Foram encontradas 13.780 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
1. _____________: A transação deve ser concluída em sua totalidade ou não ocorrer de forma alguma.
2. _____________: A transação deve levar o banco de dados de um estado consistente a outro estado consistente.
3. _____________: As operações de uma transação não devem ser visíveis para outras transações até que estejam completas.
4. _____________: Uma vez que a transação é concluída, suas mudanças persistem, mesmo em caso de falha do sistema.
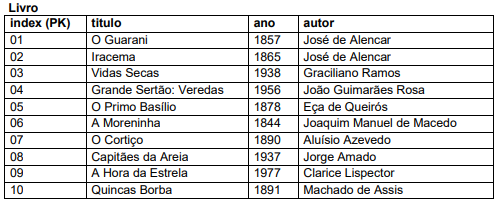
I. O comando "SELECT titulo FROM Livro WHERE ano > 1900;" retornaria os valores Vidas Secas, Grande Sertão: Veredas, Capitães da Areia e A Hora da Estrela.
II. O comando "SELECT titulo FROM Livro WHERE autor IN (SELECT autor FROM Livro GROUP BY autor HAVING COUNT(titulo) > 1);" retornaria os valores O Guarani, Iracema, O Primo Basílio e Quincas Borba.
III. O comando "SELECT ano FROM Livro WHERE ano < 1870;" retornaria os valores O Guarani, Iracema e A Moreninha.
IV. O comando "SELECT titulo FROM Livro WHERE autor >= 'A' AND autor < 'I';" retornaria os valores O Cortiço, A Hora da Estrela, O Primo Basílio e Vidas Secas.
1. Atributo ___________: Pode ser subdividido em outros atributos.
2. Atributo ___________: Pode conter vários valores para uma entidade.
3. Atributo ___________: Valor que pode ser derivado de outros atributos.
I. A análise de cardinalidade em uma coluna consiste em identificar o número de valores distintos presentes, sendo útil para reconhecer possíveis chaves candidatas e detectar colunas com baixa variabilidade que podem indicar problemas de qualidade.
II. O profiling de nulidade verifica a proporção de valores ausentes em cada coluna, fornecendo informações relevantes para decisões sobre estratégias de tratamento, como imputação, exclusão de registros ou criação de indicadores de ausência.
III. A análise de distribuição de frequência permite identificar quais valores ocorrem com maior regularidade em uma coluna e é aplicável exclusivamente a colunas com tipos de dados numéricos, não sendo útil para colunas do tipo texto ou categórico.
IV. O profiling básico, por ser uma análise estática realizada antes da ingestão, elimina a necessidade de validações de qualidade posteriores durante as fases de transformação e carga, desde que o dataset analisado não sofra alterações estruturais.
Estão CORRETAS:
{ "pedido_id": 1042, "cliente": { "nome": "Maria Souza", " cpf" : " 123.456.789-00", "ativo": true }, "itens": [ { "produto": "Notebook", "quantidade": 1, "preco": 3500.00}, { "produto": "Mouse", "quantidade": 2, "preco":45.50 } ], "observacao": null }
Com base na estrutura e nas especificações do formato JSON, assinale a alternativa CORRETA.
O formato CSV é amplamente utilizado em pipelines de dados para transferência de conjuntos de dados entre sistemas heterogêneos. Apesar de sua simplicidade, o formato apresenta características e limitações técnicas que devem ser consideradas durante a implementação de processos de ingestão e integração. Diante disso, analise as afirmativas a seguir sobre o formato CSV:
II. Um arquivo CSV suporta a representação nativa de dados hierárquicos e aninhados, como listas de itens vinculados a um único registro pai, desde que os delimitadores aninhados sejam configurados corretamente no parser utilizado.
III. Quando um valor de campo contém o caractere delimitador, esse campo deve ser envolvido entre aspas duplas para que o parser o interprete como um único valor, conforme previsto pela especificação RFC 4180.
IV. A codificação de caracteres utilizada em um arquivo CSV é declarada de forma explícita no próprio arquivo, garantindo que sistemas distintos realizem a leitura correta dos dados sem necessidade de configuração adicional.
Está(ão) CORRETA(S):
No contexto de Backup e Recuperação no SQL Server, diferentes tipos de backup são utilizados para proteger os dados do banco e garantir a possibilidade de restauração em caso de falhas ou perda de informações.
Considerando esses tipos de backup, qual alternativa descreve CORRETAMENTE a estratégia adotada pelo backup diferencial?
Qual é o nome desse componente?
Nesse contexto, qual cláusula SQL deve ser utilizada pelo Analista para atender a essa necessidade?
No contexto de Backup, Restore e Recuperação no SQL Server, os modelos de recuperação definem como o log de transações é mantido e como o banco de dados pode ser restaurado em caso de falhas. Entre os principais modelos estão: Simple, Full e Bulk-Logged. Assim, analise as assertivas a seguir sobre os modelos de recuperação e julgue-as em Verdadeiras (V) ou Falsas (F):
( ) No modelo Full, o log de transações não é truncado automaticamente.
( ) Nos modelos Simple e Full, não é possível realizar restauração point-in-time.
( ) No modelo Bulk-Logged, é possível realizar restauração point-in-time mesmo que operações bulk tenham ocorrido.
Qual alternativa preenche, CORRETAMENTE, de cima para baixo, os parênteses acima?