadoop, incluindo
projetos de código aberto e ferramentas complementares
para armazenar e processar Big Data. Algumas das
ferramentas mais conhecidas incluem HDFS, Pig, YARN,
MapReduce, Spark, HBase Oozie, Sqoop e Kafka, cada
uma com função específica no ecossistema Hadoop. São
funções dos componentes do ecossistema Hadoop:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457908
Engenharia de Software
Naive Bayes é um método probabilístico de aprendizado
de máquina que utiliza as frequências das ocorrências em
uma base de dados para prever uma variável de interesse.
O algoritmo a ser implementado depende da natureza dos
dados manipulados. O tipo de algoritmo Naive Bayes para
processar um conjunto de dados que possui apenas
atributos categóricos codificados em one-hot é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457907
Noções de Informática
O aprendizado de máquina (do inglês, machine learning) é
um conjunto de técnicas da ciência de dados que permite
que os computadores usem os dados existentes para
prever comportamentos, resultados e tendências. Uma das
formas de classificar o aprendizado é em razão da
natureza do sinal de entrada ou feedback do processo. As
árvores de decisão, agrupamento e regras de associação
são, respectivamente, técnicas de aprendizado de
máquina:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Ciência de Dados |
Q2457906
Banco de Dados
Apache Hadoop é o principal framework utilizado no
processamento e armazenamento de grandes conjuntos de
dados (Big Data). No ecossistema Apache Hadoop, além
dos componentes básicos, diversas ferramentas e serviços
suprem necessidades de negócios, aplicações e
arquitetura de dados. O sistema de agendamento de
WorkFlow para gerenciar os jobs de computação
distribuída do MapReduce é o:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438400
Banco de Dados
Analise a consulta SQL a seguir.
Linha 1: SELECT cidade, estado, COUNT(*)
Linha 2: FROM clientes
Linha 3: GROUP BY cidade, estado
Linha 4: UNION ALL
Linha 5: SELECT cidade, estado, COUNT(*)
Linha 6: FROM empregados
Linha 7: GROUP BY cidade, estado
Para ordenar os resultados retornados pela consulta SQL acima, a cláusula ORDER BY deve ser inserida:
Linha 1: SELECT cidade, estado, COUNT(*)
Linha 2: FROM clientes
Linha 3: GROUP BY cidade, estado
Linha 4: UNION ALL
Linha 5: SELECT cidade, estado, COUNT(*)
Linha 6: FROM empregados
Linha 7: GROUP BY cidade, estado
Para ordenar os resultados retornados pela consulta SQL acima, a cláusula ORDER BY deve ser inserida:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438399
Arquitetura de Computadores
Um analista identificou um problema com os relatórios das
operações aritméticas computacionais de um sistema.
Para garantir o adequado processamento e promover as
correções no ambiente operacional, após receber a
solução de sua equipe, validou como correto o seguinte
resultado da operação aritmética em hexadecimal:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438398
Banco de Dados
A mudança de uma hierarquia (orientação) dimensional
para outra tem sua realização facilitada em um cubo de
dados por meio de uma técnica chamada:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438396
Banco de Dados
Um administrador de banco de dados MySQL precisa
realizar o restore do banco de dados "tjac_db", a partir de
um arquivo de backup previamente criado com o nome
backuptjac.sql. Para isso, deverá utilizar o comando:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438395
Sistemas Operacionais
Um sistema do TJ-AC faz uso de alocação particionada
estática com suas partições estabelecidas na inicialização.
Excluindo a área do sistema operacional, a divisão das
partições está descrita na tabela a seguir:
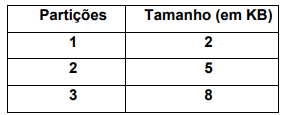
Considerando que existam 5 programas a serem executados conforme descrito na tabela a seguir:
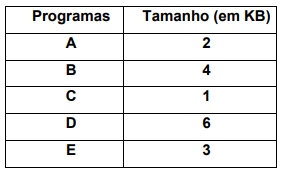
A sequência de alocação dos três programas iniciais nas partições 1,2 e 3 a ser executada de forma a obter a menor fragmentação interna é:
Considerando que existam 5 programas a serem executados conforme descrito na tabela a seguir:
A sequência de alocação dos três programas iniciais nas partições 1,2 e 3 a ser executada de forma a obter a menor fragmentação interna é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438393
Banco de Dados
Um Banco de Dados Distribuído (BDD) é uma coleção de
múltiplos bancos de dados logicamente interrelacionados e
distribuídos por uma rede de computadores. O controle de
concorrência se baseia no bloqueio, exatamente como na
maioria dos sistemas não distribuídos. Todavia,
requisições para testar, impor e liberar bloqueios se tornam
mensagens e, por essa razão, o controle de concorrência
em BDD tem como premissa o tratamento da:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438392
Banco de Dados
A capacidade de alterar o esquema conceitual sem que
seja necessário alterar os esquemas externos ou os
programas de aplicação, é denominada independência:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438391
Banco de Dados
Uma característica típica dos bancos de dados orientados
a documentos é que eles utilizam:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438390
Banco de Dados
Restrições de integridade são utilizadas para garantir a
exatidão e a consistência dos dados em um banco de
dados relacional, ou seja, garantir que dados representem
assertivamente a realidade modelada. No âmbito das
restrições de integridade de entidade, a definição válida é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438388
Banco de Dados
A regra de SGBD distribuído que define que a
probabilidade de o sistema funcionar sem queda em
qualquer momento dado’’, porque, por ser distribuído, pode
continuar a funcionar, mesmo diante da falha de algum
componente individual, tal como um site isolado, é
designada:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438387
Banco de Dados
Observe a seguinte arquitetura de uma solução de
Business Intelligence implementada no TJ-AC.
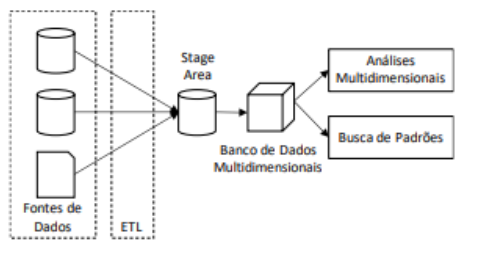
O elemento arquitetural implementado por meio de operações OLAP, como slice, rotate, drill-down e drill-up, é o:
O elemento arquitetural implementado por meio de operações OLAP, como slice, rotate, drill-down e drill-up, é o:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438386
Banco de Dados
SQL é a linguagem padrão para manipulação de registros
em bancos de dados relacionais. Apresenta uma
organização estrutural bem-definida, dividindo seus
comandos em cinco (5) subconjuntos: DML (Data
Manipulation Language), DTL (Data Transaction
Language), DDL (Data Definition Language), DQL (Data
Query Language) e DCL (Data Control Language). São,
respectivamente, função e exemplo de comandos do
subconjunto DDL:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438385
Banco de Dados
Observe o seguinte script de concessão de privilégios em
MYSQL:
CREATE DATABASE db;
CREATE TABLE db.t1 (c INT);
INSERT INTO db.t1 VALUES ROW (1);
CREATE TABLE db.t2 (c INT);
INSERT INTO db.t2 VALUES ROW (1);
CREATE USER u1;
GRANT SELECT, UPDATE ON db.t1 TO u1 WITH GRANT
OPTION;
CREATE USER u2;
GRANT SELECT, INSERT ON db.t2 TO u2;
CREATE USER u3;
GRANT ALL ON db.* TO u3;
REVOKE INSERT ON db.t2 FROM u2;
O resultado obtido pela execução do referido script, no que tange aos usuários, é:
CREATE DATABASE db;
CREATE TABLE db.t1 (c INT);
INSERT INTO db.t1 VALUES ROW (1);
CREATE TABLE db.t2 (c INT);
INSERT INTO db.t2 VALUES ROW (1);
CREATE USER u1;
GRANT SELECT, UPDATE ON db.t1 TO u1 WITH GRANT
OPTION;
CREATE USER u2;
GRANT SELECT, INSERT ON db.t2 TO u2;
CREATE USER u3;
GRANT ALL ON db.* TO u3;
REVOKE INSERT ON db.t2 FROM u2;
O resultado obtido pela execução do referido script, no que tange aos usuários, é:
Ano: 2024
Banca:
IV - UFG
Órgão:
TJ-AC
Prova:
CS-UFG - 2024 - TJ-AC - Analista Judiciário - Analista de Banco de Dados |
Q2438384
Banco de Dados
Seja o esquema relacional:
create table X1(
A1 int not null primary key,
B1 int)
create table X2(
A2 int not null primary key,
B2 int)
create table X3(
A1 int not null unique,
A2 int,
B3 int,
foreign key(A1) references X1(A1),
foreign key(A2) references X2(A2)
)
Para o esquema apresentado, a relação que existe entre as tabelas X1, X2 e X3 é descrita por:
create table X1(
A1 int not null primary key,
B1 int)
create table X2(
A2 int not null primary key,
B2 int)
create table X3(
A1 int not null unique,
A2 int,
B3 int,
foreign key(A1) references X1(A1),
foreign key(A2) references X2(A2)
)
Para o esquema apresentado, a relação que existe entre as tabelas X1, X2 e X3 é descrita por: