Selecionar segmento
Estude com questões de diferentes segmentos
Atenção: Isso limpará todos os campos já preenchidos no filtro!
Foram encontradas 54.747 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098537
Segurança e Saúde no Trabalho
Médicos do trabalho exercem papel fundamental
na mediação entre empregado e empregador no
que diz respeito ao exercício da objetividade dessa
profissão, que é de conhecer os enfermos e as
suas doenças. Pressupõe-se que essa medicina
estuda, previne e trata os males das doenças
derivadas do trabalho e/ou de seu ambiente, sendo
que esse trabalho depende de instrumentos
técnicos e do relacionamento humano e ético.
Acerca desse tema, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098536
Medicina
Os pesticidas sistêmicos são produtos químicos
solúveis em água que são absorvidos pelas
plantas e transportados para a parte da planta em
que uma praga, usualmente um inseto, se alimenta
dos sucos e ingere o pesticida. As exposições e as
incidências mais elevadas de envenenamento
ocorrem em indivíduos que trabalham nas
operações agrícolas pós-controle: operações de
mistura, carregamento, aplicação e sinalização.
Nesse contexto, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098535
Medicina
Um funcionário que trabalha como pintor comparece para avaliação periódica em um consultório de medicina do trabalho. Ao exame físico, o funcionário apresenta comportamento estranho, atípico e sintomas delirantes, além de manchas arroxeadas nas gengivas e queixa de cefaleia. A principal hipótese diagnóstica é
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098534
Segurança e Saúde no Trabalho
A Equação de NIOSH é uma ferramenta valiosa
para avaliação ergonômica, especialmente quando
se trata de levantamento e transporte de carga.
Essa equação leva em consideração diversos
fatores. Sobre o tema, assinale a alternativa
correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098533
Segurança e Saúde no Trabalho
João, 32 anos, operador de máquinas em uma
indústria metalúrgica, trabalhava há 5 anos na
empresa. Ele havia recebido treinamento periódico
de segurança, devidamente registrado, para
operação de prensas hidráulicas. Entre as
orientações fornecidas estavam:
• uso obrigatório de EPI (luvas, óculos de proteção e protetor auricular); • proibição de remover dispositivos de travamento e proteção; • proibição de colocar as mãos na matriz durante o ciclo de prensagem; • obrigatoriedade de desligar a máquina (NR-12) durante limpeza ou ajustes.
Em determinado dia, João percebeu um pequeno desalinhamento da peça que estava sendo produzida. Intencionalmente, ele inseriu a mão na matriz com a máquina em funcionamento para “ganhar tempo”, como relatado posteriormente por colegas. A prensa acionou automaticamente o ciclo e João sofreu fratura de falanges e esmagamento parcial da mão direita. Quanto ao caso descrito, assinale a alternativa correta.
• uso obrigatório de EPI (luvas, óculos de proteção e protetor auricular); • proibição de remover dispositivos de travamento e proteção; • proibição de colocar as mãos na matriz durante o ciclo de prensagem; • obrigatoriedade de desligar a máquina (NR-12) durante limpeza ou ajustes.
Em determinado dia, João percebeu um pequeno desalinhamento da peça que estava sendo produzida. Intencionalmente, ele inseriu a mão na matriz com a máquina em funcionamento para “ganhar tempo”, como relatado posteriormente por colegas. A prensa acionou automaticamente o ciclo e João sofreu fratura de falanges e esmagamento parcial da mão direita. Quanto ao caso descrito, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098532
Estatuto da Pessoa com Deficiência - Lei nº 13.146 de 2015
Um médico do trabalho está realizando exames
admissionais de diversos candidatos para o cargo
de professor. Durante o trabalho, precisa avaliar
alguns casos de candidatos classificados como
Pessoa com Deficiência. A empresa tem 600
funcionários e está classificada como grau de risco
3, de acordo com o CNAE da empresa. Em relação
ao tema, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098531
Direito Previdenciário
Após 30 dias de contrato de trabalho, uma
funcionária sofreu uma torção de tornozelo
ocorrida enquanto ministrava aula, ocasionando
um acidente de trabalho típico. A lesão obrigou a
funcionária a sair de licença médica por 90 dias; ao
final do período, manteve anquilose da articulação
do tornozelo afetado, impactando na marcha
funcional. Trata-se do primeiro emprego da
funcionária sob regime da CLT. A respeito desse
caso, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098530
Segurança e Saúde no Trabalho
O exercício do trabalho em condições de
insalubridade assegura ao trabalhador um
adicional salarial. A respeito das atividades em
condições insalubres, um médico do trabalho é
abordado por um trabalhador com dúvida acerca
do percentual de insalubridade. O funcionário
refere percentual de 10% sobre o salário-mínimo
devido à exposição a risco biológico por efetuar
trabalho na recepção de um laboratório de análises
clínicas. Sobre o caso, o médico explica ao
trabalhador que
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098529
Segurança e Saúde no Trabalho
O ruído é um tipo de risco ocupacional classificado
como do tipo físico e pode ser classificado como
contínuo ou intermitente, ou, ainda, como ruído de
impacto. A Norma de Higiene Ocupacional 01
(NHO-1) estabelece critérios e procedimentos para
avaliação da exposição ocupacional ao ruído.
Sobre o ruído e suas avaliações, assinale a
alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098528
Medicina
Uma colaboradora procura o médico do trabalho
com queixa de dormência nos braços, e ele efetua
um exame clínico ortopédico detalhado buscando
chegar a uma hipótese diagnóstica. Sobre as
manobras ortopédicas na medicina do trabalho,
assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098527
Segurança e Saúde no Trabalho
Um funcionário do SESMT de determinada
empresa procura o médico do trabalho
demonstrando preocupação importante com o
resultado de um exame solicitado no exame
periódico da empresa. O exame é o Anti-HbS,
solicitado após um acidente de trabalho
envolvendo material biológico. Diante do caso, o
médico deve
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098526
Segurança e Saúde no Trabalho
O médico do trabalho de determinada empresa
descobre que uma funcionária que estava gestante
entrou em licença-maternidade após o nascimento
do bebê, ocorrido em 12 de março de 2025.
Entretanto, diante de complicações relacionadas
ao parto, a criança permaneceu internada até o dia
30 de junho do mesmo ano, quando recebeu alta.
Sendo assim, o médico deve
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098525
Direito Processual Civil - Novo Código de Processo Civil - CPC 2015
Você trabalhou em uma empresa há dez anos e foi
nomeado como perito do juízo em um processo
judicial envolvendo essa empresa. Nesse contexto,
assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098524
Medicina
Um trabalhador comparece a um consultório de
medicina do trabalho reclamando de um possível
adoecimento de origem laboral. Ele apresenta
relatório do médico assistente que descreve CID10 Z73, associado à descrição entre parênteses de
Síndrome de Burnout. Nesse contexto, assinale a
alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098523
Segurança e Saúde no Trabalho
O Perfil Profissiográfico Profissional (PPP)
constitui-se em documento utilizado para
comprovar as condições de trabalho e a exposição
a agentes nocivos à saúde para fins
previdenciários e trabalhistas. Sobre esse
documento, assinale a alternativa INCORRETA.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098522
Segurança e Saúde no Trabalho
Um funcionário, durante o exame de retorno ao
trabalho, se queixa dos óculos de proteção,
equipamento de proteção individual (EPI),
disponibilizados pela empresa, alegando
dificuldade de adaptação. Ele demonstra que
utiliza óculos para correção visual e adquiriu um
equipamento por meios próprios, do qual lança
mão durante a execução do trabalho na empresa.
O médico do trabalho pede para examinar o
equipamento apresentado. Com base nessa
situação, o médico deve
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098521
Segurança e Saúde no Trabalho
Uma das principais causas de acidentes de
trabalho graves e fatais se deve a eventos
envolvendo quedas de trabalhadores de diferentes
níveis. Os riscos de queda em altura existem em
vários ramos de atividades e em diversos tipos de
tarefas. Sobre esse tema, que é abordado na NR35, assinale a alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098520
Segurança e Saúde no Trabalho
Você, como médico do trabalho e coordenador do
PCMSO de uma empresa de planos de saúde que
tem 700 funcionários, precisa realizar
apresentação perante o CEO da empresa acerca do
relatório analítico referente ao ano anterior. No
primeiro slide, você aponta que foram realizados
680 exames periódicos no ano anterior, 20 exames
demissionais, 40 exames admissionais, 80 exames
de mudança de risco ocupacional e 90 exames de
retorno ao trabalho. Sobre esse tema, assinale a
alternativa correta.
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098519
Segurança e Saúde no Trabalho
Um médico do trabalho foi chamado para participar
de uma reunião da universidade em que trabalha
pois a Diretora de Recursos Humanos tinha
dúvidas quanto à obrigatoriedade de composição
e manutenção do SESMT na universidade. Na
ocasião, foi apresentado um primeiro slide
contendo o CNAE da instituição, conforme imagem
a seguir:
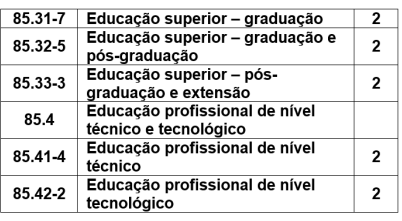
O médico recebe a informação de que o CNAE da instituição é 85.32-5, tem 1200 funcionários regidos pela CLT. Após a apresentação, é correto concluir que
O médico recebe a informação de que o CNAE da instituição é 85.32-5, tem 1200 funcionários regidos pela CLT. Após a apresentação, é correto concluir que
Ano: 2026
Banca:
INSTITUTO AOCP
Órgão:
UNIRIO
Prova:
INSTITUTO AOCP - 2026 - UNIRIO - Médico - Área - Trabalho |
Q4098518
Psicologia
Um professor universitário comparece ao
atendimento médico para realização de exame
periódico e, no curso do atendimento, relata
sensação de não ter mais energia para preparar as
aulas, orientar, pesquisar e, até mesmo, participar
das reuniões acadêmicas. Afirma que passou a se
distanciar dos colegas, chegando até mesmo a se
tornar sarcástico nas últimas reuniões. Refere
estranhamento quanto às próprias reações e que
não se reconhece quando se percebe nessas
condições. Considerando esse quadro clínico,
assinale a alternativa correta.