Questões de Concurso
Sobre estatística para fgv
Foram encontradas 1.519 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2025
Banca:
FGV
Órgão:
AgSUS
Prova:
FGV - 2025 - AgSUS - Analista de Gestão Tecnologia da Informação |
Q3660446
Estatística
Matheus é um professor que precisa identificar padrões de
utilização de LLMs (Large Language Models) em um grupo de
estudantes. Ele utilizou como dados as notas finais da avaliação da
disciplina de Estatística Básica (com distribuição das notas
variando 0 a 100) e correlacionou esses dados à quantidade de
horas dedicadas ao uso de LLMs pelos estudantes durante o
semestre. O professor construiu um modelo para prever a
pontuação de um aluno (Y), em função do número de horas
dedicadas ao LLMs durante o último semestre (X), obtendo o
modelo a seguir.
Ŷ = 100 − 0, 25x
Matheus certificou-se que o modelo atende a todas as premissas do modelo de regressão linear. As pontuações esperadas para dois alunos que dedicaram 300 horas e 50 horas ao uso de LLMs no último semestre são, respectivamente,
Ŷ = 100 − 0, 25x
Matheus certificou-se que o modelo atende a todas as premissas do modelo de regressão linear. As pontuações esperadas para dois alunos que dedicaram 300 horas e 50 horas ao uso de LLMs no último semestre são, respectivamente,
Ano: 2025
Banca:
FGV
Órgão:
Prefeitura de Niterói - RJ
Prova:
FGV - 2025 - Prefeitura de Niterói - RJ - Técnico em Geoprocessamento |
Q3657195
Estatística
Em um projeto de cartografia digital aplicado ao trânsito, foi
avaliada a precisão posicional de um conjunto de pontos de
interseções viárias (cruzamentos) levantados em campo com GPS
e comparados com suas coordenadas no mapa digital da cidade.
Para verificar a exatidão do mapeamento, utilizou-se o Erro Médio
Quadrático da Raiz (RMSEr).
Considerando os seguintes erros posicionais (em metros) obtidos para 4 interseções:
• Cruzamento 1: 1,0 m
• Cruzamento 2: 2,0 m
• Cruzamento 3: 1,0 m
• Cruzamento 4: 2,0 m
Considerando √2 = 1,4, √3 = 1,7 e √5 = 2,2, o valor do RMSEr é aproximadamente
Considerando os seguintes erros posicionais (em metros) obtidos para 4 interseções:
• Cruzamento 1: 1,0 m
• Cruzamento 2: 2,0 m
• Cruzamento 3: 1,0 m
• Cruzamento 4: 2,0 m
Considerando √2 = 1,4, √3 = 1,7 e √5 = 2,2, o valor do RMSEr é aproximadamente
Q3645105
Estatística
No processo de digitalização de serviços públicos, o Ministério da
Gestão e da Inovação em Serviços Públicos (MGI) está avaliando
indicadores de desempenho de atendimento ao cidadão. Para
isso, foram registrados os tempos de atendimento (em minutos)
de uma amostra aleatória de 100 registros, resultando nos
seguintes dados estatísticos:
• média: 12 minutos; • mediana: 10 minutos; • desvio padrão: 6 minutos; • mínimo: 3 minutos; • máximo: 32 minutos.
Os analistas estão considerando realizar uma mudança no processo de atendimento, inserindo uma etapa prévia que aumentaria o tempo de cada atendimento em 20%.
Considerando os princípios da inferência estatística e da interpretação de medidas de posição e dispersão, se implementada, a mudança no processo de atendimento:
• média: 12 minutos; • mediana: 10 minutos; • desvio padrão: 6 minutos; • mínimo: 3 minutos; • máximo: 32 minutos.
Os analistas estão considerando realizar uma mudança no processo de atendimento, inserindo uma etapa prévia que aumentaria o tempo de cada atendimento em 20%.
Considerando os princípios da inferência estatística e da interpretação de medidas de posição e dispersão, se implementada, a mudança no processo de atendimento:
Q3643574
Estatística
Um servidor pretende melhorar a estrutura de atendimento aos
cidadãos da unidade em que trabalha. Para isso, selecionou cinco
usuários ao acaso para avaliar, em uma escala de 0 a 10, dois
aspectos do serviço prestado: (a) tempo de espera e (b) clareza
das informações fornecidas. Os dados obtidos com as avaliações
realizadas foram:
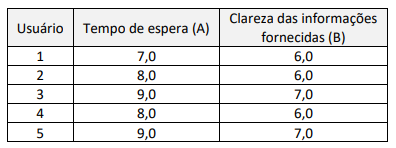
Com base nesses dados, e sabendo que a distribuição das diferenças de avaliação entre os critérios (A – B) pode ser considerada aproximadamente normal, o erro padrão da média das diferenças é igual a:
Com base nesses dados, e sabendo que a distribuição das diferenças de avaliação entre os critérios (A – B) pode ser considerada aproximadamente normal, o erro padrão da média das diferenças é igual a:
Q3643573
Estatística
Analistas do Ministério das Cidades estão estudando o tempo
médio de deslocamento casa-trabalho em uma metrópole
brasileira. A população é composta por 40 mil trabalhadores
formais e, segundo estudos anteriores, o tempo de deslocamento
segue uma distribuição aproximadamente normal, com média
μ=60 minutos e desvio padrão populacional σ=20 minutos.
Três diferentes amostras aleatórias simples foram selecionadas com o objetivo de estimar a média de deslocamento da população:
• amostra 1: 25 pessoas • amostra 2: 100 pessoas • amostra 3: 400 pessoas
Considerando que o objetivo é estimar se a probabilidade de que a média amostral difira da média populacional por, no máximo, 2 minutos (ou seja, esteja no intervalo entre 58 e 62 minutos), os analistas devem considerar que:
Três diferentes amostras aleatórias simples foram selecionadas com o objetivo de estimar a média de deslocamento da população:
• amostra 1: 25 pessoas • amostra 2: 100 pessoas • amostra 3: 400 pessoas
Considerando que o objetivo é estimar se a probabilidade de que a média amostral difira da média populacional por, no máximo, 2 minutos (ou seja, esteja no intervalo entre 58 e 62 minutos), os analistas devem considerar que:
Q3643572
Estatística
Um analista do Instituto Nacional do Seguro Social (INSS) deseja
estimar a média do tempo de espera entre o agendamento e o
atendimento presencial dos segurados. Para isso, ele decide
realizar uma amostragem aleatória simples com reposição a
partir do banco de registros dos últimos meses. O analista deseja
que o erro padrão da média amostral seja igual a 5% do desvio
padrão populacional do tempo de espera.
Com base nessa exigência, o tamanho mínimo da amostra para garantir esse nível de precisão deve ser de:
Com base nessa exigência, o tamanho mínimo da amostra para garantir esse nível de precisão deve ser de:
Q3643571
Estatística
Dois analistas foram designados para estimar a proporção de
empresas prestadoras de serviço de um ministério que tinham
dívidas tributárias. Eles sabiam que o universo era de
500 empresas. O primeiro analista selecionou 50 empresas sem
sorteio, com base em sua experiência, considerando uma
probabilidade subjetiva de inadimplência de 50% entre as
selecionadas. O segundo utilizou amostragem aleatória
estratificada: dividiu as empresas em dois estratos e selecionou
25 empresas de cada um. Os estratos, o número de empresas em
cada estrato e os erros padrão obtidos para o estimador da
proporção em cada estrato foram:
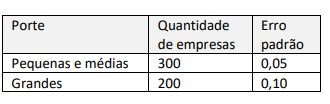
Em relação às variâncias dos estimadores obtidos pelas duas análises, é correto afirmar que:
Em relação às variâncias dos estimadores obtidos pelas duas análises, é correto afirmar que:
Q3642186
Estatística
Aldo está implementando um painel de visualização de dados
com a quantidade de atendimentos ao público que seu setor faz
ao longo do tempo.
Para apresentar a quantidade de atendimentos, Aldo deve implementar uma variável do tipo:
Para apresentar a quantidade de atendimentos, Aldo deve implementar uma variável do tipo:
Q3642032
Estatística
Uma equipe do Ministério Alfa conduz um projeto baseado em
Big Data para entender o perfil de acesso da população a
atividades financiadas com recursos federais. A base integra
milhões de registros oriundos de plataformas digitais de
ingressos, editais culturais, visitas a museus federais e interações
nas redes sociais de equipamentos culturais.
Como a pesquisa ainda não tem uma variável-alvo definida, o objetivo inicial é identificar grupos latentes de usuários com padrões semelhantes de comportamento, considerando variáveis como frequência de participação, região e faixa etária. Após essa etapa, a equipe pretende avaliar os fatores que contribuem para o engajamento cultural em regiões com baixa participação e, por fim, recomendar estratégias de ampliação de acesso.
Considerando os modelos multivariados, a natureza da base de dados e os objetivos e etapas propostos para a pesquisa, a equipe responsável deveria:
Como a pesquisa ainda não tem uma variável-alvo definida, o objetivo inicial é identificar grupos latentes de usuários com padrões semelhantes de comportamento, considerando variáveis como frequência de participação, região e faixa etária. Após essa etapa, a equipe pretende avaliar os fatores que contribuem para o engajamento cultural em regiões com baixa participação e, por fim, recomendar estratégias de ampliação de acesso.
Considerando os modelos multivariados, a natureza da base de dados e os objetivos e etapas propostos para a pesquisa, a equipe responsável deveria:
Q3642031
Estatística
Uma equipe técnica do Ministério da Integração e do
Desenvolvimento Regional está avaliando a satisfação de
beneficiários de um programa habitacional. Para isso, foi
realizada uma amostra aleatória de 625 famílias, extraídas de
uma população de 2.500 famílias participantes
A média da nota de satisfação foi de 7,2 (em uma escala de 0 a 10), e a variância populacional previamente estimada é de 1,44. A equipe deseja construir um intervalo de confiança de 95% para estimar a média da população com base na amostra. Utilize a tabela abaixo com valores da curva normal padrão (Z):

Com base nesses dados, o intervalo de confiança de 95% para a média populacional é, aproximadamente:
A média da nota de satisfação foi de 7,2 (em uma escala de 0 a 10), e a variância populacional previamente estimada é de 1,44. A equipe deseja construir um intervalo de confiança de 95% para estimar a média da população com base na amostra. Utilize a tabela abaixo com valores da curva normal padrão (Z):
Com base nesses dados, o intervalo de confiança de 95% para a média populacional é, aproximadamente:
Q3642030
Estatística
Uma equipe técnica de avaliação de políticas públicas culturais
precisa planejar uma pesquisa amostral para estimar a proporção
de municípios que apresentam execução satisfatória de metas
pactuadas em um programa federal.
O desempenho é considerado satisfatório quando até 5% das metas pactuadas não são cumpridas. Em contrapartida, é considerado insatisfatório quando 20% ou mais das metas pactuadas não são cumpridas.
Os dados prévios são limitados, e a equipe deseja garantir decisões estatisticamente robustas — especialmente quanto à aceitação ou rejeição de municípios com base nos indicadores reportados. Para definir o tamanho da amostra e a regra de decisão sobre o desempenho dos municípios, a equipe técnica estabeleceu os seguintes critérios:
• a margem de erro máxima permitida para estimar a proporção populacional de municípios com desempenho satisfatório é de 4%;
• o nível de confiança deve ser de 95%;
• os erros do tipo I e II devem ser controlados de modo que:
▪ municípios com desempenho considerado bom sejam rejeitados erroneamente em, no máximo, 5% dos casos;
▪ municípios com desempenho considerado ruim sejam aceitos erroneamente em, no máximo, 10% dos casos.
Com base nessas informações, uma interpretação adequada dos parâmetros definidos pela equipe é a de que:
O desempenho é considerado satisfatório quando até 5% das metas pactuadas não são cumpridas. Em contrapartida, é considerado insatisfatório quando 20% ou mais das metas pactuadas não são cumpridas.
Os dados prévios são limitados, e a equipe deseja garantir decisões estatisticamente robustas — especialmente quanto à aceitação ou rejeição de municípios com base nos indicadores reportados. Para definir o tamanho da amostra e a regra de decisão sobre o desempenho dos municípios, a equipe técnica estabeleceu os seguintes critérios:
• a margem de erro máxima permitida para estimar a proporção populacional de municípios com desempenho satisfatório é de 4%;
• o nível de confiança deve ser de 95%;
• os erros do tipo I e II devem ser controlados de modo que:
▪ municípios com desempenho considerado bom sejam rejeitados erroneamente em, no máximo, 5% dos casos;
▪ municípios com desempenho considerado ruim sejam aceitos erroneamente em, no máximo, 10% dos casos.
Com base nessas informações, uma interpretação adequada dos parâmetros definidos pela equipe é a de que:
Q3642027
Estatística
Uma fundação realizou uma pesquisa com beneficiários de um
programa de qualificação para mercado de trabalho que vem
sendo desenvolvido nacionalmente. A coleta foi feita por equipes
descentralizadas em diferentes regiões do país. Os analistas
responsáveis pela análise dos dados foram admitidos
recentemente na equipe e não participaram do planejamento da
pesquisa e da etapa de coleta.
Agora, esses analistas desejam utilizar os dados consolidados para testar a seguinte hipótese: mulheres com mais tempo de permanência no programa apresentam maior renda mensal. Abaixo está uma amostra da base de dados consolidada, em que cada linha corresponde a um respondente:
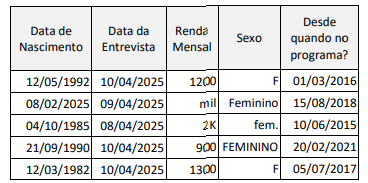
Para viabilizar a realização de testes estatísticos válidos a partir da base de dados acima e responder à pergunta de pesquisa, na etapa do tratamento dos dados, os analistas devem:
Agora, esses analistas desejam utilizar os dados consolidados para testar a seguinte hipótese: mulheres com mais tempo de permanência no programa apresentam maior renda mensal. Abaixo está uma amostra da base de dados consolidada, em que cada linha corresponde a um respondente:
Para viabilizar a realização de testes estatísticos válidos a partir da base de dados acima e responder à pergunta de pesquisa, na etapa do tratamento dos dados, os analistas devem:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas
|
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas de Saúde |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Obras Públicas |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Tecnologia da Informação |
Q3593735
Estatística
Em um teste, para os valores de um determinado parâmetro, de
uma hipótese nula H0 versus uma hipótese alternativa H1, o nível
de significância fixado indica:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas
|
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas de Saúde |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Obras Públicas |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Tecnologia da Informação |
Q3593734
Estatística
Numa dada população, 10% dos eleitores votaram num certo
candidato C a prefeito nas últimas eleições.
Se quatro desses eleitores foram aleatoriamente sorteados (com reposição), a probabilidade de que exatamente dois tenham votado em C (e dois não tenham nele votado) é aproximadamente igual a:
Se quatro desses eleitores foram aleatoriamente sorteados (com reposição), a probabilidade de que exatamente dois tenham votado em C (e dois não tenham nele votado) é aproximadamente igual a:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas
|
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Contas Públicas de Saúde |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Obras Públicas |
FGV - 2025 - TCE-PE - Auditor de Controle Externo – Tecnologia da Informação |
Q3593733
Estatística
Observe a amostra de dados contábeis (em milhares de reais) a seguir.
132 202 185 214 240 186 183 180 203 204 138 98 194 295 103 222 104
A mediana desse conjunto de dados, em milhares de reais, é igual a:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Analista de Controle Externo - Contas Públicas
|
FGV - 2025 - TCE-PE - Analista de Controle Externo - Obras Públicas |
FGV - 2025 - TCE-PE - Analista de Controle Externo - Tecnologia da Informação |
Q3593193
Estatística
Em um estudo técnico baseado em um grande conjunto de dados,
foram empregadas técnicas de aprendizado de máquina e análise
estatística para identificar padrões e outras informações.
Entretanto, os resultados foram questionados, pois, embora tenha
sido demonstrada existência de correlação, não foi estabelecida
relação de causalidade.
Considerando as melhores práticas e os desafios da mineração de dados, analise as afirmativas a seguir.
I. Foram gerados insights a partir de dados válidos e confiáveis.
II. A equipe executora contava com especialistas com experiência em programação Python, R e SQL.
III. A metodologia empregada atendeu a literatura e outros estudos técnicos semelhantes, descrevendo que foi selecionada apenas uma base de informações de dados não estruturados atualizada para realizar o processamento, em virtude de limitações de capacidade computacional, dos custos envolvidos e dos testes que demonstraram a introdução de incerteza ao se realizar uma coleta ampla e profunda de conjuntos de dados.
Está correto o que se afirma em:
Considerando as melhores práticas e os desafios da mineração de dados, analise as afirmativas a seguir.
I. Foram gerados insights a partir de dados válidos e confiáveis.
II. A equipe executora contava com especialistas com experiência em programação Python, R e SQL.
III. A metodologia empregada atendeu a literatura e outros estudos técnicos semelhantes, descrevendo que foi selecionada apenas uma base de informações de dados não estruturados atualizada para realizar o processamento, em virtude de limitações de capacidade computacional, dos custos envolvidos e dos testes que demonstraram a introdução de incerteza ao se realizar uma coleta ampla e profunda de conjuntos de dados.
Está correto o que se afirma em:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Analista de Controle Externo - Contas Públicas
|
FGV - 2025 - TCE-PE - Analista de Controle Externo - Obras Públicas |
FGV - 2025 - TCE-PE - Analista de Controle Externo - Tecnologia da Informação |
Q3593185
Estatística
Para se estimar a média de uma população suposta como
normalmente distribuída com variância conhecida e igual a 16,
uma amostra aleatória simples de tamanho 100 foi obtida e
resultou numa média amostral igual a 30.
Dado que o 97,5 percentil da distribuição normal padrão é igual a 1,96, um intervalo de 95% de confiança para μ será dado aproximadamente por:
Dado que o 97,5 percentil da distribuição normal padrão é igual a 1,96, um intervalo de 95% de confiança para μ será dado aproximadamente por:
Ano: 2025
Banca:
FGV
Órgão:
TCE-PE
Provas:
FGV - 2025 - TCE-PE - Analista de Controle Externo - Contas Públicas
|
FGV - 2025 - TCE-PE - Analista de Controle Externo - Obras Públicas |
FGV - 2025 - TCE-PE - Analista de Controle Externo - Tecnologia da Informação |
Q3593183
Estatística
Uma amostra atual de 40 idades resulta numa média de 32 anos,
numa mediana de 39 anos e num desvio padrão de 4 anos.
Daqui a 8 anos, os novos valores da média, da mediana e do desvio padrão das idades desse mesmo grupo de pessoas serão, respectivamente, iguais a:
Daqui a 8 anos, os novos valores da média, da mediana e do desvio padrão das idades desse mesmo grupo de pessoas serão, respectivamente, iguais a:
Q3593054
Estatística
Com relação à detecção de anomalias, avalie as afirmativas a
seguir e assinale (V) para verdadeira e (F) para falsa.
( ) A detecção de valor discrepante corresponde à identificação de uma observação, evento ou ponto de dados que representa um espaço vetorial multidimensional convexo e fixo, tornando-o inconsistente em relação ao resto do conjunto de dados.
( ) O aprendizado de máquina e a inteligência artificial são empregados para identificar automaticamente alterações inesperadas no comportamento normal de um conjunto de dados.
( ) As anomalias costumam ser raras e as características do comportamento normal podem ser complexas e dinâmicas, o que torna a detecção desafiadora.
As afirmativas são, respectivamente,
( ) A detecção de valor discrepante corresponde à identificação de uma observação, evento ou ponto de dados que representa um espaço vetorial multidimensional convexo e fixo, tornando-o inconsistente em relação ao resto do conjunto de dados.
( ) O aprendizado de máquina e a inteligência artificial são empregados para identificar automaticamente alterações inesperadas no comportamento normal de um conjunto de dados.
( ) As anomalias costumam ser raras e as características do comportamento normal podem ser complexas e dinâmicas, o que torna a detecção desafiadora.
As afirmativas são, respectivamente,
Q3592324
Estatística
O faturamento, em milhões, de uma indústria, ao longo do
primeiro semestre é analisado pelo contador da empresa. Após
conferir e analisar todos os valores, foi gerada a planilha abaixo.
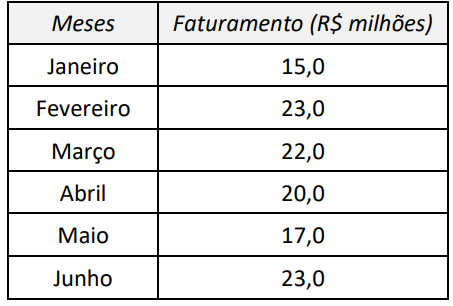
O desvio padrão, em milhões, do faturamento da empresa, ao longo do ano, é
O desvio padrão, em milhões, do faturamento da empresa, ao longo do ano, é