Questões de Concurso Público DPE-PR 2024 para Analista da Defensoria Pública - Estatística
Foram encontradas 2 questões
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Estatística |
Q2353399
Estatística
Considere a realização de uma pesquisa exploratória para estudar o comportamento de indivíduos em relação ao hábito de
se socializarem. Vinte e uma pessoas responderam a um conjunto de sete variáveis relacionadas ao tema. A escala de medida
foi de 1 a 5, onde 1 representava a discordância total e 5 representava concordância total quanto à afirmação expressa na
variável. Foi realizada uma análise fatorial ortogonal com extração das cargas fatoriais pelo método de componentes principais
baseado na matriz de correlação das sete variáveis disponíveis.
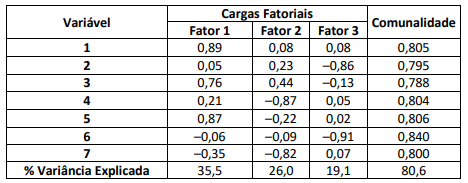
De acordo com os resultados parciais fornecidos na tabela, assinale a afirmativa correta.
De acordo com os resultados parciais fornecidos na tabela, assinale a afirmativa correta.
Ano: 2024
Banca:
Instituto Consulplan
Órgão:
DPE-PR
Prova:
Instituto Consulplan - 2024 - DPE-PR - Analista da Defensoria Pública - Estatística |
Q2353403
Estatística
A respeito da análise de conglomerados, analise as afirmativas a seguir.
I. Na execução do algoritmo K-means, é possível que a alocação de observações aos clusters não mude entre duas iterações sucessivas.
II. O uso de duas medidas de similaridade distintas pode produzir dois dendrogramas diferentes ao se aplicar um algoritmo de agrupamento aglomerativo para o mesmo conjunto de dados.
III. Em uma análise envolvendo duas variáveis, considere que, após a primeira iteração do algoritmo K-Means aplicado para agrupar sete observações em três clusters, C1, C2 e C3, obteve-se a seguinte configuração: C1={(2,2), (4,4), (6,6)}; C2={(0,4), (4,0)} e C3={(5,5), (9,9)}. Então, os respectivos centroides que darão seguimento à próxima iteração serão C1=(4,4), C2=(2,2) e C3=(7,7).
Está correto o que se afirma em
I. Na execução do algoritmo K-means, é possível que a alocação de observações aos clusters não mude entre duas iterações sucessivas.
II. O uso de duas medidas de similaridade distintas pode produzir dois dendrogramas diferentes ao se aplicar um algoritmo de agrupamento aglomerativo para o mesmo conjunto de dados.
III. Em uma análise envolvendo duas variáveis, considere que, após a primeira iteração do algoritmo K-Means aplicado para agrupar sete observações em três clusters, C1, C2 e C3, obteve-se a seguinte configuração: C1={(2,2), (4,4), (6,6)}; C2={(0,4), (4,0)} e C3={(5,5), (9,9)}. Então, os respectivos centroides que darão seguimento à próxima iteração serão C1=(4,4), C2=(2,2) e C3=(7,7).
Está correto o que se afirma em