Questões de Concurso
Sobre estatística para fgv
Foram encontradas 1.519 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Q3883534
Estatística
Uma variável aleatória X tem média desconhecida μ e variância
igual a 25.
Se uma amostra aleatória simples de tamanho n = 225 for obtida, a probabilidade de que o valor da média amostral não se afaste do de μ por mais do que 0,5 é aproximadamente igual a
Se uma amostra aleatória simples de tamanho n = 225 for obtida, a probabilidade de que o valor da média amostral não se afaste do de μ por mais do que 0,5 é aproximadamente igual a
Q3883533
Estatística
Uma variável aleatória X tem função de densidade de
probabilidade dada por
f(x) = |1 – x|, 0 < x < 2, f(x) = 0, nos demais casos.
O valor esperado de X é igual a
f(x) = |1 – x|, 0 < x < 2, f(x) = 0, nos demais casos.
O valor esperado de X é igual a
Q3883532
Estatística
Se a função geradora de momentos de uma variável aleatória X é dada por
mX(t) = λ/(λ - t), para t < λ
então a média de X é igual a
Q3883531
Estatística
Em relação à mediana m de uma variável aleatória X, avalie as
afirmativas a seguir.
I. A mediana m de uma variável aleatória X é o quantil 0,5. II. A mediana m de uma variável aleatória X é qualquer número que satisfaz P[X ≤ m] ≤ ½ e P[X ≥ m] ≥ ½.

Está correto o que se afirma em
I. A mediana m de uma variável aleatória X é o quantil 0,5. II. A mediana m de uma variável aleatória X é qualquer número que satisfaz P[X ≤ m] ≤ ½ e P[X ≥ m] ≥ ½.
Está correto o que se afirma em
Q3883530
Estatística
Se X é uma variável aleatória e g(.) é uma função não negativa com
domínio real, então, para todo k > 0,
Q3883529
Estatística
X é uma variável aleatória contínua com função de densidade de
probabilidade dada por
f(x) = kx3 , 0 ≤ x ≤ 1, f(x) = 0, nos demais casos,
sendo k uma constante.
O valor esperado de 3X2 + 1 é igual a
f(x) = kx3 , 0 ≤ x ≤ 1, f(x) = 0, nos demais casos,
sendo k uma constante.
O valor esperado de 3X2 + 1 é igual a
Q3883528
Estatística
Texto associado
Dois dados honestos I e II serão lançados e os números obtidos em
suas faces superiores serão registrados. Sejam:
X: o número obtido no dado I.
Y: o valor absoluto da diferença entre os dois números obtidos.
A média de Y vale
Q3883527
Estatística
Texto associado
Dois dados honestos I e II serão lançados e os números obtidos em
suas faces superiores serão registrados. Sejam:
X: o número obtido no dado I.
Y: o valor absoluto da diferença entre os dois números obtidos.
A média e a variância de X são, respectivamente,
Q3883526
Estatística
A e B são dois eventos tais que P[A] = 0,7 e P[B] = 0,2.
Os valores mínimo e máximo de P[AUB] são, respectivamente,
Os valores mínimo e máximo de P[AUB] são, respectivamente,
Q3883524
Estatística
Dois eventos A e B são tais que P[A] = 0,6 e P[B] = 0,5. A probabilidade condicional P[B|A] é igual a 0,4. Assim, a probabilidade condicional P[A|B] é igual a
Ano: 2026
Banca:
FGV
Órgão:
AL-RO
Prova:
FGV - 2026 - AL-RO - Consultor Legislativo (Assessoramento em Orçamento) |
Q3882019
Estatística
Uma comissão de avaliação de políticas públicas analisa a
continuidade de um programa de auxílio emergencial para uma
população específica. A legislação vigente determina que o
benefício deve ser descontinuado caso haja evidência estatística
de que a renda média mensal da população beneficiada superou
R$ 800,00, indicando uma recuperação econômica.
Para verificar tal condição, uma auditoria realizou um levantamento com uma amostra aleatória simples de 100 beneficiários, apurando uma renda média amostral de R$ 824,00. Sabe-se, por estudos demográficos prévios, que o desvio padrão populacional da renda é de R$ 120,00.
Considerando um nível de significância de 1% para o teste de hipótese unilateral à direita, e sabendo que o valor crítico da distribuição Normal Padrão para este nível é de aproximadamente 2,33, assinale a alternativa que apresenta a conclusão estatística correta e a recomendação coerente a ser dada pela auditoria à comissão.
Para verificar tal condição, uma auditoria realizou um levantamento com uma amostra aleatória simples de 100 beneficiários, apurando uma renda média amostral de R$ 824,00. Sabe-se, por estudos demográficos prévios, que o desvio padrão populacional da renda é de R$ 120,00.
Considerando um nível de significância de 1% para o teste de hipótese unilateral à direita, e sabendo que o valor crítico da distribuição Normal Padrão para este nível é de aproximadamente 2,33, assinale a alternativa que apresenta a conclusão estatística correta e a recomendação coerente a ser dada pela auditoria à comissão.
Ano: 2026
Banca:
FGV
Órgão:
AL-RO
Prova:
FGV - 2026 - AL-RO - Consultor Legislativo (Assessoramento em Orçamento) |
Q3882018
Estatística
Uma consultoria legislativa utiliza um modelo estatístico para
prever o impacto fiscal de emendas parlamentares. O modelo
assume que a divergência entre o valor previsto e o valor real
segue uma Distribuição Normal com média igual a zero.
Sabe-se que a probabilidade de a divergência se situar no intervalo entre a média e um valor positivo k é de aproximadamente 34%.
A probabilidade de a divergência apresentar um valor estritamente superior a 2k é de, aproximadamente,
Sabe-se que a probabilidade de a divergência se situar no intervalo entre a média e um valor positivo k é de aproximadamente 34%.
A probabilidade de a divergência apresentar um valor estritamente superior a 2k é de, aproximadamente,
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880241
Estatística
A biblioteca Maptplotlib (versão 3.10) do Python permite que os
cientistas de dados elaborem sofisticadas visualizações de análise
de dados.
Selecione a visualização gráfica do tipo Boxplot.
Selecione a visualização gráfica do tipo Boxplot.
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880238
Estatística
Uma matriz de confusão resume o desempenho da classificação
realizada por um classificador em relação a alguns dados de
teste. Um caso especial da matriz de confusão é
frequentemente utilizado com apenas duas classes, uma
designada como classe positiva e a outra classe negativa. Nesse
contexto, as quatro células da matriz são designadas como
verdadeiros positivos (VP), falsos positivos (FP), verdadeiros
negativos (VN) e falsos negativos (FN), conforme indicado na
tabela a seguir
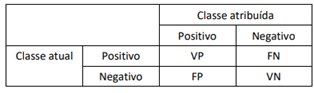
Com relação ao cálculo das medidas de desempenho, analise as afirmativas a seguir.
I. A medida da especificidade (também conhecido por Taxa de verdadeiros negativos) pode ser alcançada através da fórmula: Especificidade = VN / (VN + FP).
II. A medida da sensibilidade (também conhecido por Taxa de verdadeiros positivos ou Recall) pode ser alcançada através da fórmula: Recall = VP / (VP + FN).
III. O valor preditivo positivo (também conhecido como Precisão) pode ser alcançada através da fórmula: Precisão = VN / (VN + FN)
IV. Por fim, O valor preditivo negativo (VPN) pode ser alcançada através da fórmula: VPN = VP / (VP + FP).
Está correto o que se afirma em
Com relação ao cálculo das medidas de desempenho, analise as afirmativas a seguir.
I. A medida da especificidade (também conhecido por Taxa de verdadeiros negativos) pode ser alcançada através da fórmula: Especificidade = VN / (VN + FP).
II. A medida da sensibilidade (também conhecido por Taxa de verdadeiros positivos ou Recall) pode ser alcançada através da fórmula: Recall = VP / (VP + FN).
III. O valor preditivo positivo (também conhecido como Precisão) pode ser alcançada através da fórmula: Precisão = VN / (VN + FN)
IV. Por fim, O valor preditivo negativo (VPN) pode ser alcançada através da fórmula: VPN = VP / (VP + FP).
Está correto o que se afirma em
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880230
Estatística
Martinha, uma analista da ALEGO, desenvolveu o programa
Python (versão 3) que utiliza as bibliotecas numpy (2.0.2) e scikitlearn (versão 1.6.1) para realizar análise discriminante linear.
Analise o programa a seguir.

O resultado impresso é igual a
O resultado impresso é igual a
Ano: 2026
Banca:
FGV
Órgão:
AL-GO
Prova:
FGV - 2026 - AL-GO - Analista Legislativo - Analista de Ciência de Dados |
Q3880221
Estatística
Ciência de Dados (CD) utiliza conjuntos de dados para tentar
entender e resolver problemas do mundo real. Com relação aos
fundamentos essenciais da CD, analise as afirmativas a seguir.
I. Os dados figuram como o elemento central. O objetivo é extrair desses toda informação possível para que se possam tomar decisões e antecipar resultados de maneira precisa.
II. Não é campo de conhecimento alheio às outras ciências. Ao contrário, que se trata de uma combinação de instrumentos fornecidos por diversos campos do saber, com destaque para a Estatística e a Ciência da Computação.
III. CD lida exclusivamente com a análise de dados estruturados, como planilhas e bancos de dados SQL, focando apenas em visualizações básicas e relatórios descritivos.
Está correto o que se afirma em
I. Os dados figuram como o elemento central. O objetivo é extrair desses toda informação possível para que se possam tomar decisões e antecipar resultados de maneira precisa.
II. Não é campo de conhecimento alheio às outras ciências. Ao contrário, que se trata de uma combinação de instrumentos fornecidos por diversos campos do saber, com destaque para a Estatística e a Ciência da Computação.
III. CD lida exclusivamente com a análise de dados estruturados, como planilhas e bancos de dados SQL, focando apenas em visualizações básicas e relatórios descritivos.
Está correto o que se afirma em
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Arquiteto de Dados |
Q3878697
Estatística
Um tribunal deseja prever o tempo de tramitação (em dias) de
processos de uma determinada classe, desde a distribuição até a
sentença em 1ª instância. Um cientista de dados ajustou um
modelo de regressão usando variáveis como tipo de ação, vara,
quantidade de partes e histórico de movimentações, e avaliou o
modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças
absolutas dividida pelo número de observações, ou:
Erro =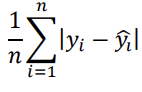 ´
´
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Erro =
´ obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Arquiteto de Dados |
Q3878694
Estatística
O desempenho de modelos de aprendizado de máquina está
intrinsecamente relacionado ao equilíbrio entre viés e variância.
Modelos com alto viés tendem a simplificar excessivamente o
problema, resultando em subajuste (underfitting), enquanto
modelos com alta variância podem capturar ruído nos dados de
treinamento, levando ao sobreajuste (overfitting). Para mitigar
esses problemas, diversas técnicas de regularização podem ser
empregadas, ajustando a complexidade do modelo e melhorando
sua capacidade de generalização.
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Considerando os conceitos de compensação viés-variância, sobreajuste, subajuste e técnicas de regularização, é correto afirmar que:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874749
Estatística
Uma equipe de análise de risco de um tribunal implanta modelos de classificação para identificar processos com alta probabilidade de resultado desfavorável para a administração, trabalhando com bases historicamente desbalanceadas (poucos casos críticos em relação aos não críticos). Na fase de avaliação, discute-se o uso de validação cruzada, métricas baseadas em limiar de decisão e curvas de desempenho.
Com base nas boas práticas de avaliação de modelos de aprendizado de máquina, inclusive em cenários com classes desbalanceadas, analise as afirmativas a seguir, considerando (V) para a(s) afirmativa(s) verdadeira(s) e (F) para a(s) falsa(s).
( ) Na validação cruzada k-fold estratificada, cada partição de treino e teste preserva aproximadamente a mesma proporção de classes do conjunto original, o que contribui para estimativas de desempenho mais estáveis em problemas com desbalanceamento de classes.
( ) Curvas ROC e a métrica AUC-ROC são tipicamente mais informativas do que curvas precision-recall em cenários com classes fortemente desbalanceadas, justamente porque destacam com maior sensibilidade o comportamento do classificador em relação à classe minoritária.
( ) A métrica F1-score corresponde ao dobro do produto entre precisão (precision) e sensibilidade (recall) dividido pela soma de ambos, de modo que valores muito discrepantes entre precisão e recall tendem a produzir um F1-score relativamente baixo.
( ) Ao diminuir o limiar de decisão de um classificador binário (por exemplo, de 0,7 para 0,3), a precisão tende a aumentar, pois mais exemplos positivos são corretamente identificados como tal, ainda que isso geralmente ocorra às custas de uma redução no recall.
A sequência correta é:
Com base nas boas práticas de avaliação de modelos de aprendizado de máquina, inclusive em cenários com classes desbalanceadas, analise as afirmativas a seguir, considerando (V) para a(s) afirmativa(s) verdadeira(s) e (F) para a(s) falsa(s).
( ) Na validação cruzada k-fold estratificada, cada partição de treino e teste preserva aproximadamente a mesma proporção de classes do conjunto original, o que contribui para estimativas de desempenho mais estáveis em problemas com desbalanceamento de classes.
( ) Curvas ROC e a métrica AUC-ROC são tipicamente mais informativas do que curvas precision-recall em cenários com classes fortemente desbalanceadas, justamente porque destacam com maior sensibilidade o comportamento do classificador em relação à classe minoritária.
( ) A métrica F1-score corresponde ao dobro do produto entre precisão (precision) e sensibilidade (recall) dividido pela soma de ambos, de modo que valores muito discrepantes entre precisão e recall tendem a produzir um F1-score relativamente baixo.
( ) Ao diminuir o limiar de decisão de um classificador binário (por exemplo, de 0,7 para 0,3), a precisão tende a aumentar, pois mais exemplos positivos são corretamente identificados como tal, ainda que isso geralmente ocorra às custas de uma redução no recall.
A sequência correta é:
Ano: 2026
Banca:
FGV
Órgão:
TJ-RJ
Prova:
FGV - 2026 - TJ-RJ - Analista Judiciário - Tecnologia da Informação - Analista de Inteligência Artificial |
Q3874747
Estatística
Um tribunal deseja prever o tempo de tramitação (em dias) de processos de uma determinada classe, desde a distribuição até a sentença em 1ª instância. Um cientista de dados ajustou um modelo de regressão usando variáveis como tipo de ação, vara, quantidade de partes e histórico de movimentações, e avaliou o modelo no conjunto de teste.
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
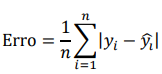
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é:
Como métrica principal, ele calculou a soma das diferenças absolutas dividida pelo número de observações, ou:
obtendo Erro = 18, que foi interpretado como: “em média, o modelo erra em 18 dias o tempo de tramitação dos processos”. A métrica utilizada pelo cientista de dados é: