Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 194.716 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952887
Noções de Informática
No que se refere às ferramentas de colaboração e
comunicação, uma foi criada pela Microsoft, com
suporte a diversas funcionalidades, como:
reuniões, com recursos como agendamento automatizado e transcrições automáticas;
canais, para discussão de tópicos específicos, facilitando a organização das comunicações;
chamadas de vídeo, com recursos avançados de áudio e vídeo, para reuniões em tempo real;
integração com outros aplicativos da plataforma Microsoft 365, como Word e Excel;
gerenciamento de equipes, em atividades de projetos e tarefas, com colaboração em tempo real.
Essa ferramenta é conhecida como Microsoft:
reuniões, com recursos como agendamento automatizado e transcrições automáticas;
canais, para discussão de tópicos específicos, facilitando a organização das comunicações;
chamadas de vídeo, com recursos avançados de áudio e vídeo, para reuniões em tempo real;
integração com outros aplicativos da plataforma Microsoft 365, como Word e Excel;
gerenciamento de equipes, em atividades de projetos e tarefas, com colaboração em tempo real.
Essa ferramenta é conhecida como Microsoft:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952886
Noções de Informática
Computação em Nuvem é definida como a entrega
de recursos de TI sob demanda por meio da
internet, com preço conforme o uso. Em vez de
comprar, ter e manter data centers e servidores
físicos, pode-se acessar serviços de tecnologia,
como capacidade computacional, armazenamento
e bancos de dados, de acordo com a necessidade,
usando um provedor de nuvem. Entre os tipos
disponíveis, um se destaca por conter os
componentes básicos da TI na nuvem.
Normalmente, oferece acesso a recursos de rede,
computadores (virtuais ou em hardware dedicado)
e espaço de armazenamento de dados. Por
característica, oferece o mais alto nível de
flexibilidade e controle de gerenciamento e
constitui o tipo de computação mais semelhante
aos recursos existentes de TI, já conhecidos por
vários departamentos e desenvolvedores da área.
Esse tipo é conhecido pela sigla:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952885
Noções de Informática
Atualmente, ao navegar em sites da internet por
meio de browsers, como no Microsoft Edge, Google
Chrome e Firefox Mozilla, em um notebook Intel
com Windows 11 BR (x64), é possível visualizar a
página do site corrente na modalidade tela cheia por
meio do acionamento de uma tecla de função e,
paralelamente, imprimir o conteúdo da homepage
por meio da execução de um atalho de teclado.
A tecla de função e o atalho de teclado são, respectivamente:
A tecla de função e o atalho de teclado são, respectivamente:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952882
Noções de Informática
A planilha da figura abaixo foi criada no Excel do
pacote MS Office 2024 BR, em um notebook com
Windows 11 BR (x64).
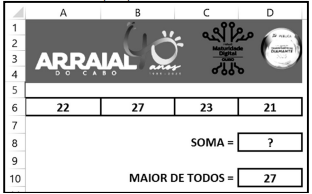
Em D8 foi inserida a fórmula =SOMA(A6;D6).
Em D10 foi inserida uma fórmula usando a função MAIOR, que determina o maior número dentre todos nas células A6, B6, C6 e D6.
Nessas condições, o número mostrado em D8 e a fórmula inserida em D10 são, respectivamente:
Em D8 foi inserida a fórmula =SOMA(A6;D6).
Em D10 foi inserida uma fórmula usando a função MAIOR, que determina o maior número dentre todos nas células A6, B6, C6 e D6.
Nessas condições, o número mostrado em D8 e a fórmula inserida em D10 são, respectivamente:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952881
Noções de Informática
No editor de textos Writer da suíte LibreOffice
24.8.3.2 versão em português, em um
microcomputador com Windows 10 BR (x64), o acionamento do ícone  tem um objetivo
bem definido. Como alternativa, esse ícone pode
também ser acionado por meio da execução de um
atalho de teclado.
tem um objetivo
bem definido. Como alternativa, esse ícone pode
também ser acionado por meio da execução de um
atalho de teclado.
Das alternativas abaixo, aquela que apresenta corretamente o objetivo e o atalho de teclado são, respectivamente:
tem um objetivo
bem definido. Como alternativa, esse ícone pode
também ser acionado por meio da execução de um
atalho de teclado. Das alternativas abaixo, aquela que apresenta corretamente o objetivo e o atalho de teclado são, respectivamente:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952880
Sistemas Operacionais
No Linux, “pasta” refere-se a diretórios que
organizam arquivos e outras pastas, e sua gestão
é essencial para a eficiência do sistema
operacional. Entre os diretórios, um armazena
todos os ficheiros globais de configuração do
sistema, enquanto outro contém diversos arquivos
necessários à partida do sistema operacional.
Nesse contexto, esses dois diretórios são,
respectivamente:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952879
Noções de Informática
No funcionamento e operação de
microcomputadores e notebooks, há dispositivos
que operam exclusivamente na entrada dos dados
e há outros que operam exclusivamente na saída
dos dados. Há ainda uma terceira categoria que se
caracteriza por operar tanto na entrada como na
saída, mas em momentos distintos. A alternativa
que apresenta, nesta ordem, um exemplo de cada
uma dessas categorias é a seguinte:
Ano: 2026
Banca:
IBAM
Órgão:
Prefeitura de Arraial do Cabo - RJ
Prova:
IBAM - 2026 - Prefeitura de Arraial do Cabo - RJ - Auxiliar Administrativo |
Q3952878
Noções de Informática
No que se refere às modalidades de
processamento, um tipo é definido como o
processamento atualizado, no qual as informações
são processadas no mesmo momento em que são
registradas, ao passo que em outro tipo as tarefas
são agrupadas fisicamente em lotes e
processadas sequencialmente uma após a outra,
sendo que, após iniciado, o processamento é
executado até o término da última tarefa, sem que
o usuário tenha acesso a ele.
Esses dois tipos de modalidades de processamento são conhecidos, respectivamente, como:
Esses dois tipos de modalidades de processamento são conhecidos, respectivamente, como:
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952857
Banco de Dados
Considere o código em SQL a seguir.

A execução desse código retornará
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952856
Banco de Dados
Considere uma tabela chamada Livros com as colunas id (int), autor (varchar) e ano (int). Sabe-se que
alguns livros não são datados, resultando em valores NULL na coluna ano. Considere o seguinte comando
SQL:
SELECT * FROM Livros WHERE ano <> 1854;
Ao ser executado, esse comando retornará
SELECT * FROM Livros WHERE ano <> 1854;
Ao ser executado, esse comando retornará
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952855
Programação
Sobre as características fundamentais do modelo de dados e da tipagem, é correto afirmar que o
Python 3 é uma linguagem
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952854
Banco de Dados
Com relação aos conceitos e tipos ELT e ETL de pipeline de dados, analise as afirmativas a seguir.
I. A abordagem ELT é recomendada para tarefas relacionadas a LGPD porque realiza a limpeza de dados sensíveis antes que eles atinjam o sistema de destino, reduzindo riscos de segurança e economizando espaço de armazenamento.
II. No processo ETL, o conjunto de dados completo e sem tratamento é carregado diretamente no sistema de destino. Como há apenas uma etapa, e ela ocorre apenas uma vez, o carregamento no processo ETL é mais rápido do que no ELT.
III. Na abordagem ELT, é possível aproveitar o poder de processamento distribuído e a escalabilidade elástica do data warehouse de destino para realizar transformações via SQL, eliminando a necessidade de um servidor de processamento intermediário.
É verdadeiro o que é afirmado em
I. A abordagem ELT é recomendada para tarefas relacionadas a LGPD porque realiza a limpeza de dados sensíveis antes que eles atinjam o sistema de destino, reduzindo riscos de segurança e economizando espaço de armazenamento.
II. No processo ETL, o conjunto de dados completo e sem tratamento é carregado diretamente no sistema de destino. Como há apenas uma etapa, e ela ocorre apenas uma vez, o carregamento no processo ETL é mais rápido do que no ELT.
III. Na abordagem ELT, é possível aproveitar o poder de processamento distribuído e a escalabilidade elástica do data warehouse de destino para realizar transformações via SQL, eliminando a necessidade de um servidor de processamento intermediário.
É verdadeiro o que é afirmado em
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952853
Noções de Informática
No programa Microsoft Excel 365, versão desktop em Português (Brasil) para Windows, um analista
inseriu os seguintes valores em uma planilha:
Célula A1: 10
Célula A2: 20
Célula A3: 30
Célula A4: 10
Após digitar a fórmula =SOMA($A$1:A2) na célula B1, o analista utilizou a alça de preenchimento para arrastar a fórmula da célula B1 até a célula B3. O resultado exibido na célula B3 será
Célula A1: 10
Célula A2: 20
Célula A3: 30
Célula A4: 10
Após digitar a fórmula =SOMA($A$1:A2) na célula B1, o analista utilizou a alça de preenchimento para arrastar a fórmula da célula B1 até a célula B3. O resultado exibido na célula B3 será
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952852
Noções de Informática
Considere o fragmento de planilha abaixo, elaborado no programa Microsoft Excel 365, versão desktop
em Português (Brasil) para Windows.
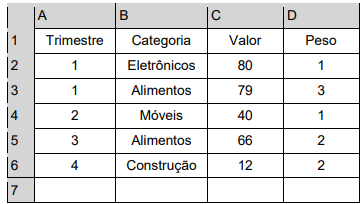
Se a fórmula =SOMARPRODUTO(- -(B2:B6="Alimentos");C2:C6;D2:D6) for inserida na célula C7, o resultado a ser apresentado nessa célula será
Se a fórmula =SOMARPRODUTO(- -(B2:B6="Alimentos");C2:C6;D2:D6) for inserida na célula C7, o resultado a ser apresentado nessa célula será
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952850
Programação
Considere o código em Python 3 a seguir.

O resultado da execução desse código será
O resultado da execução desse código será
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952849
Programação
Considere o código em Python 3 a seguir.
a = [2,4,3]
b = a[:]
c = a
a.append(7)
print(b + c)
O resultado da execução desse código será
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952848
Banco de Dados
Os comandos DROP e TRUNCATE da linguagem de consulta estruturada (SQL) pertencem à categoria
de comandos
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952847
Banco de Dados
Em relação aos repositórios de dados data lake e data warehouse em arquiteturas de Big Data, analise
as afirmativas a seguir.
I. Um data lake é caracterizado por priorizar a ingestão de dados em seu formato original, permitindo armazenar dados estruturados, semiestruturados e não estruturados, com uso de abordagens de schema-on-read.
II. Um data warehouse adota schema-on-write, exigindo modelagem prévia, como esquemas em estrela ou floco de neve, para suportar consultas analíticas otimizadas.
III. A simples adoção de schema-on-write em um data lake o caracteriza automaticamente como um data warehouse.
É verdadeiro o que se afirma em
I. Um data lake é caracterizado por priorizar a ingestão de dados em seu formato original, permitindo armazenar dados estruturados, semiestruturados e não estruturados, com uso de abordagens de schema-on-read.
II. Um data warehouse adota schema-on-write, exigindo modelagem prévia, como esquemas em estrela ou floco de neve, para suportar consultas analíticas otimizadas.
III. A simples adoção de schema-on-write em um data lake o caracteriza automaticamente como um data warehouse.
É verdadeiro o que se afirma em
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952846
Engenharia de Software
No Extreme Programming (XP), práticas que dão suporte à propriedade coletiva do código incluem
Ano: 2026
Banca:
FADESP
Órgão:
SEFAZ-PA
Prova:
FADESP - 2026 - SEFAZ-PA - Auditor Fiscal de Receitas Estaduais - Conhecimentos Gerais |
Q3952844
Sistemas de Informação
No que tange a preparação de dados no Power Query, a linguagem M é utilizada para