Questões de Concurso
Sobre estatística para fgv
Foram encontradas 1.519 questões
Resolva questões gratuitamente!
Junte-se a mais de 4 milhões de concurseiros!
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Grupo Economia e Estatística (Analista Administrativo - Contabilidade; Estatística; Economia) |
Q3248827
Estatística
O resultado do lançamento de um dadinho honesto pode ser 1, 2,
3, 4, 5 ou 6, sendo todos igualmente prováveis.
Se um dadinho honesto for lançado três vezes, a probabilidade de que a soma dos três resultados seja maior do que 16 é aproximadamente igual a
Se um dadinho honesto for lançado três vezes, a probabilidade de que a soma dos três resultados seja maior do que 16 é aproximadamente igual a
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Grupo Economia e Estatística (Analista Administrativo - Contabilidade; Estatística; Economia) |
Q3248826
Estatística
A função de probabilidade de uma variável aleatória discreta X é
dada por

O valor da função de distribuição acumulada de X quando x = 1,5 é igual a
O valor da função de distribuição acumulada de X quando x = 1,5 é igual a
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Grupo Economia e Estatística (Analista Administrativo - Contabilidade; Estatística; Economia) |
Q3248825
Estatística
A mediana de 20 idades de um grupo de amigos é 37. Se duas
novas pessoas se juntarem ao grupo, um com 40 anos, outra com
25, então a nova mediana será igual a
Ano: 2024
Banca:
FGV
Órgão:
EBSERH
Prova:
FGV - 2024 - EBSERH - Grupo Economia e Estatística (Analista Administrativo - Contabilidade; Estatística; Economia) |
Q3248824
Estatística
A tabela a seguir mostra os dados de cinco amostras de notas de
jurados acerca dos desfiles de seis escolas de samba da cidade X
numa determinada noite:

Dos 5 jurados, o que deu notas com menor desvio padrão foi o
Dos 5 jurados, o que deu notas com menor desvio padrão foi o
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Prova:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Tarde) |
Q3158081
Estatística
Suponha que foi aplicado um modelo de regressão linear simples
em um conjunto de n pares de valores da forma (x_i,y_i),i=1,...,n.
Sejam ▁x e ▁y as médias dos valores x_i e y_i, i=1,...,n,
respectivamente. Sabe-se que:
(i) ▁x=0,25 (ii) ▁y=0,75 (iii) ∑_(i=1)^n▒〖(x_i-▁x)(y_i-▁y)〗=12 (iv) ∑_(i=1)^n▒〖(x_i-▁x )^2 〗=2
Considerando os dados acima, a equação resultante da regressão linear é dada por
(i) ▁x=0,25 (ii) ▁y=0,75 (iii) ∑_(i=1)^n▒〖(x_i-▁x)(y_i-▁y)〗=12 (iv) ∑_(i=1)^n▒〖(x_i-▁x )^2 〗=2
Considerando os dados acima, a equação resultante da regressão linear é dada por
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Prova:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Tarde) |
Q3158080
Estatística
Acerca dos modelos preditivos probabilísticos para aprendizado de
máquina, analise os itens a seguir.
I. O uso de algoritmos baseados no teorema de Bayes pode ser aplicado quando os dados disponíveis estão incompletos ou imprecisos.
II. O classificador naive Bayes assume a hipótese de que os valores dos atributos de um exemplo são dependentes de sua classe.
III. As redes bayesianas utilizam o conceito de independência condicional entre variáveis.
Está correto o que se afirma em
I. O uso de algoritmos baseados no teorema de Bayes pode ser aplicado quando os dados disponíveis estão incompletos ou imprecisos.
II. O classificador naive Bayes assume a hipótese de que os valores dos atributos de um exemplo são dependentes de sua classe.
III. As redes bayesianas utilizam o conceito de independência condicional entre variáveis.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Prova:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Tarde) |
Q3158069
Estatística
Considere dois conjuntos de dados distintos, denotados por C1 e
C2, ambos do mesmo tamanho, isto é, com a mesma quantidade
de valores. A cada conjunto foi aplicado o mesmo método de
regressão linear. O erro médio quadrático obtido para C1 foi
menor do que para C2. Com base no exposto, analise as
afirmativas a seguir, e assinale V para a afirmativa verdadeira e F
para a falsa.
( ) O erro médio quadrático é uma métrica típica de erro em problemas de regressão cujo valor varia entre 0 e 1.
( ) Pode-se afirmar que o conjunto de dados C1 está melhor ajustado ao modelo do que o conjunto de dados C2.
( ) Pode-se afirmar que para melhorar o ajuste do conjunto de dados C2 é preciso aumentar seu tamanho.
As afirmativas são, respectivamente,
( ) O erro médio quadrático é uma métrica típica de erro em problemas de regressão cujo valor varia entre 0 e 1.
( ) Pode-se afirmar que o conjunto de dados C1 está melhor ajustado ao modelo do que o conjunto de dados C2.
( ) Pode-se afirmar que para melhorar o ajuste do conjunto de dados C2 é preciso aumentar seu tamanho.
As afirmativas são, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Provas:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Gestão Tributária (Manhã)
|
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Manhã) |
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Direito/Processo Tributário (Manhã) |
Q3157880
Estatística
Uma variável aleatória contínua X tem distribuição normal com média ? = 8. A probabilidade de que X seja menor que 10,5 é P[X<10,5]=89,4% e a probabilidade de que X esteja entre 7,5 e 8,5 é P[7,5<X<8,5]=19,8%.
Com base nessas informações, é correto afirmar que P[5,5<X<7,5] é
Com base nessas informações, é correto afirmar que P[5,5<X<7,5] é
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Provas:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Gestão Tributária (Manhã)
|
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Manhã) |
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Direito/Processo Tributário (Manhã) |
Q3157877
Estatística
Uma variável aleatória discreta X tem distribuição binomial com
parâmetros n e p, em que n é o número de ensaios de Bernoulli
independentes, todos com a mesma probabilidade p de sucesso.
O valor esperado e a variância de X dependem do valor da probabilidade p.
Se o valor máximo da variância de X é 2,5, é correto afirmar que n é igual a
O valor esperado e a variância de X dependem do valor da probabilidade p.
Se o valor máximo da variância de X é 2,5, é correto afirmar que n é igual a
Ano: 2024
Banca:
FGV
Órgão:
Prefeitura de Cuiabá - MT
Provas:
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Gestão Tributária (Manhã)
|
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Tecnologia da Informação (Manhã) |
FGV - 2024 - Prefeitura de Cuiabá - MT - Auditor Fiscal Tributário da Receita Municipal - Direito/Processo Tributário (Manhã) |
Q3157874
Estatística
Ao todo, 12 pacientes de um hospital foram submetidos a um
mesmo tratamento contra certa moléstia. O tempo de duração do
tratamento, em semanas, para cada paciente foi registrado e esses
dados foram consolidados na Tabela de Frequências a seguir.

Foi então usada a regra de descarte que considera outlier qualquer observação fora do intervalo (Q1-1,5D; Q3+1,5D) na qual Q1 e Q3 são os 1º e 3º quartis e D é a distância interquartil.
Com base nessas informações, todo valor atípico (outlier) foi descartado.
Após esse descarte, foi calculada a média aritmética dos tempos de duração do tratamento e o resultado encontrado foi
Foi então usada a regra de descarte que considera outlier qualquer observação fora do intervalo (Q1-1,5D; Q3+1,5D) na qual Q1 e Q3 são os 1º e 3º quartis e D é a distância interquartil.
Com base nessas informações, todo valor atípico (outlier) foi descartado.
Após esse descarte, foi calculada a média aritmética dos tempos de duração do tratamento e o resultado encontrado foi
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090101
Estatística
Os outliers são dados que se distinguem significativamente dos
demais no conjunto. Um outlier é um valor que se desvia
substancialmente da normalidade e pode causar anomalias nos
resultados gerados por algoritmos e sistemas de análise.
A seguir, é apresentado um gráfico de boxplot, que ilustra os retornos mensais das ações de uma empresa
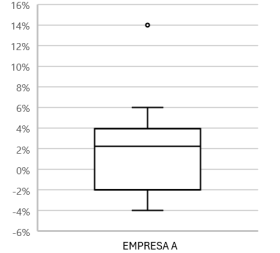
Nesse contexto, analise as seguintes afirmações.
I. Outliers nunca devem ser removidos, pois sempre carregam informações importantes e não têm a capacidade de distorcer resultados ou enviesar modelos de análise.
II. A partir da análise visual do boxplot apresentado, é possível afirmar que o valor 14% é um outlier, pois ele está visivelmente distante do corpo principal dos dados, fora do intervalo interquartil (IQR).
III. Para a detecção de outliers, além da identificação visual, é possível utilizar métodos estatísticos e técnicas baseadas em aprendizado de máquina.
Está correto o que se afirma em
A seguir, é apresentado um gráfico de boxplot, que ilustra os retornos mensais das ações de uma empresa
Nesse contexto, analise as seguintes afirmações.
I. Outliers nunca devem ser removidos, pois sempre carregam informações importantes e não têm a capacidade de distorcer resultados ou enviesar modelos de análise.
II. A partir da análise visual do boxplot apresentado, é possível afirmar que o valor 14% é um outlier, pois ele está visivelmente distante do corpo principal dos dados, fora do intervalo interquartil (IQR).
III. Para a detecção de outliers, além da identificação visual, é possível utilizar métodos estatísticos e técnicas baseadas em aprendizado de máquina.
Está correto o que se afirma em
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090093
Estatística
Um time de futebol disputa um campeonato em que joga um
número igual de partidas em seu estádio e fora de seu estádio. As
probabilidades de ganhar, empatar ou perder uma partida quando
joga em seu estádio são, respectivamente, 1/2, 1/5 e 3/10. As
probabilidades de ganhar, empatar ou perder uma partida quando
joga fora de seu estádio são, respectivamente, 1/5, 1/5 e 3/5.
Um torcedor desinformado, ao chegar em sua aula sobre inferência bayesiana, ouviu de seus amigos que o referido time havia perdido a última partida que disputou. Sem obter nenhuma informação adicional, o torcedor resolveu calcular as probabilidades (a posteriori) de o time haver jogado a última partida em seu estádio ou fora de seu estádio.
As probabilidades calculadas corretamente pelo torcedor foram, respectivamente,
Um torcedor desinformado, ao chegar em sua aula sobre inferência bayesiana, ouviu de seus amigos que o referido time havia perdido a última partida que disputou. Sem obter nenhuma informação adicional, o torcedor resolveu calcular as probabilidades (a posteriori) de o time haver jogado a última partida em seu estádio ou fora de seu estádio.
As probabilidades calculadas corretamente pelo torcedor foram, respectivamente,
Ano: 2024
Banca:
FGV
Órgão:
TJ-RR
Prova:
FGV - 2024 - TJ-RR - Analista Judiciário - Ciência de Dados e Analytics |
Q3090092
Estatística
Uma das etapas essenciais do tratamento e processamento de
dados, em especial para estatística e para o aprendizado de
máquina, consiste em sua organização e identificação. Uma maneira
de organizar os dados de um conjunto consiste em classificá-los.
Relacione cada uma das variáveis a seguir, constantes de um conjunto de dados sobre um grupo de pessoas, com a classificação a ela mais adequada.
1. Grau de instrução (ex.: superior)
2. Número de filhos
3. Estado de Procedência (ex.: Minas Gerais)
4. Massa corporal
( ) Quantitativa Contínua ( ) Quantitativa Discreta ( ) Qualitativa Nominal ( ) Qualitativa Ordinal
A relação correta, na ordem apresentada, é
Relacione cada uma das variáveis a seguir, constantes de um conjunto de dados sobre um grupo de pessoas, com a classificação a ela mais adequada.
1. Grau de instrução (ex.: superior)
2. Número de filhos
3. Estado de Procedência (ex.: Minas Gerais)
4. Massa corporal
( ) Quantitativa Contínua ( ) Quantitativa Discreta ( ) Qualitativa Nominal ( ) Qualitativa Ordinal
A relação correta, na ordem apresentada, é
Q3088076
Estatística
Se U e V são variáveis aleatórias independentes com distribuições
respectivas qui-quadrado com m e n graus de liberdade, então a
variável X = nU/mV tem distribuição
Q3088075
Estatística
Uma vila tem 50 moradores, dos quais 20 são do sexo masculino. Se
5 desses moradores serão aleatoriamente sorteados, sem reposição,
a probabilidade de que 3 sejam do sexo masculino é
aproximadamente igual a
Q3088071
Estatística
No estudo de um modelo de regressão linear simples, avalie se os
principais problemas que podem ser detectados por intermédio da
análise dos resíduos incluem, entre outros:
I. Não-linearidade da relação entre as variáveis. II. Não normalidade dos erros. III. Variância não-constante dos erros (heterocedasticidade). IV. Correlação entre os erros. V. Presença de outliers ou observações atípicas.
Estão corretos os problemas
I. Não-linearidade da relação entre as variáveis. II. Não normalidade dos erros. III. Variância não-constante dos erros (heterocedasticidade). IV. Correlação entre os erros. V. Presença de outliers ou observações atípicas.
Estão corretos os problemas
Q3088070
Estatística
Considere que uma amostra aleatória simples de tamanho 100 de
uma densidade N(μ, 25) será obtida para testar H0: μ ≤ 10
versus H1: μ ≤ 10. Será usado como critério de decisão rejeitar
H0 se 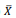 > 10,82.
> 10,82.
A função de potência desse teste quando μ = 11 é aproximadamente igual a
> 10,82. A função de potência desse teste quando μ = 11 é aproximadamente igual a
Q3088069
Estatística
Numa regressão múltipla y = Xβ + e, y é um vetor nx1, β é um vetor
px1, e é um vetor nx1 e X é uma matriz nxp. Nesse caso, se X’ é a
matriz transposta de X, então os estimadores de mínimos quadrados
dos parâmetros β serão dados pelas soluções de
Q3088068
Estatística
Suponha que se deseje ajustar, pelo método dos mínimos quadrados, uma reta Y = a + bX a um conjunto de pares de observações (x1, y1), (x2, y2),..., (xn, yn).
Nesse caso, se e 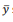 são as médias amostrais dos x’s e dos y’s, a
solução é dada por
são as médias amostrais dos x’s e dos y’s, a
solução é dada por
Q3088067
Estatística
Há casos em que devemos pensar numa população dividida em
subpopulações ou estratos, sendo conveniente supor que a variável
de interesse se comporta de modo bem diferente de estrato em
estrato, mas com comportamento razoavelmente homogêneo
dentro de cada estrato.
Em tais casos, o sorteio dos elementos da amostra deve levar em conta a existência dos estratos. Para evitar problemas com seleções mal feitas pode-se adotar a amostragem estratificada.
Avalie se as seguintes afirmativas acerca da amostragem estratificada são verdadeiras (V) ou falsas (F).
( ) A amostragem estratificada especifica quantos elementos da amostra serão retirados em cada estrato. Frequentemente consideram-se três tipos de amostragem estratificada: uniforme, proporcional e ótima.
( ) Na amostragem estratificada uniforme, um mesmo número de elementos é sorteado em cada estrato.
( ) Na amostragem proporcional, o número de elementos sorteados em cada estrato é proporcional ao número de elementos existentes no estrato.
( ) A amostragem estratificada ótima seleciona, em cada estrato, um número de elementos proporcional ao número de elementos do estrato e também à variação da variável de interesse no estrato, medida pelo seu desvio padrão.
As afirmativas são, respectivamente,
Em tais casos, o sorteio dos elementos da amostra deve levar em conta a existência dos estratos. Para evitar problemas com seleções mal feitas pode-se adotar a amostragem estratificada.
Avalie se as seguintes afirmativas acerca da amostragem estratificada são verdadeiras (V) ou falsas (F).
( ) A amostragem estratificada especifica quantos elementos da amostra serão retirados em cada estrato. Frequentemente consideram-se três tipos de amostragem estratificada: uniforme, proporcional e ótima.
( ) Na amostragem estratificada uniforme, um mesmo número de elementos é sorteado em cada estrato.
( ) Na amostragem proporcional, o número de elementos sorteados em cada estrato é proporcional ao número de elementos existentes no estrato.
( ) A amostragem estratificada ótima seleciona, em cada estrato, um número de elementos proporcional ao número de elementos do estrato e também à variação da variável de interesse no estrato, medida pelo seu desvio padrão.
As afirmativas são, respectivamente,