Foram encontradas 1.880 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Uma das principais características de um banco de dados Big Data é:
Para obter esse subconjunto de dados, Julia utilizou uma ferramenta OLAP e executou a seguinte operação:
FONTE DE DADOS 1: Tabela TB_PROC Atributo: ID_P Descrição: Identificador único da tabela TB_PROC Quantidade de Registros: 3.250 Valor Inicial: 1 Valor Final: 3.250 Valores Nulos: 0
FONTE DE DADOS 2: Tabela TAB_P Atributo: ID_PROC Descrição: Identificador único da tabela TAB_P Quantidade de Registros: 250 Valor Inicial: 1 Valor Final: 250 Valores Nulos: 0
Para integrar e armazenar os 3.500 registros das Fontes de Dados 1 e 2 na Dimensão DIM_PROC do JusDW, identificando unicamente cada novo registro criado da DIM_PROC, é necessário criar uma:
• a TABELA A foi criada pelo script:
CREATE TABLE a ( id INT AUTO_INCREMENT PRIMARY KEY, descricao VARCHAR(255) NOT NULL, custo DECIMAL(10, 2), tipo CHAR(1), CHECK (tipo IN ('A', 'B', 'C')) );
• a TABELA B foi criada pelo script:
CREATE TABLE b ( id INT AUTO_INCREMENT PRIMARY KEY, descricao VARCHAR(255) NOT NULL, custo DECIMAL(10, 2) NOT NULL, tipo TINYINT, CHECK (tipo IN (1,2,3)) );
• A TABELA A foi carregada e a coluna CUSTO possui valores NULOS.
O script para carregar os dados da TABELA A para a TABELA B é:
Para isso, João deverá utilizar o comando:
Para atender esses requisitos, o administrador deverá criar um banco de dados:
Analise o script de uma stored procedure no âmbito do SQL Server.

Nesse contexto, considere as três hipóteses de comandos que invocam o procedimento armazenado TESTE.
I.
EXECUTE TESTE '99999999900', '1000999';
II.
EXEC TESTE @CPF = '99999999900',
@Produdo = '1000999';
III.
EXECUTE TESTE @CPF = '99999999900' and
@Produdo = '1000999';
Está correto o que se apresenta em:
Como o banco de dados contém termos no idioma português, João deveria adotar em seus bancos de dados SQL Server o default de collation (agrupamento, na interface em português):
Considere as tabelas T1 e T2, exibidas abaixo com suas respectivas instâncias.
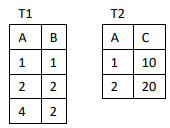
Analise o comando a seguir quando aplicado à tabela T1, anteriormente descrita.
delete from T1
where A >= (select min(A) from T1)
and A <= (select max(A) from T1)
O efeito desse comando sobre a tabela T1 é:
Considere as tabelas T1 e T2, exibidas abaixo com suas respectivas instâncias.
select * from T1 UNION ALL select * from T1 UNION select * from T1
Afora os títulos, o número de linhas produzidas pela execução do comando acima é:
Considere as tabelas T1 e T2, exibidas abaixo com suas respectivas instâncias.
Observe o comando SQL a seguir.
select sum(A) from T1
where not exists
(select * from T2 where T1.A = 2 * T2.A)
Dadas as tabelas T1 e T2, descritas anteriormente, o resultado da execução desse comando exibe o valor:
Nesse contexto, o ciclo iniciado por um comando begin transaction tem, como complemento, o(s) comando(s):
X → Y X → Z Z → X Y → Z X → W
A lista das colunas que devem necessariamente ser definidas com a propriedade unique, com colunas isoladas ou em conjunto, é:
select * from TAB t where not exists (select * from TAB tt where t . B = tt . B and t . A > tt . A)
Além da linha de títulos, o número de linhas produzidas pelo comando acima é:
Numa instalação Oracle PL/SQL, um cursor tem quatro atributos que podem ser referenciados pela sintaxe a seguir.
cursor_name%attribute
Esses atributos são:
Considerando uma tabela hipotética, com colunas X, Y e Z, o axioma da transitividade é definido como segue:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
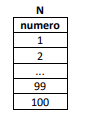
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
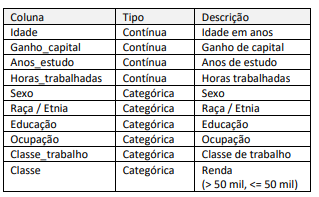
O conjunto de dados PESSOA será usado para a tarefa de aprendizagem supervisionada de classificação com a finalidade de prever se a renda (Classe) de uma pessoa excede 50 mil por ano.
Para isso, a operação de pré-processamento de dados que deve ser executada no conjunto de dados PESSOA é:
Considere a existência de uma tabela relacional N, com apenas uma coluna, intitulada numero, contendo os números inteiros de 1 até 100, um em cada linha, como ilustrada a seguir.
Como pode haver discrepâncias entre implementações da linguagem SQL, é dado que a função sqrt(x) retorna a raiz quadrada de x e que a expressão a % b retorna o resto da divisão inteira de a por b.
• TIPO_EMPRESA ="MEI", RENDA _ANO= "NIVEL A",> QUANTIDADE_SOCIOS=1, SITUACAO_FISCAL="INADIMPLENTE" (suporte = 50%, confiança = 70%)
• TIPO_EMPRESA="Simples", RENDA_ANO="NIVEL B"-> QUANTIDADE_SOCIOS= 2, SITUACAO_FISCAL="REGULAR" (suporte 30%, confiança = 80%)
A técnica de Mineração de dados que Renan aplicou para descobrir elementos que ocorrem em comum dentro de um determinado conjunto de dados foi: